-
-
[原创] 语音识别对抗攻击研究笔记(上)
-
发表于: 2022-4-1 12:39 12299
-

大家好, 我是星舆车联网实验室李四伟。团队成员在漏洞挖掘, 硬件逆向与AI大数据方面有着丰富经验, 连续在GeekPwn等破解赛事中斩获奖项。发现众多产品高危漏洞,并获相关厂商致谢。团队研究成果多次发表于DEFCON等国内外顶级安全会议, 成功入选2021特斯拉漏洞名人堂。星舆实验室拥有特斯拉等诸多靶车供研究使用, 期待更多志同道合的小伙伴加入我们。
本文是算法安全研究笔记系列的第一篇文章,本系列主要分享记录算法安全研究过程中的各类方法及成果,同时解析原理和实现,最终构成一个完整的算法安全研究知识体系。从实践的角度来看算法安全主要包含算法自身的安全以及工程安全两部分。本系列将尽量结合两个方面来对算法安全进行综合研究。
语音识别对抗样本研究分为上下两篇,目标是希望能够构建语音识别的对抗样本数据,在正常的语音或者音乐中插入隐藏的命令,使得人听到的是正常的语音或者音乐,机器识别成唤醒或者进行操作的命令,进而执行相应的操作。例如在车内播放一段人听着正常的音乐,然后车辆的语音助手被唤醒,然后执行打开车门的操作。本篇为上篇,主要阐述对抗样本实现的方法,同时以图像识别为例展开到语音识别,简述构建对抗样本的过程。同时也是对声纹系列文章的补充。
随着大数据,人工智能等领域的飞速发展,深度学习和各个领域相结合,不断的应用于各种场景中,例如自动驾驶,人脸识别,语音识别等等。虽然深度学习有着较好的性能,但是本身的鲁棒性存在缺陷,容易被精心设计好的对抗样本攻击。对抗样本是对原始样本添加精心设计好的扰动,导致模型给出错误的输出。下图是一个对抗样本的经典示例:
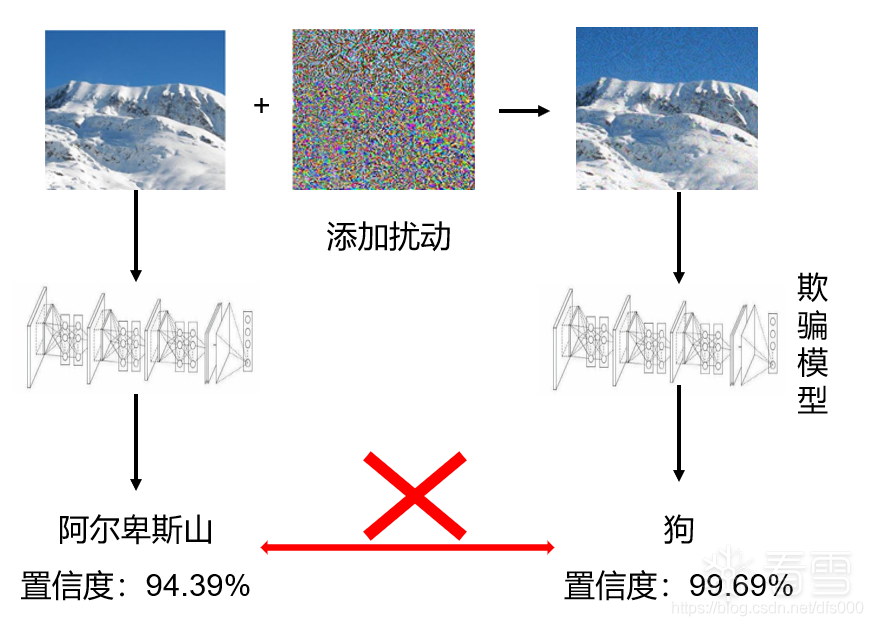
- 生成对抗样本思路
整体思路
对于一个正常的输入样本x,我们通过模型推理输出的结果为f(x),生成对抗样本的目标对x添加微小的扰动,得到一个对抗样本x,使得模型输出结果f(x)≠f(x)。同时通过限制x*与x之间的差异,使得扰动尽量不可察觉。
其实通过对图像本身进行旋转,灰度处理,添加形变,叠加图像等等方法也能够影响到模型的推理结果。最开始的对抗性研究中,也有人通过对图像添加各种处理来验证模型的鲁棒性,分析影响识别结果的引述,例如将飞机的机翼合成到汽车上,早期的模型就存在一定概率将合成后的汽车识别成飞机。我们主要还是讨论在约束条件下的对抗样本,即lp范数或者其他约束下的扰动,一般为不易察觉的扰动,通过添加这些约束限制生成的对抗样本与原始样本的差异。
优化目标
普通模型优化的目标是最小化损失函数,与普通模型训练不同,生成对抗样本的优化目标是最大化模型的损失函数J(x, y),来让输出的结果错误。同时加入lp范数(一般为无穷范数或者2范数)作为生成扰动的约束。
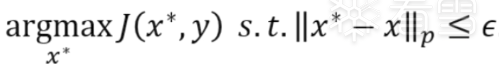
对于有目标攻击的对抗样本,不单需要让模型输出的结果错误,还需要输出特定的结果,而不是任意错误的结果。这种情况下就需要在优化目标中添加
