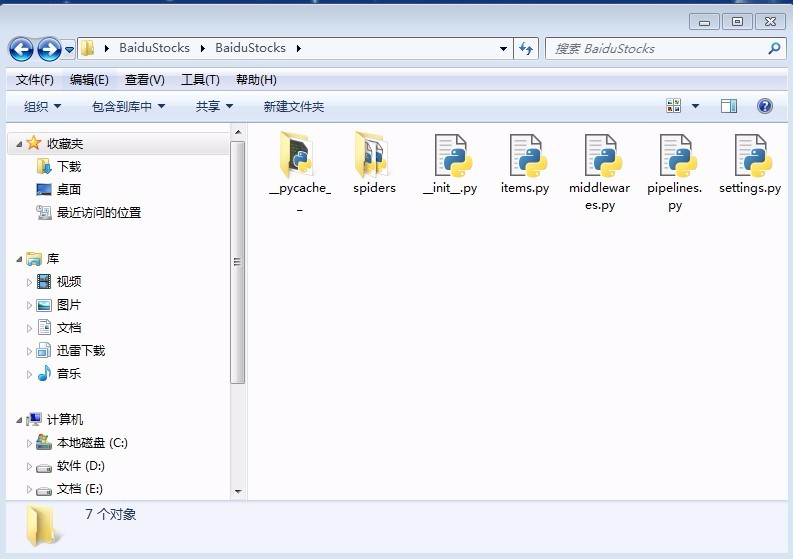
#stocks.py
# -*- coding: utf-8 -*-
import scrapy
import re
class StocksSpider(scrapy.Spider):
name = 'stocks'
start_urls = ['ed3K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4q4#2L8%4c8W2i4K6u0W2k6h3q4K6N6r3#2G2L8X3g2&6i4K6u0W2j5$3!0E0i4K6u0r3M7%4c8G2j5$3E0D9K9i4y4@1i4K6u0W2K9s2c8E0L8q4)9J5y4#2)9#2c8l9`.`.
def parse(self, response):
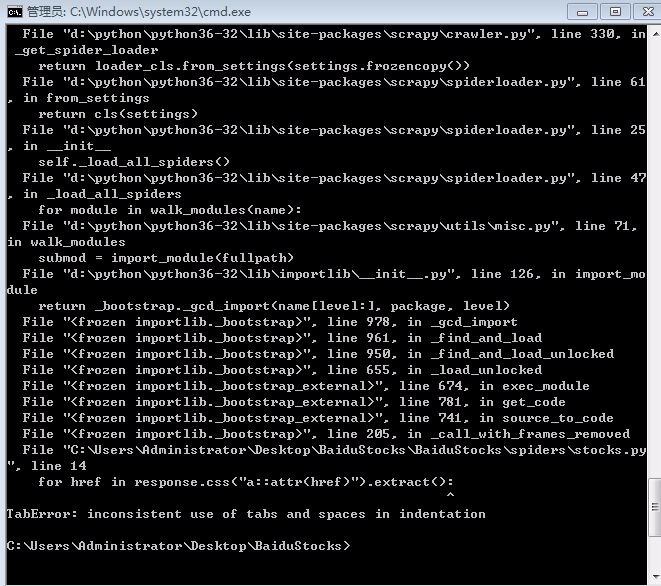
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"[s][hz]\d{6}",href)[0]
url = '012K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4N6i4m8A6j5h3!0Q4x3X3g2T1j5h3W2V1N6g2)9J5k6h3y4G2L8g2)9J5c8Y4y4@1L8$3y4C8i4K6t1%4i4K6t1$3L8X3u0K6M7q4)9K6b7W2)9J5b7W2)9J5y4X3&6T1M7%4m8Q4x3@1u0K6N6r3!0U0K9#2)9J5y4X3&6T1M7%4m8Q4x3@1u0Q4x3V1u0Q4x3U0k6F1j5Y4y4H3i4K6y4n7i4K6t1%4i4K6u0W2K9s2c8E0L8q4)9J5y4H3`.`.
