难得今天上网,发现没有人讨论~

反而钱老师给了一个精华~

为了对得起这个精华,我就顺便贴下我的实现代码和效果图吧~(代码太挫……)
关于代码的分离部分:
//************************************************************************
// 函数名: Lex_Split
// 权 限: public
// 返回值: list<TCHAR*>* 返回一个字符串链表
// 参 数: IN TCHAR * pszRegular
// 参 数: IN TCHAR * pszSource
// 说 明: 从指定的字符串中分离出各种子串
// 合 格:
//************************************************************************
list<TCHAR*>* Lex_Split(IN const TCHAR* pszRegular, IN const TCHAR* pszSource)
{
int ntmpLen = 0;
int nCount = 0; // 用来统计匹配的数量作为返回值
match_results result; // 匹配结果
list<TCHAR*> *pszResultList = new list<TCHAR*>;
REGEX_FLAGS emRegEx*** = GLOBAL | ALLBACKREFS | NOCASE | SINGLELINE;
rpattern pat((LPCTSTR)pszRegular, emRegEx***); //正则模式及设置
int iGroups = pat.cgroups();
match_results::backref_type br = pat.match(pszSource, result );
if (pszRegular == NULL || pszSource == NULL || br.matched == FALSE)
{
return NULL;
}
for( int i=0; i < result.cbackrefs(); i++ )
{
ntmpLen = _tcslen(result.backref(i).str().c_str());
if( i%iGroups == 0 && ntmpLen > 0)
{
nCount++;
TCHAR *pszResult = new TCHAR[ntmpLen+1];
ZeroMemory(pszResult, ntmpLen+1);
_tcscpy(pszResult, result.backref(i).str().c_str());
pszResultList->push_back(pszResult);
}
}
return pszResultList;
}
关于根据token获取值的部分:
//************************************************************************
// 函数名: GetRegTokenValue
// 权 限: public
// 返回值: DWORD
// 参 数: IN CONTEXT * tagpContext
// 参 数: TCHAR * pszRegToken
// 说 明: 获取 分离出的各种token代表的值
// 合 格:
//************************************************************************
DWORD GetRegTokenValue(IN CONTEXT *tagpContext, TCHAR *pszRegToken)
{
for (int i = 0; i < 8; i++)
{
if (_tcsicmp(st_RegInfo[i].pszString, pszRegToken) != 0)
{
continue;
}
switch(st_RegInfo[i].tagType.e)
{
case REG_TYPE::REG_TYPE_EAX:
return tagpContext->Eax;
