
能力值:
 ( LV6,RANK:80 )
( LV6,RANK:80 )
|
-
-
2 楼
你在说什么,A底层也是调用W,windows底层是unicode,编码的问题非要赖api
|

能力值:
 ( LV1,RANK:0 )
( LV1,RANK:0 )
|
-
-
3 楼
黑洛
你在说什么,A底层也是调用W,windows底层是unicode,编码的问题非要赖api
A底层是W,但A不兼容中文
|

能力值:
 ( LV3,RANK:30 )
( LV3,RANK:30 )
|
-
-
4 楼
确实是api实现的问题,开发过程中没有考虑一个字符占多个字节的情况,无论是中文还是日文韩文都存在这个情况。StringCchLength输出的长度是字符的个数,而不是保存字符串所需的字节数。 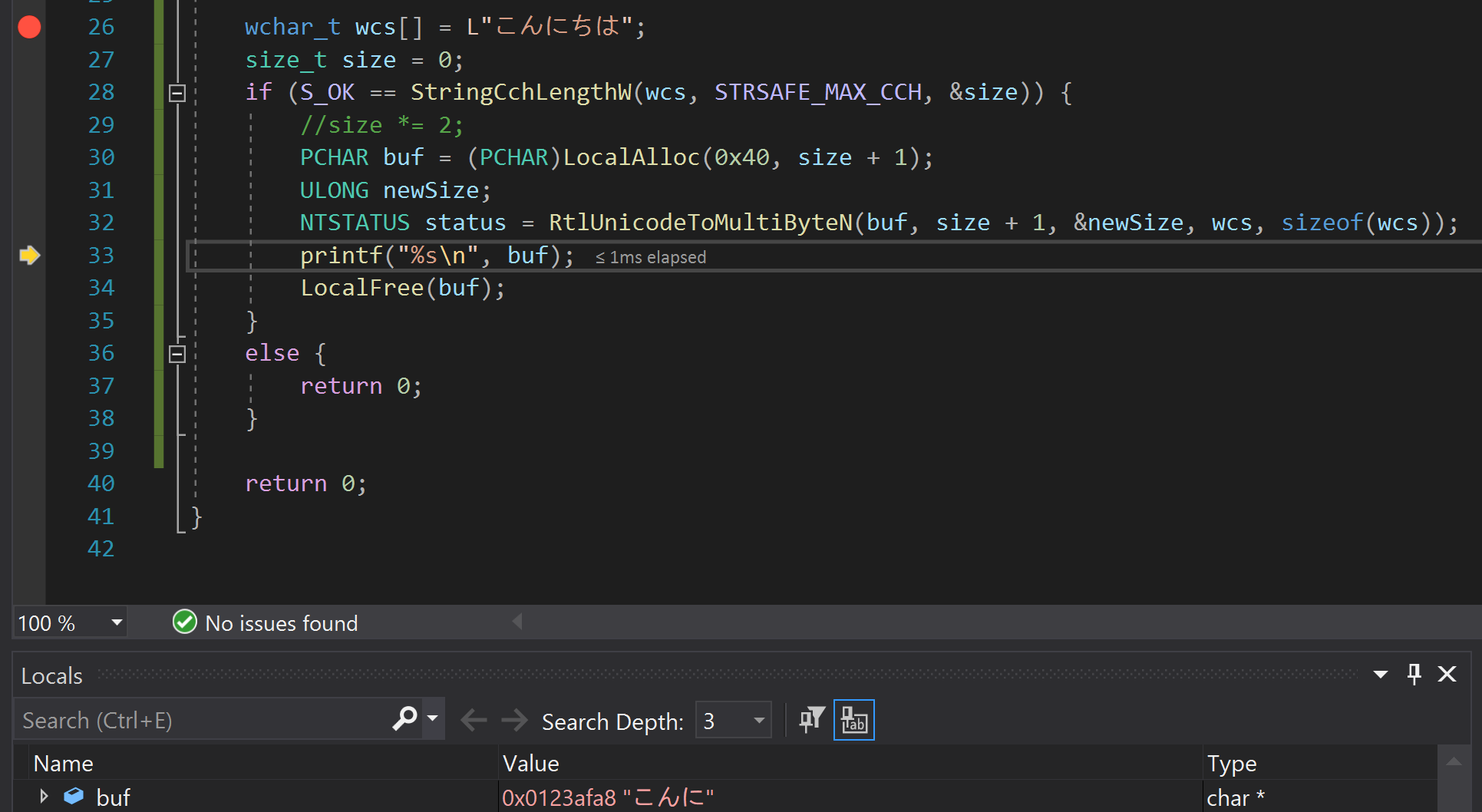
|
能力值:
( LV6,RANK:80 )
|
-
-
5 楼
Boring勇哥
确实是api实现的问题,开发过程中没有考虑一个字符占多个字节的情况,无论是中文还是日文韩文都存在这个情况。StringCchLength输出的长度是字符的个数,而不是保存字符串所需的字节数。
那有没有可能你把unicode改成多字节字节集就没有问题了呢?