yield scrapy.Resquest(url, callback = self.parse_stock)
except:
continue
def parse_stock(self, response):
infoDict = {}
stockInfo = response.css('.stock-bets')
name = stockInfo.css('.bets-name').extract()[0]
keyList = stockInfo.css('dt').extract()
for i in range(len(keyList)):
key = re.findall(r'>.*</dt>',keyList[i])[0][1:-5]
try:
val = re.findall(r'\d+\.?.*</dd>',valueList[i])[0][0:-5]
except:
val = '--'
infoDict[key] = val
infoDict.update(
{'股票名称':re.findall('\s.*\(',name)[0].split()[0]+\
re.findall('\>.*<',name)[0][1:-i]})
yield infoDict
#settings.py
#settings.py
# -*- coding: utf-8 -*-
# Scrapy settings for BaiduStocks project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# 103K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3c8G2j5#2)9J5k6i4y4U0M7X3q4H3P5g2)9J5k6h3!0J5k6#2)9J5c8X3g2F1i4K6u0r3L8r3q4@1k6i4y4@1i4K6u0r3N6r3!0H3K9h3y4K6i4K6u0r3M7$3g2@1N6r3W2F1k6%4y4Q4x3X3g2Z5N6r3#2D9
# 09bK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4y4U0M7X3q4H3P5g2)9J5k6i4u0W2j5h3c8@1K9r3g2V1L8$3y4K6i4K6u0W2L8%4u0Y4i4K6u0r3k6h3&6Q4x3V1k6D9j5i4c8W2M7%4c8Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6V1L8%4N6F1L8r3!0S2k6r3g2J5i4K6u0V1L8h3W2V1k6r3I4W2N6$3q4J5k6g2)9J5k6h3S2@1L8h3H3`.
# 59cK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4y4U0M7X3q4H3P5g2)9J5k6i4u0W2j5h3c8@1K9r3g2V1L8$3y4K6i4K6u0W2L8%4u0Y4i4K6u0r3k6h3&6Q4x3V1k6D9j5i4c8W2M7%4c8Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6K6M7r3W2V1k6i4u0Q4x3X3c8E0K9h3c8V1L8r3g2%4j5i4u0W2i4K6u0W2K9s2c8E0L8l9`.`.
BOT_NAME = 'BaiduStocks'
SPIDER_MODULES = ['BaiduStocks.spiders']
NEWSPIDER_MODULE = 'BaiduStocks.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'BaiduStocks (+f2dK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4N6%4N6#2)9J5k6i4W2G2N6i4u0V1L8$3#2S2K9h3&6Q4x3X3g2U0L8$3#2Q4x3U0W2Q4x3U0M7`.
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See 68aK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4y4U0M7X3q4H3P5g2)9J5k6i4u0W2j5h3c8@1K9r3g2V1L8$3y4K6i4K6u0W2L8%4u0Y4i4K6u0r3k6h3&6Q4x3V1k6D9j5i4c8W2M7%4c8Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6K6k6i4c8@1K9h3&6Y4M7#2)9J5k6h3S2@1L8h3I4Q4x3U0y4V1L8%4N6F1L8r3!0S2k6q4)9J5k6r3c8W2L8r3q4&6
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
#DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# Enable or disable spider middlewares
# See 05dK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4y4U0M7X3q4H3P5g2)9J5k6i4u0W2j5h3c8@1K9r3g2V1L8$3y4K6i4K6u0W2L8%4u0Y4i4K6u0r3k6h3&6Q4x3V1k6D9j5i4c8W2M7%4c8Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6K6M7r3W2V1k6i4u0Q4x3X3c8E0K9h3c8V1L8r3g2%4j5i4u0W2i4K6u0W2K9s2c8E0L8l9`.`.
#SPIDER_MIDDLEWARES = {
# 'BaiduStocks.middlewares.BaidustocksSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See 193K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4y4U0M7X3q4H3P5g2)9J5k6i4u0W2j5h3c8@1K9r3g2V1L8$3y4K6i4K6u0W2L8%4u0Y4i4K6u0r3k6h3&6Q4x3V1k6D9j5i4c8W2M7%4c8Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6V1L8%4N6F1L8r3!0S2k6r3g2J5i4K6u0V1L8h3W2V1k6r3I4W2N6$3q4J5k6g2)9J5k6h3S2@1L8h3H3`.
#DOWNLOADER_MIDDLEWARES = {
# 'BaiduStocks.middlewares.MyCustomDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See 8d9K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4y4U0M7X3q4H3P5g2)9J5k6i4u0W2j5h3c8@1K9r3g2V1L8$3y4K6i4K6u0W2L8%4u0Y4i4K6u0r3k6h3&6Q4x3V1k6D9j5i4c8W2M7%4c8Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6W2P5s2c8W2L8Y4y4A6L8$3&6K6i4K6u0W2K9s2c8E0L8l9`.`.
