25号DASCTF七月赛的wp,日常打比赛练练手ing
F12直接给图片SRC,访问提示提交错误时间:
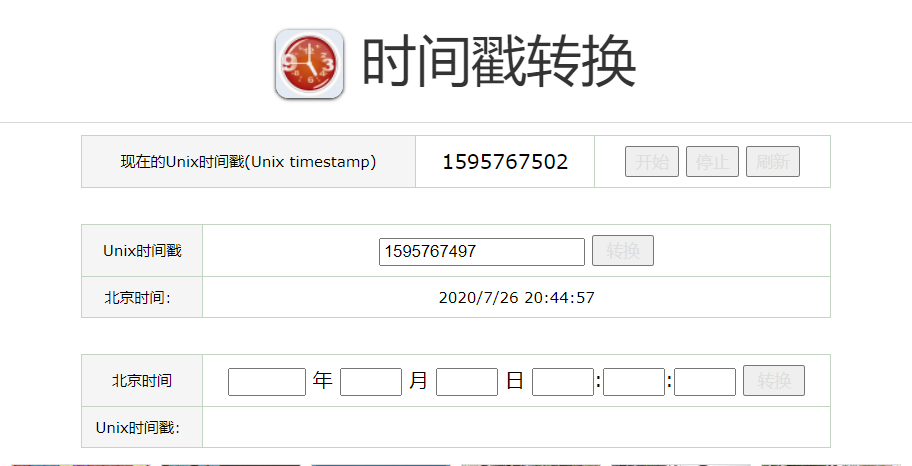
观察GET的参数
其中t为时间戳,是1970年1月1日以来的秒数,在 785K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6#2L8X3W2^5N6r3W2E0k6g2)9J5k6e0f1I4x3U0b7H3i4K6u0W2j5$3!0E0i4K6u0r3 这个网站可以方面进行查看。
f是字符串"gqy.jpg"的base64转码,可以直接构造出exp结构:
读取路径发现问题,有一层WAF过滤("You are not allowed to do that."),测试发现在路径前面随便加上一点东西就可以绕过了。
最终exp:
逆向有三题,看赛后也没人写逆向的wp,这里简单分享一下解题思路。
这题给了两个exe,一个是辅助,一个是补丁。首先看辅助.exe,核心代码如下图:
主要逻辑除了一些字符串输出,就是对输入的注册码进行验证,直接进行明文比较,正确的注册码应该是1_am_n0t_f1ag。然后再看补丁.exe,核心代码如下图:
主要逻辑除了一些字符串输出,就是对辅助.exe进行注入,第一个注入是对验证注册码的条件判断进行nop,所以,无论输入的注册码是什么,都会验证成功,第二个注入是在一段对齐的无用代码代码段注入了两个数,然后会输出flag{md5(dec(What_you_found))。当时看到这里着实没啥头绪,感觉是个脑洞题,试了几个答案都错了,就没管了,后来赛后,看群里做出来的师傅说,最后的flag是打的补丁那两个数字里比较大的那一个数的十进制然后再用md5加密。emmm反正我没试到这个,有点脑洞,但是程序本身不难,也基本说清楚了。
这题真的simple,也拿了一血。首先看主函数,如图:
很简单的tea加密,本来想下断调试一下,取一下v14最后的值,然后直接写个脚本逆一下就好了。但是调试的时候发现有一点点坑,在第一个函数sub_4110F0里,直接运行结束了。然后重新调试,跟进去这个个函数,发现里面依然是一个tea加密,所以还是原来的思路运行一下取v8最后的值,然后写个简单的脚本就出来了。