argminJ(x, y*)这一项。
常用方法
通常我们在模型训练过程中都是输入样本不变,通过不断地迭代调整模型的参数,使得模型的输出结果不断的接近目标结果。而对抗样本的生成我们可以理解为整个模型的参数不变,通过训练调整输入样本,使得模型的输出结果远离目标结果。因而很多用于正常训练的方法也可以被应用到对抗样本生成中。
一些常用的对抗样本生成方法如下:
FGSM(Fast Gradient Sign Method)
BIM/I-FGSM
Optimization-based
简单的对抗样本实现
上述主要对对抗样本的理论方法进行简述,下面将以实践方式,来展示生成对抗样本的一个过程。图像领域的对抗样本生成更加简单直接,将以一个分类的算法为例,展示对抗样本生成的整个过程,先对整个生成过程有大致的概念后,再推广到语音对抗样本生成。
目标算法
Inception v3
类型
图像分类算法,输入图像数据,对输出图像进行分类,总类别1000
实现目标
生成对抗样本,使模型将车(特斯拉)识别成猫(波斯猫)。
实现
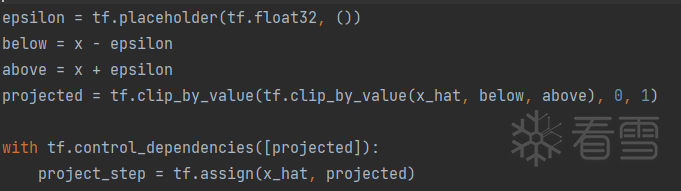
① 设置输出图像,设置为变量,可被训练的
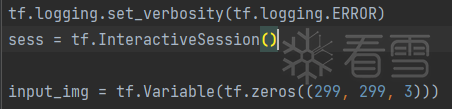
② 加载inception v3模型,加载权重


③ logits为模型输出,labels为想要将对抗样本错误分类的目标分类标签,定义交叉熵损失函数。通过梯度下降来降低损失,最大化目标类概率。
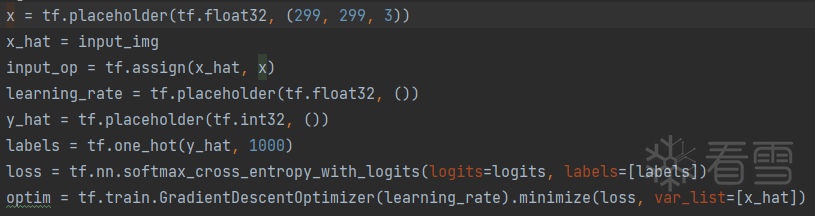
④ 使用l∞范数约束扰动,对抗样本和原始样本视觉相似,同时生成的图像限制在[0,1]之间,因为inception v3输入为归一化的图像数据(除255),因而图像的有效范围为[0,1]之间。不同模型输入是不同的,例如在pytorch中,Resnet18的输入需要进行transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])处理,这种情况下,可以将Normalize 作为norm_layer层加到网络中model =nn.Sequential(norm_layer,models.resnet18(pretrained=True))
 。
。
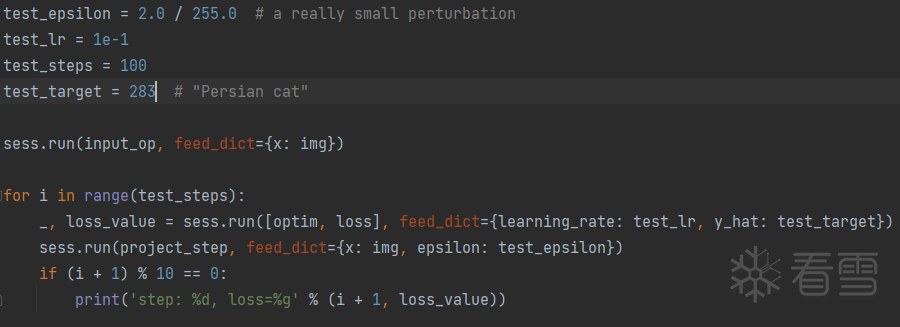
⑤ 开始训练,使用PGD算法生成对抗样本,迭代100步
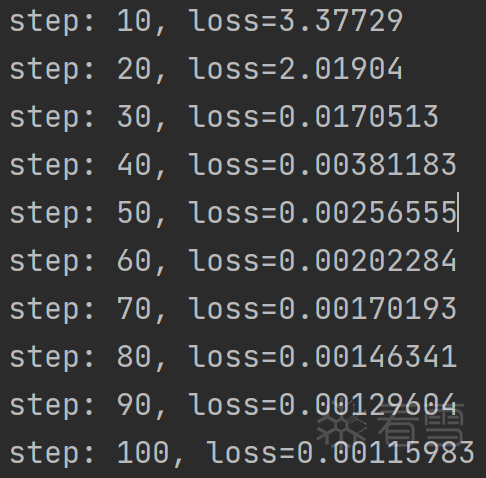
⑥ 训练过程
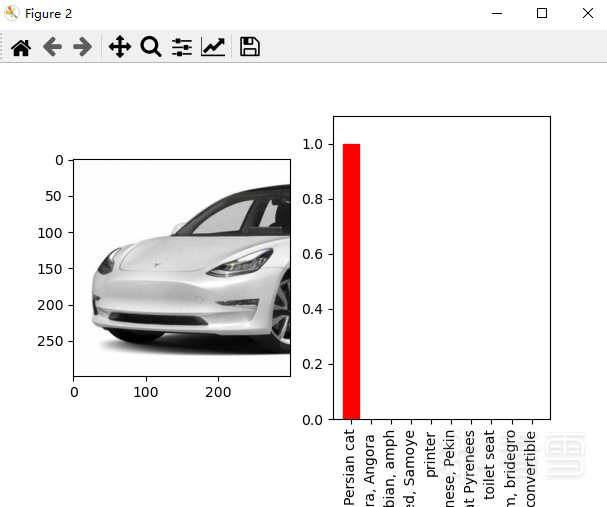
⑦ 最终结果,车的图片被以100%置信度分类为波斯猫
.语音对抗样本构建
主要参考Nicholas Carlini David Wagner的Audio Adversarial Examples: Targeted Attacks on Speech-to-Text论文及实现