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See 1dbK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4y4U0M7X3q4H3P5g2)9J5k6i4u0W2j5h3c8@1K9r3g2V1L8$3y4K6i4K6u0W2L8%4u0Y4i4K6u0r3k6h3&6Q4x3V1k6D9j5i4c8W2M7%4c8Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6A6N6r3g2E0i4K6u0V1M7r3W2H3k6h3I4A6L8X3g2Q4x3X3g2Z5N6r3#2D9
ITEM_PIPELINES = {
'BaiduStocks.pipelines.BaidustocksInfoPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See 9a6K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3c8G2j5#2)9J5k6i4y4U0M7X3q4H3P5g2)9J5k6h3!0J5k6#2)9J5c8X3g2F1i4K6u0r3L8r3q4@1k6i4y4@1i4K6u0r3N6r3!0H3K9h3y4K6i4K6u0r3j5i4g2@1L8%4c8Z5M7X3!0@1N6r3I4W2i4K6u0W2K9s2c8E0L8l9`.`.
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See 212K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4y4U0M7X3q4H3P5g2)9J5k6i4u0W2j5h3c8@1K9r3g2V1L8$3y4K6i4K6u0W2L8%4u0Y4i4K6u0r3k6h3&6Q4x3V1k6D9j5i4c8W2M7%4c8Q4x3V1k6@1L8%4m8A6j5%4y4Q4x3V1k6V1L8%4N6F1L8r3!0S2k6r3g2J5i4K6u0V1L8h3W2V1k6r3I4W2N6$3q4J5k6g2)9J5k6h3S2@1L8h3I4Q4x3U0y4Z5N6s2c8H3j5$3q4U0K9r3g2Q4x3X3c8E0K9h3c8V1L8r3g2%4j5i4u0W2i4K6u0V1M7$3g2@1N6r3W2F1k6%4x3`.
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
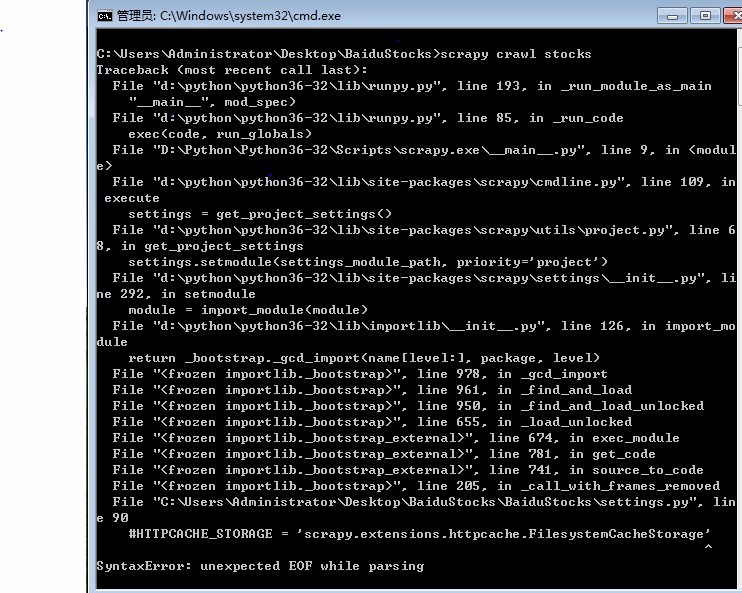
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
#pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: e6fK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3c8G2j5#2)9J5k6i4y4U0M7X3q4H3P5g2)9J5k6h3!0J5k6#2)9J5c8X3g2F1i4K6u0r3L8r3q4@1k6i4y4@1i4K6u0r3N6r3!0H3K9h3y4K6i4K6u0r3K9i4c8W2L8g2)9J5k6s2m8A6M7r3g2D9K9h3&6W2i4K6u0W2K9s2c8E0L8l9`.`.
class BaidustocksPipeline(object):
def process_item(self, item, spider):
return item
class BaidustocksInfoPipeline(object):
def open_spider(self, spider):
self.f =open('BaidustockInfo.txt','w')
def close_spider(self,spider):
self.f.close()
def process_item(self, item , spider):
try:
line = str(dict(item)) + '\n'
self.f.write(line)
except:
pass
return item