调试得到的加密算法如图:
最后的解密脚本如下:
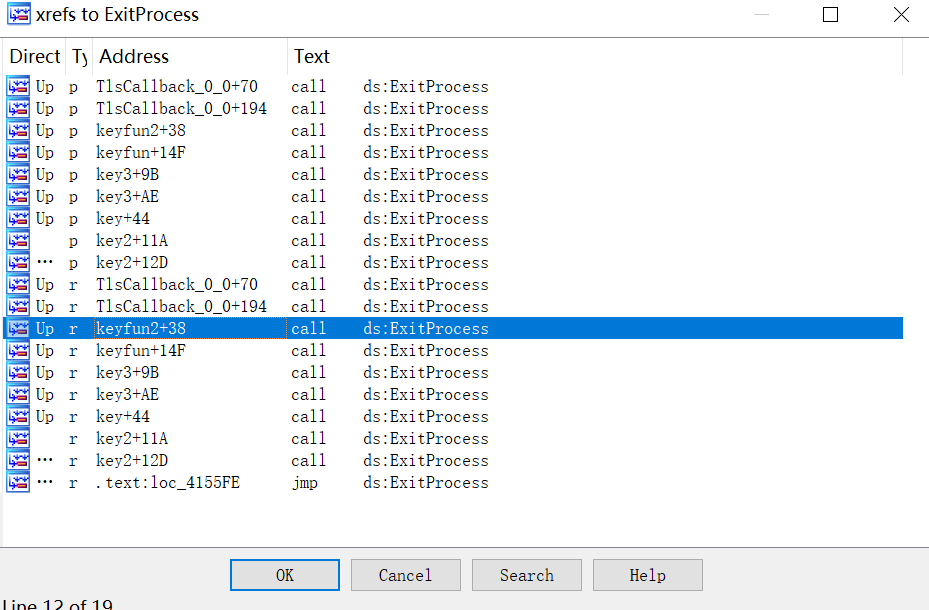
这题好晚才放,有几个点又卡了一下,赛后过一会才解出来,找出题人验证了一下,答案是正确的。主函数wmian栈太大了,没办法反编译,试了几个方法也没成功,就直接在开头下断点准备调试看看,然后发现直接闪退,肯定有反调,先处理反调。直接搜ExitProcess函数的交出引用,可以看到不少反调:
在跳转语句处下断点,跑一遍看看程序的执行流程。要改zf位的跳转语句其实就两个地方:
第一个在回调函数0x041183E处:
第二个在0x041518E处:
然后程序会运行到第一个关键函数sub_415250:
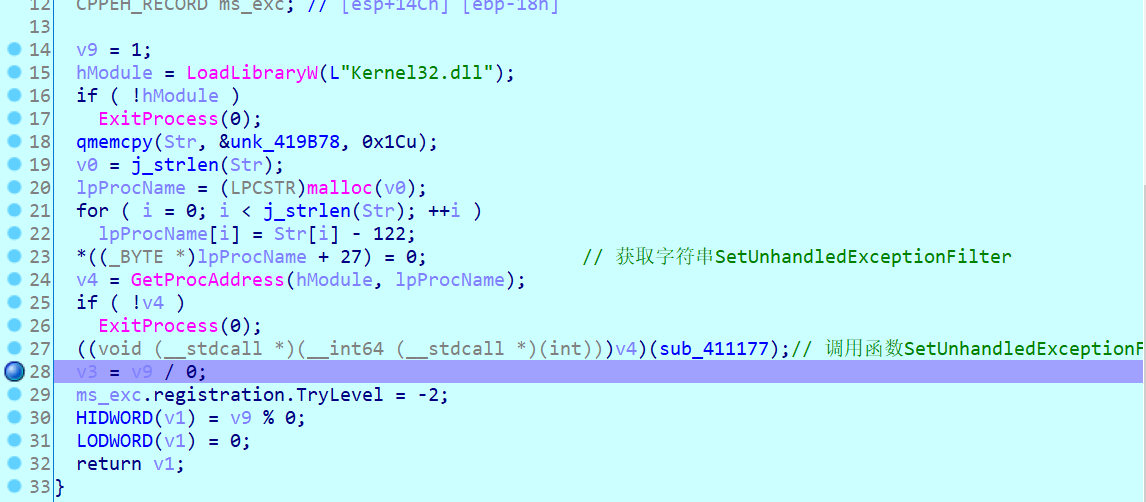
这里注册了一个异常处理函数,然后进行除零操作引发异常,所以关键逻辑其实在sub_411177函数。ida动态调试还是有些缺陷,这个异常处理我断不下来,想调试的话用xdbg或者od。
跟进函数到sub_411EC0,这里是才是核心处理逻辑:
字符替换就是把N换成R,T换成Y,主要看验证函数:
验证函数经过一系列累加运算后,v7数组最后要保证每个数都不大于150,v5要等于dword_41C040,这里直接z3求解就好,这里要把这里的N,Y字符串替换成0,1,然后相乘再累加,因为z3定义的未知数不支持做条件判断,具体操作直接看解密代码:
最后再把字符串替换回来:
其实有3个地方的0,1可以任意,因为那三处的dword_41C0D8[j] - dword_41C048[j]为0,但是这三处全0应该才是正确答案。
题目源自2020 DASCTF七月赛
链接:008K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6H3j5h3&6Q4x3X3g2T1j5h3W2V1N6g2)9J5k6h3y4G2L8g2)9J5c8Y4y4Q4x3V1j5I4N6p5W2F1k6q4S2g2e0$3S2o6M7X3^5$3k6#2y4b7x3V1&6e0d9@1!0A6b7b7`.`.提取码:ln2b
原题目Hint:每张二维码都有6个字符被编码了,把它们提取出来!