语音不同于图像,在语音识别方面构建有针对性的对抗性例子是困难的.对语音的对抗样本攻击。对于语音识别系统,我们可以将语音输入表示为n维的向量,大部分神经网络都是接受一个输入,并产生在所有标签的一个概率分布,但是语音到文本系统的情况下,存在指数级可能的标签,使得在不可能列举所有可能的短语(会使得网络的复杂度,规模,计算量无限膨胀),语音识别系统通常使用循环神经网络(RNN)来将音频波形映射到单个字符上的概率分布序列,而不是整个短语。因为输入的是说话的人的音频样本,以及未对齐的转录句子,其中每个单词在音频样本中的确切位置是未知的,当输入和输出序列之间的比对未知时,使用CTC损失函数来进行训练。同时使用l无穷范数来约束生成的扰动失真,不同于图像,使用的像素的变化,语音使用我们以分贝(分贝)为单位测量失真:衡量音频样本相对响度的对数指标:
将分贝与原始的波形进行比较,来衡量失真,值比较小的话,表示较小的失真。这是一种衡量失真的方法,当这一值足够小,生成的扰动足够小,人耳就无法轻易察觉这种扰动。
基于以上结论构建语音对抗样
• 目标算法
Deepspeech,版本:0.4.1,由计算MFC的预处理层+使用LSTM的RNN组成,MFC预处理层可以很好地降低输入数据的维度。
• 类型
目标为语音识别算法,输入语音数据,识别语音转文本。攻击方法为一个白盒攻击,在已知模型详细的结构,参数的情况进行对抗样本训练。
• 实现目标
①生成对抗样本的源:
对抗样本生成的目标有Mel滤波器系数(MFC)和原始的音频数据,原始音频相对来说更加复杂,但更有实际应用价值,因而选择原始音频数据作为对抗样本生成的数据源。
②目标
在原始语音中添加对抗扰动,添加隐藏的,听不见的语音命令,合成新的音频,不修改现有的人耳听到的音频内容。
③方法
给定任意音频x,构建几乎听不见的扰动δ,使得x+δ被识别为任何所需的给定文本内容y,我们的任务是构造一个音频波形x'=x+δ,使得x和x'听起来相似,但使得f(x')=y。
• 具体实现过程
1 | 基本流程是和图像对抗样本生成时一致的,差别在于损失函数,使用的对抗样本生成算法上。 |
①初始化参数
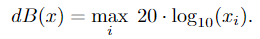
②定义输入,并添加随机噪声,保证裁剪数据时不破坏内容
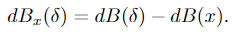
③定义损失函数,使用CTC损失函数
④设置adam优化器来进行梯度下降
⑥进行梯度下降,迭代优化
⑦存储生成的结果
⑧最终识别结果(建议实际听一下两个语音)
对抗样本的音频 c56K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2T1K9h3I4A6j5X3W2D9K9g2)9J5k6h3y4G2L8g2)9J5c8X3q4#2k6r3W2G2i4K6u0r3j5i4f1J5z5e0l9^5z5o6R3$3i4K6y4r3N6s2W2H3k6g2)9K6c8o6p5`.