case REG_TYPE::REG_TYPE_EBX:
return tagpContext->Ebx;
case REG_TYPE::REG_TYPE_ECX:
return tagpContext->Ecx;
case REG_TYPE::REG_TYPE_EDX:
return tagpContext->Edx;
case REG_TYPE::REG_TYPE_ESP:
return tagpContext->Esp;
case REG_TYPE::REG_TYPE_EBP:
return tagpContext->Ebp;
case REG_TYPE::REG_TYPE_ESI:
return tagpContext->Esi;
case REG_TYPE::REG_TYPE_EDI:
return tagpContext->Edi;
default:
;
}
}
return -1;
}
//************************************************************************
// 函数名: GetRegTokenValue
// 权 限: public
// 返回值: DWORD
// 参 数: TCHAR * pszCstToken
// 说 明: 获取 分离出的 常量 的值
// 合 格:
//************************************************************************
DWORD GetCstTokenValue(TCHAR *pszCstToken)
{
DWORD dwResult = 0;
if (pszCstToken == NULL)
{
return 0;
}
_stscanf(pszCstToken, _T("%x"), &dwResult);
return dwResult;
}
整体上的模拟运算的流程如下:
//************************************************************************
// 函数名: CalcSimulator
// 权 限: public
// 返回值: DWORD
// 参 数: IN CONTEXT * tagpContext
// 参 数: IN list<TCHAR * > * pTokenList
// 说 明: 表达式计算
// 合 格:
//************************************************************************
DWORD CalcSimulator(IN CONTEXT *tagpContext, IN list<TCHAR*>* pTokenList)
{
int nCount = 0;
DWORD dwResult = 0; // 前一个操作数
DWORD dwCurNum = 0;
if (tagpContext == NULL || pTokenList == NULL)
{
return -1;
}
if (pTokenList->size() <= 1)
{
return -1;
}
OPERATE_STATE em_OperReg;
OPERATE_STATE em_OperCst;
OPERATE_STATE em_OperSign;
OPERATE_STATE em_OperStart;
OPERATE_STATE em_OperEnd;
em_OperReg.e = OPERATE_STATE::STATE_OPER_REG;
em_OperCst.e = OPERATE_STATE::STATE_CONST_NUM;
em_OperSign.e = OPERATE_STATE::STATE_SIGN_TOKEN;
em_OperStart.e= OPERATE_STATE::STATE_SIGN_START;
em_OperEnd.e = OPERATE_STATE::STATE_SIGN_END;
pTokenList = CalcMulti(tagpContext, pTokenList); // 先处理乘法