|

能力值:
( LV2,RANK:10 )
|
-
-
6 楼
。
最后于 2023-3-1 16:46
被Foodie编辑
,原因: 。
|
能力值:
( LV2,RANK:10 )
|
-
-
7 楼
Boring勇哥
确实是api实现的问题,开发过程中没有考虑一个字符占多个字节的情况,无论是中文还是日文韩文都存在这个情况。StringCchLength输出的长度是字符的个数,而不是保存字符串所需的字节数。
确实是,把 StringCchLengthW 换成 RtlUnicodeToMultiByteSize 就可以了。
|
能力值:
( LV3,RANK:30 )
|
-
-
8 楼
黑洛
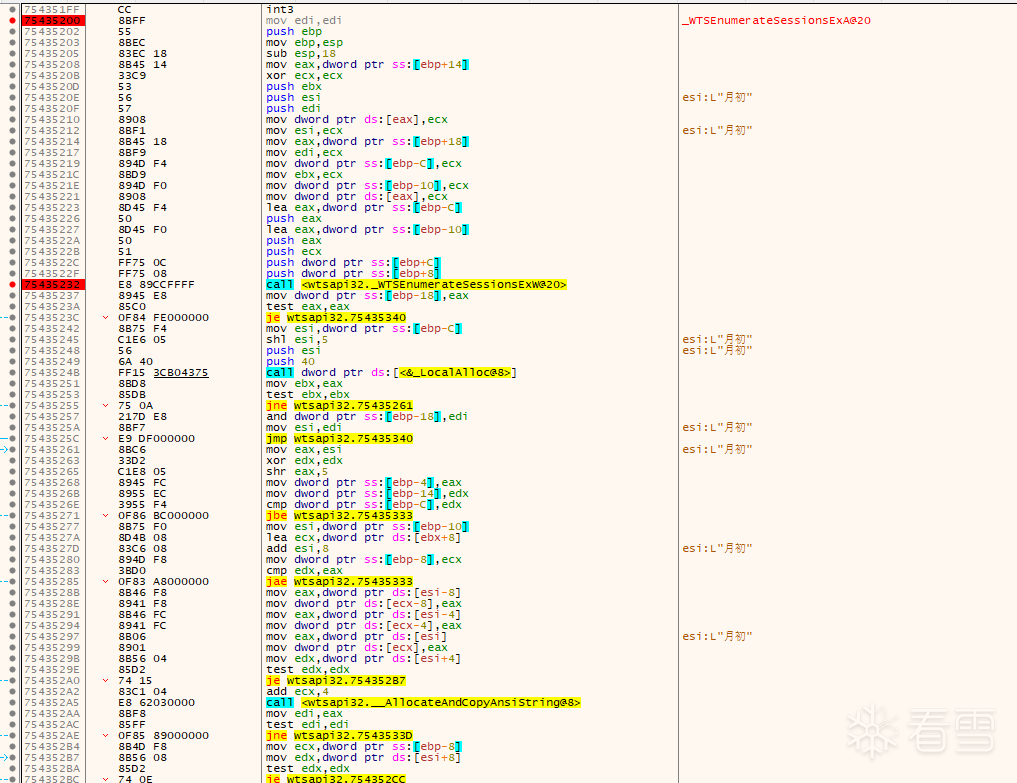
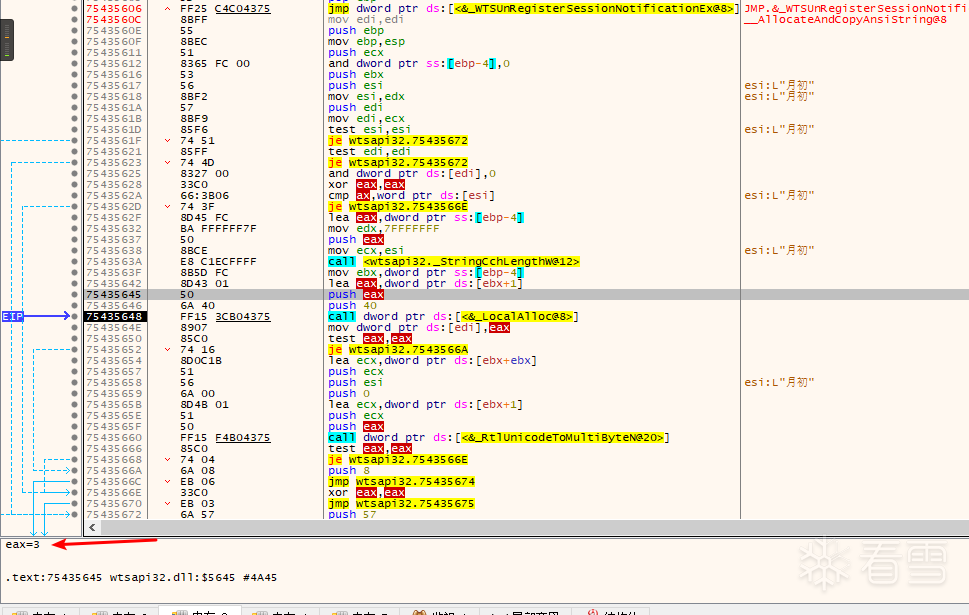
那有没有可能你把unicode改成多字节字节集就没有问题了呢? 建议你看看WTSEnumerateSessionsExA的反汇编,自己调用一下StringCchLengthW和RtlUnicodeToMultiByteN试试。 我把项目的字符集设置成了多字节,但它仍然不工作。 
最后于 2023-3-1 18:52
被Boring勇哥编辑
,原因:
|
能力值:
( LV2,RANK:10 )
|
-
-
9 楼
if (S_OK == StringCchLengthW(wcs , STRSAFE_MAX_CCH, &size))
{
PCHAR buf = (PCHAR)LocalAlloc(0x40 , size + 1);
ULONG newSize;