原始的音频1e3K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2T1K9h3I4A6j5X3W2D9K9g2)9J5k6h3y4G2L8g2)9J5c8X3q4#2k6r3W2G2i4K6u0r3j5i4f1J5z5e0l9^5z5e0t1&6i4K6y4r3N6s2W2H3k6g2)9K6c8o6p5`.
识别结果

对抗样本

总结
本篇简要介绍了对抗样生成的过程,从图像对抗样本生成展开到了语音对抗样本生成,整体对对抗样本生成有基础的概念,最后展示了使用白盒攻击的方法攻击语音识别模型的效果。下篇中将对语音对抗样本生成的原理进行深入分析,并将白盒攻击拓展到黑盒攻击,使用更加有实践意义的方法,通过黑盒对抗样本攻击的方法,攻击一些线上的语音识别系统,验证对抗攻击的效果。
References
• bcaK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6T1L8r3!0Y4i4K6u0W2j5%4y4V1L8W2)9J5k6h3&6W2N6q4)9J5c8Y4W2Z5K9h3I4&6x3U0l9H3z5q4)9J5c8X3q4J5N6r3W2U0L8r3g2Q4x3V1k6V1k6i4c8S2K9h3I4K6i4K6u0r3z5o6l9J5y4U0t1K6x3U0p5`.
• 5eeK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6T1L8r3!0Y4i4K6u0W2j5%4y4V1L8W2)9J5k6h3&6W2N6q4)9J5c8W2y4%4k6h3g2@1f1$3g2$3k6h3&6Q4y4h3k6Q4x3V1k6S2M7Y4c8A6j5$3I4W2i4K6u0r3k6r3g2@1j5h3W2D9M7#2)9J5c8U0p5H3x3K6f1&6y4e0p5^5x3l9`.`.
• d43K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2S2L8X3W2K6K9r3q4@1K9r3q4D9P5h3g2Q4x3X3g2U0L8$3#2Q4x3V1j5J5x3o6p5%4i4K6u0r3x3o6N6Q4x3V1j5J5y4g2)9J5c8Y4y4&6L8Y4c8Z5k6i4y4A6P5X3W2F1k6#2)9J5k6r3q4V1N6X3g2J5M7$3q4J5K9h3q4D9i4K6u0V1k6i4S2S2L8i4m8D9k6i4y4Q4x3V1k6Q4x3@1k6K6M7r3#2Q4x3@1c8S2x3X3x3@1k6g2)9J5k6e0p5I4x3e0f1K6z5e0b7H3i4K6u0W2j5X3I4G2k6$3y4G2L8Y4b7I4y4o6V1#2z5o6y4Q4x3X3f1J5z5q4)9J5k6e0c8S2j5U0x3$3x3r3x3H3g2%4V1J5P5W2R3$3
• Audio Adversarial Examples: Targeted Attacks on Speech-to-Text.Nicholas Carlini,David Wagner.
• f03K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6U0j5i4u0D9K9h3&6A6i4K6u0r3j5i4g2V1K9h3!0Q4y4h3k6S2k6s2k6W2M7Y4y4S2M7X3W2S2L8q4)9#2k6X3g2^5j5h3#2H3L8r3g2K6i4K6u0W2k6$3W2@1
欢迎加入星球一起学习探讨
[培训]内核驱动高级班,冲击BAT一流互联网大厂工作,每周日13:00-18:00直播授课
赞赏
|
|
|---|---|
|
|
|