if (pTokenList == (list<TCHAR*>*)-1)
{
return -1;
}
nCount = pTokenList->size();
list<TCHAR*>::iterator it = pTokenList->begin();
for ( int i = 0 ; i < nCount ; i++ )
{
TCHAR *pResultBuf = NULL;
pResultBuf = *it;
if (pResultBuf == NULL)
{
continue;
}
if (Is(em_OperStart, pResultBuf))
{
// 清空栈内容
while (!g_WaitForCalcStack.empty())
{
g_WaitForCalcStack.pop();
}
}
if (Is(em_OperEnd, pResultBuf))
{
// 处理完成,开始计算栈中的数据
int nSize = g_WaitForCalcStack.size();
for (int i = 0; i < nSize; i ++)
{
dwResult += g_WaitForCalcStack.top();
g_WaitForCalcStack.pop();
}
break;
}
if (Is(em_OperReg, pResultBuf))
{
// 如果是寄存器,就保存寄存器中的内容
g_WaitForCalcStack.push(GetRegTokenValue(tagpContext, pResultBuf));
}
if (Is(em_OperCst, pResultBuf))
{
// 如果是立即数,就保存其值
g_WaitForCalcStack.push(GetCstTokenValue(pResultBuf));
}
if (Is(em_OperSign, pResultBuf))
{
if (_tcsicmp(pResultBuf, _T("-")) == 0)
{
it++;
//如果是减法,则需要将后面的数据取补保存
pResultBuf = *it;
if (Is(em_OperReg, pResultBuf))
{
// 如果是寄存器,就保存寄存器中的内容
dwCurNum = GetRegTokenValue(tagpContext, pResultBuf);
g_WaitForCalcStack.push(dwCurNum);
}
if (Is(em_OperCst, pResultBuf))
{
// 如果是立即数,就保存其值
dwCurNum = GetCstTokenValue(pResultBuf);
dwCurNum = (~dwCurNum)+1; // 求补码
g_WaitForCalcStack.push(dwCurNum);
}
}
}
it++;
}
return dwResult;
由于乘法在我们当前的环境下优先级最高,所以我将乘法的计算过程分离出去了:
// 先计算乘法
static list<TCHAR*>* CalcMulti(IN CONTEXT *tagpContext, IN list<TCHAR*>* pTokenList)
{
if (tagpContext == NULL || pTokenList == NULL)
{
return NULL;
}
TCHAR *pPreToken = NULL;
TCHAR *pResultBuf = NULL;
DWORD dwPreNum = 0; // 前一个操作数
DWORD dwNextNum = 0; // 后一个操作数
int nCount = 0;
OPERATE_STATE em_OperReg;
OPERATE_STATE em_OperCst;
OPERATE_STATE em_OperSign;
OPERATE_STATE em_OperStart;
OPERATE_STATE em_OperEnd;
em_OperReg.e = OPERATE_STATE::STATE_OPER_REG;
em_OperCst.e = OPERATE_STATE::STATE_CONST_NUM;
em_OperSign.e = OPERATE_STATE::STATE_SIGN_TOKEN;