NTSTATUS status = RtlUnicodeToMultiByteN(buf,size+1,&newSize,wcs,sizeof(wcs));
printf("%s\n",buf);
LocalFree(buf);
}
修改为
if (S_OK == StringCchLengthW(wcs , STRSAFE_MAX_CCH, &size)) { PCHAR buf = (PCHAR)LocalAlloc(0x40 , size*2 + 1); // 1 UNICODE = 2 x CHAR ULONG newSize; NTSTATUS status = RtlUnicodeToMultiByteN(buf,size*2+1,&newSize,wcs,sizeof(wcs)); printf("%s\n",buf); LocalFree(buf); }
|

能力值:
( LV9,RANK:195 )
|
-
-
10 楼
。。。感觉楼主没有进行过系统化的开发训练,这是windows开发的常识。
字符串相关的API结尾带A说明本接口只支持解析ASCII码,W结尾说明支持解析UNICODE码。 windows的API命名除了极少数是历史原因导致的无法更改名称,只能将错就错了,99.9%的API名称的前缀后缀都是有标准含义的。
最后于 2023-3-2 14:36
被palkiver编辑
,原因:
|
能力值:
( LV3,RANK:30 )
|
-
-
11 楼
palkiver
。。。感觉楼主没有进行过系统化的开发训练,这是windows开发的常识。字符串相关的API结尾带A说明本接口只支持解析ASCII码,W结尾说明支持解析UNICODE码。windows的API命名除了极 ...