下载得到 QrJoker.gif,可以看到Gif中每一帧都有半张QR Code,首先把它们都分离出来:
QrJoker.gif
对于这种残缺的QR Code,如果是只有右边的话,通常做法是把QR Code填涂在 ebaK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6E0k6i4u0J5K9h3y4^5i4K6u0W2k6$3W2@1K9s2g2T1i4K6u0W2K9h3!0Q4x3V1k6I4M7X3q4*7P5h3u0G2P5q4)9J5c8R3`.`. 上,然后借助网站的直接解码功能获得QR Code中的内容
但是这里的残缺QR Code多达64张,最好编写脚本完成(当然一张张描上去也行,但是我懒)
虽然每张QR Code的图案都不一样,但是有三点是一样的:
大小一样;它们都是Version 1的QR Code
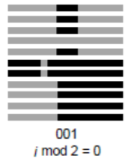
格式信息一样;以第一帧的QR Code举例:
红框中读取得到 100101,前往 f9dK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2@1K9r3!0F1K9%4W2Q4x3X3g2U0L8$3#2Q4x3V1k6I4M7W2)9J5k6r3y4G2k6r3g2Q4x3X3c8@1N6i4c8G2M7X3W2S2L8q4)9J5c8X3k6G2M7X3#2S2N6q4)9J5k6s2k6W2M7Y4y4A6L8$3&6Q4x3X3c8@1j5h3u0D9k6i4x3`. 查阅,发现匹配上了:
100101
于是知道这张QR Code的纠错等级为 M、掩码为 1;由于只有右边的数据而丢失了左边的纠错码,所以我们不用管纠错等级
右下方数据一样
如果熟悉QR Code的格式的话会知道,右下方是QR Code中数据的起点,它通常包含一张QR Code的编码方式和长度这两种信息;结合题目告知的「每张QR Code包含6个字符」,所以每张QR Code对内容的编码方式、内容长度都是相同的
每张残缺QR Code的数据区域就是上图中的绿色区域,它是一个6×12码元(即基本单位)大小的区域,我们首先用Python的PIL模块将QR Code中的每个码元读取进来
这里以分离出的第一帧图片为例;代码中主要是一个二重循环,我们可以用Windows中的画图程序将QR Code中每个码元的位置找出来,如:
通过这样,得知每个码元的分辨率是10×10;并且最左上角的码元的位置是(410, 90)
二重循环是每次读取一行的6个数据,依次读取完12行,得到整个6×12区域的数据(代码中,offset 的存在只是为了取到每个码元最中间的像素点)
offset
获得一张QR Code的数据后,根据前面观察图片可知,每张QR Code的掩码都是 1,编号1对应的掩码图案就是:
这个掩码图案比较简单,对QR Code中的数据隔行进行比特翻转:
最终 data 变量就是一个6×12的矩阵,其中存储着摘除了掩码后的QR Code数据
data
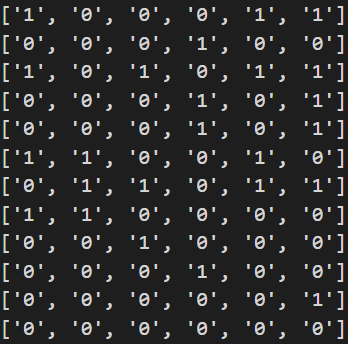
以第一帧图片举例,运行代码得到的 data 为:
对应上了摘除掩码后的数据:
有了 data 后,就可以对其中的01字符序列进行处理了
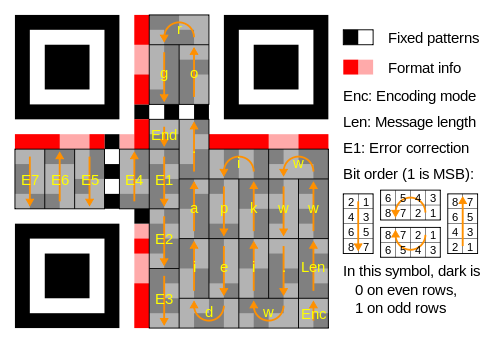
上图是从网上找到的QR Code Version 1的结构图,可以看到,从右下角开始,它的每个数据块都是连续的,不像Version 3一样,块的顺序是不连续的:
所以对获得的 data 的处理就很简单了:
按照QR Code Version 1存放数据的顺序,读取出这张QR Code顺序正确的数据
以第一帧的图片为例,最终得到的 res 为:
res
这就是第一帧的QR Code的内容了
按照QR Code对数据的编码规则对上面的 res 进行解码
首先看前4 Bits的数据是 0010,所以它采用的编码模式是字母数字模式(Alphanumeric Mode);然后又因为是Version 1的QR Code,所以内容长度占据9 Bits,内容长度的值是 0x000000110 = 6
0010
请参考 b25K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2@1K9r3!0F1K9%4W2Q4x3X3g2U0L8$3#2Q4x3V1k6I4M7W2)9J5k6r3y4G2k6r3g2Q4x3X3c8@1N6i4c8G2M7X3W2S2L8q4)9J5c8X3c8S2N6r3q4Q4x3X3c8W2L8X3y4G2k6r3W2F1k6H3`.`.
