-
-
[原创]UTF-8编码数据拆分
-
发表于:
2017-9-25 12:57
2718
-
不讨论判断是不是utf-8编码,本身就是utf-8编码,编码规则如下
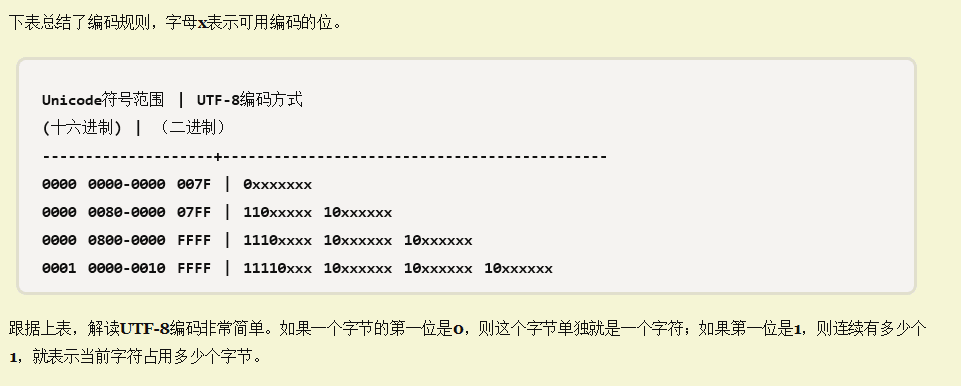
规则很简单,只是判断第一个字节的前几位,每一位判断也可以,最多只需判断四位,给出另一种方法获取每个字符编码的长度
public static int getByteCount(byte data) {
int tmp = ~data & 0xff;
return 8 - Integer.toBinaryString(tmp).length();
}
数据取反后,前面的1都变成0,后面的0就变成了1。取反后的第一个1也就是原始数据第一个0的位置,0前面都是1。一个字节8位减去取反后二进制字符长度,就是前面1的个数。
下面是拆分一个字符串的结果
https://bbs.pediy.com/thread-215245.htm
这篇文章之前处理数据是通过判断中文字符utf-8编码范围,如果有特殊字符,处理会失败,改成拆分utf-8编码,数据处理就很完美了。
[培训]内核驱动高级班,冲击BAT一流互联网大厂工作,每周日13:00-18:00直播授课