你可能搞错了。win32api中A结尾表示字符编码为ansi,而非ascii。而ansi是支持中文的。 参考: c4cK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6W2L8W2)9J5k6i4N6A6K9$3W2H3k6h3c8A6j5g2)9J5k6h3!0J5k6#2)9J5c8Y4N6A6K9$3W2Q4x3V1k6o6K9r3W2F1k6i4y4W2i4K6g2X3b7$3S2S2M7X3q4U0N6r3g2J5i4K6g2X3b7$3!0V1k6g2)9#2k6X3k6G2M7W2)9#2k6V1W2F1k6X3!0J5L8h3q4@1K9h3!0F1i4K6g2X3d9h3&6@1k6i4u0U0K9r3q4F1k6$3f1`.efbK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6D9k6h3q4J5L8W2)9J5k6h3#2A6j5%4u0G2M7$3!0X3N6q4)9J5k6h3y4G2L8g2)9J5c8X3g2F1i4K6u0V1N6i4y4Q4x3V1k6%4K9h3&6V1L8%4N6K6i4K6u0r3N6$3W2F1x3K6u0Q4x3V1k6A6L8Y4c8D9i4K6u0r3N6h3&6A6j5$3!0V1k6g2)9J5k6r3W2F1i4K6u0V1N6r3S2W2i4K6u0V1N6$3W2F1k6r3!0%4M7#2)9J5k6r3q4H3K9b7`.`.
|
能力值:
( LV6,RANK:80 )
|
-
-
12 楼
Boring勇哥
你可能搞错了。win32api中A结尾表示字符编码为ansi,而非ascii。而ansi是支持中文的。
参考:e33K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6W2L8W2)9J5k6i4N6A6K9$3W2H3k6h3c8A6j5g2)9J5k6h3!0J5k6#2)9J5c8Y4N6A6K9$3W2Q4x3V1k6o6K9r3W2F1k6i4y4W2i4K6g2X3b7$3S2S2M7X3q4U0 ...
看过了,系统实现确实有问题
|
能力值:
( LV9,RANK:195 )
|
-
-
13 楼
Boring勇哥
你可能搞错了。win32api中A结尾表示字符编码为ansi,而非ascii。而ansi是支持中文的。
参考:967K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6W2L8W2)9J5k6i4N6A6K9$3W2H3k6h3c8A6j5g2)9J5k6h3!0J5k6#2)9J5c8Y4N6A6K9$3W2Q4x3V1k6o6K9r3W2F1k6i4y4W2i4K6g2X3b7$3S2S2M7X3q4U0 ...
我没搞错,你非要说这么严格的话,那就严格来说ansi在不同的操作系统中以及不同国家代表着不同的编码方式,开发人员很多时候不能假定用户环境,最好的办法就是将A理解为ASCII,非ASCII直接上UNICODE,这是最保险的方式。
|
能力值:
( LV3,RANK:30 )
|
-
-
14 楼
palkiver
我没搞错,你非要说这么严格的话,那就严格来说ansi在不同的操作系统中以及不同国家代表着不同的编码方式,开发人员很多时候不能假定用户环境,最好的办法就是将A理解为ASCII,非ASCII直接上UNIC ...
你说的对,使用宽字符是一个好的做法,微软也推荐使用。
|
|
|
|





 黑洛
黑洛 