em_OperStart.e= OPERATE_STATE::STATE_SIGN_START;
em_OperEnd.e = OPERATE_STATE::STATE_SIGN_END;
list<TCHAR*>* pResultList = new list<TCHAR*>;
list<TCHAR*>::iterator it = pTokenList->begin();
nCount = pTokenList->size();
for ( int i = 0 ; i < nCount; i++ ) // 多循环了一次,需要看看
{
pResultBuf = *it;
if (pResultBuf == NULL)
{
continue;
}
if (_tcsicmp(pResultBuf, _T("*")) != 0)
{
pResultList->push_back(pResultBuf);
}
if (i > 0)
{
it--;
pPreToken = *it;
it++;
}
if (pPreToken != NULL && _tcsicmp(pPreToken, _T("*")) == 0)
{
// 如果前一个是*也不保存当前的
pResultList->pop_back();
}
if (Is(em_OperSign, pResultBuf) && _tcsicmp(pResultBuf, _T("*")) == 0)
{
pResultList->pop_back();
// 先取出前一个操作数
it--;
pResultBuf = *it;
if (Is(em_OperReg, pResultBuf))
{
// 如果是寄存器,就保存寄存器中的内容
dwPreNum = GetRegTokenValue(tagpContext, pResultBuf);
}
if (Is(em_OperCst, pResultBuf))
{
// 如果是立即数,就保存其值
dwPreNum = GetCstTokenValue(pResultBuf);
}
// 取出后一个操作数
it++;
it++;
pResultBuf = *it;
if (Is(em_OperReg, pResultBuf))
{
// 如果是寄存器,就保存寄存器中的内容
dwNextNum = GetRegTokenValue(tagpContext, pResultBuf);
}
if (Is(em_OperCst, pResultBuf))
{
// 如果是立即数,就保存其值
dwNextNum = GetCstTokenValue(pResultBuf);
}
TCHAR* pNewNum = new TCHAR[4];
ZeroMemory(pNewNum, sizeof(TCHAR)*4);
_stprintf(pNewNum, _T("%d"), dwPreNum*dwNextNum);
pResultList->push_back(pNewNum);
it--;
}
it++;
}
pTokenList->clear();
if (pTokenList)
{
delete pTokenList;
pTokenList = NULL;
}
pTokenList = pResultList;
return pResultList;
}
主要的代码就这些了,也用不着我多说废话了,下面贴一下效果图:
先贴个简单的立即数寻址的:
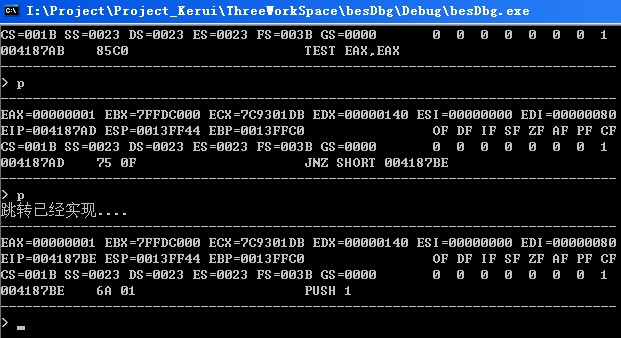
CALL reg形式的:
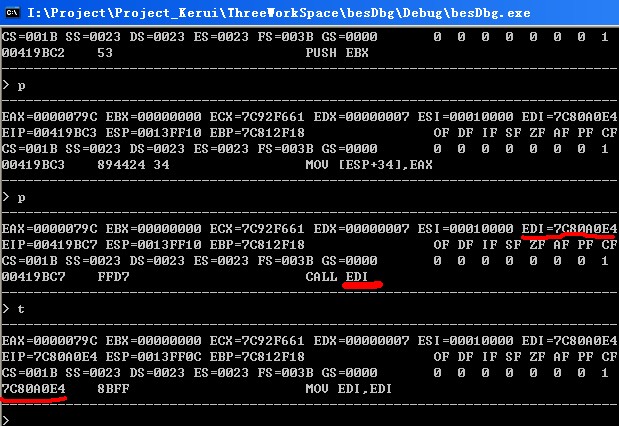
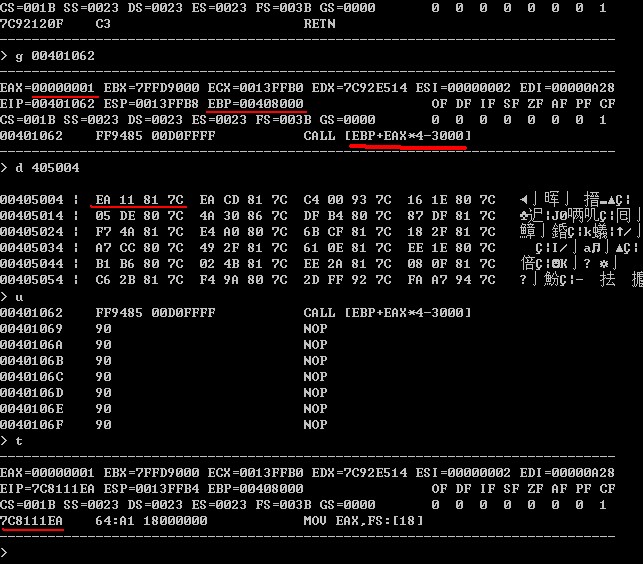
再看下 call [addr]这种形式的:
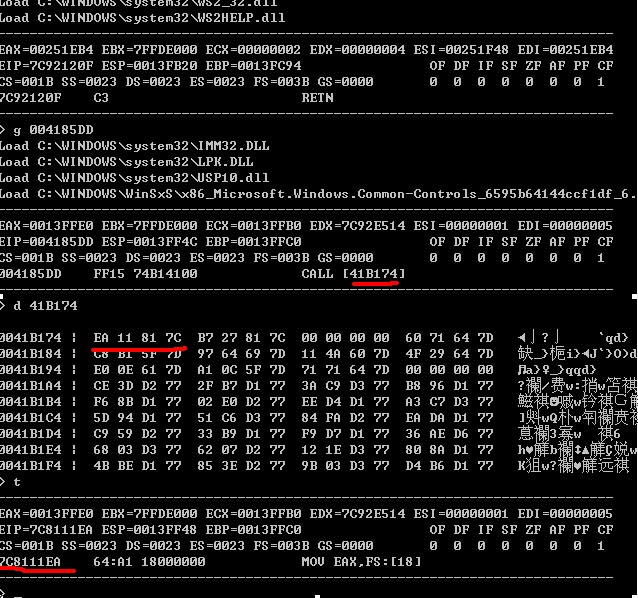
再看下return的效果:
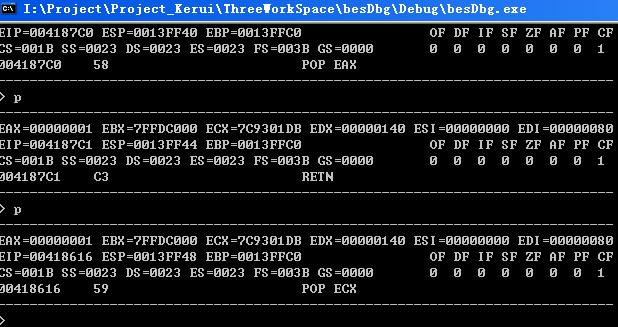
最后来个超级复杂的那种(我自己修改代码构造的测试程序):
就到这里吧,希望各位师兄能多提点意见,也希望本文能对其它朋友有所帮助。