所以解码代码为:
第一行代码中,由于已经知道前4 Bits是模式指示符、之后的9 Bits是长度,所以直接截掉;又因为采用Alphanumeric Mode,每两个字符占11 Bits,QR Code中有6个字符,所以有效的只是之后的33 Bits
参考 230K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2@1K9r3!0F1K9%4W2Q4x3X3g2U0L8$3#2Q4x3V1k6I4M7W2)9J5k6r3y4G2k6r3g2Q4x3X3c8@1N6i4c8G2M7X3W2S2L8q4)9J5c8X3q4D9M7r3S2S2L8Y4g2E0k6i4u0A6j5#2)9J5k6r3#2G2k6r3g2Q4x3X3c8W2L8X3y4G2k6r3W2F1k6H3`.`.
代码中的 mapping 是Alphanumeric Mode的映射表,可以参考 648K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2@1K9r3!0F1K9%4W2Q4x3X3g2U0L8$3#2Q4x3V1k6I4M7W2)9J5k6r3y4G2k6r3g2Q4x3X3c8@1N6i4c8G2M7X3W2S2L8q4)9J5c8X3q4D9M7r3S2S2L8Y4g2E0k6i4u0A6j5#2)9J5k6s2c8S2j5X3I4W2;最后便按照Allphanumeric Mode的编码方式,将每11 Bits解码成2个字符
mapping
所有QR Code中的数据提取出来后就很简单了,把得到的字符串先 unescape(),然后多次Base64解码即可得到flag
unescape()
下载后解压得到 red_blue.png 和 加密了的 flag.rar
red_blue.png
flag.rar
看到图片的名字是 red_blue,以为是双图隐写,用StegSolve导出R通道和B通道上的图片,发现不是;而且B通道上的图片反色后,跟R通道的一模一样
red_blue
然后用zsteg检索图片的不同通道,发现:
R通道的最低位上隐藏了一张PNG图片的数据,用StegSolve将其导出,得到:
得到压缩包密码,解压 flag.rar
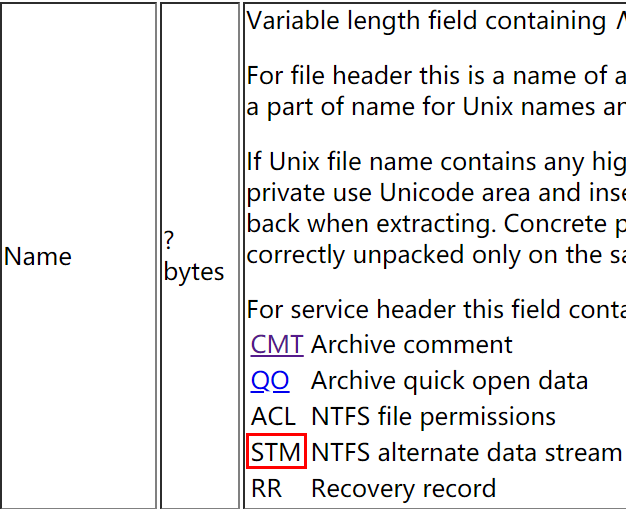
压缩包 flag.rar 存在NTFS隐写,我看别人都是解压软件直接将隐藏的 flag.txt 显示出来了;我是用010 Editor打开 flag.rar 的数据,然后搜索字符串 STM,检索到两处,因此才怀疑有NTFS隐写
flag.txt
STM
至于为什么检索字符串 STM,请参考 027K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2J5j5i4u0D9j5h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6@1k6h3y4Z5L8X3!0@1k6g2)9J5k6h3S2@1L8g2)9J5x3%4y4J5N6X3S2W2j5h3c8W2M7Y4x3`.,其中有:
STM 是Rar格式文件中,存在备用数据流的标识
既然存在NTFS隐写,就用WinRar将 flag.rar 解压后,cmd下执行 dir /r,查看到:
dir /r
notepad 指令将那个 7.jpg:flag.txt 打开,得到:
notepad
7.jpg:flag.txt
[培训]科锐逆向工程师培训第53期2025年7月8日开班!
不会修电脑 游戏辅助那道题,师傅可以用xdbg跟一下,看看到底写入了些什么数据。
xmhwws 这比赛链接请发下
xmhwws 第一题原图有吗?用来当头像感觉不错[em_84]