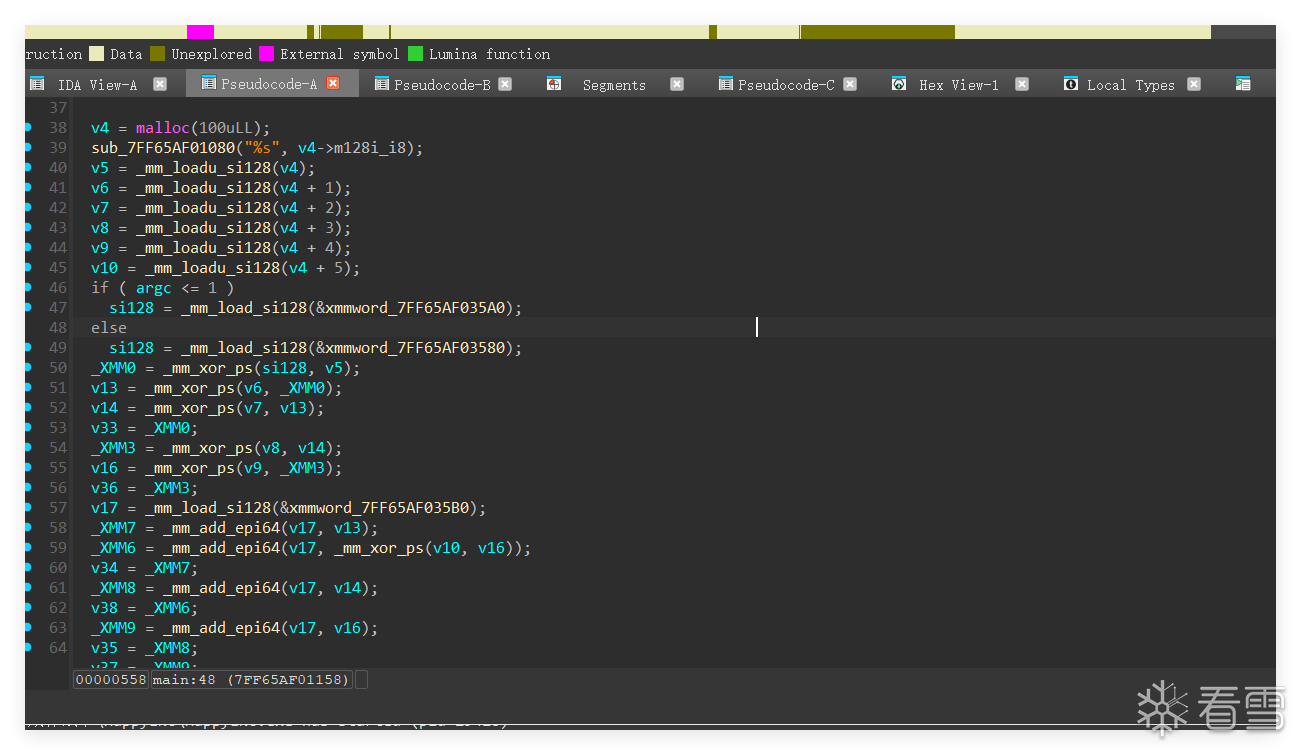
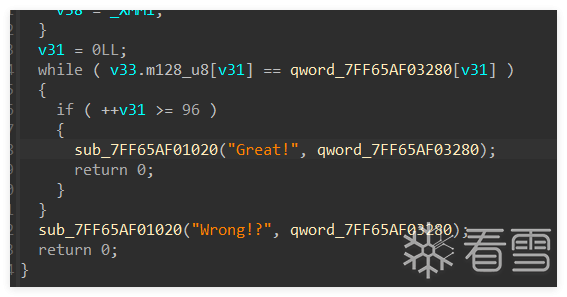
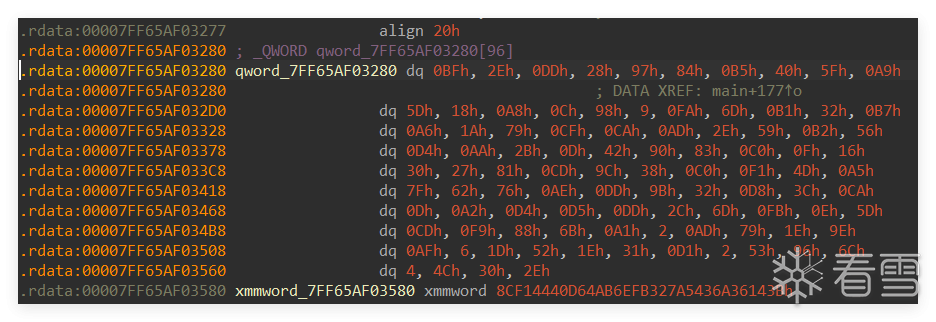
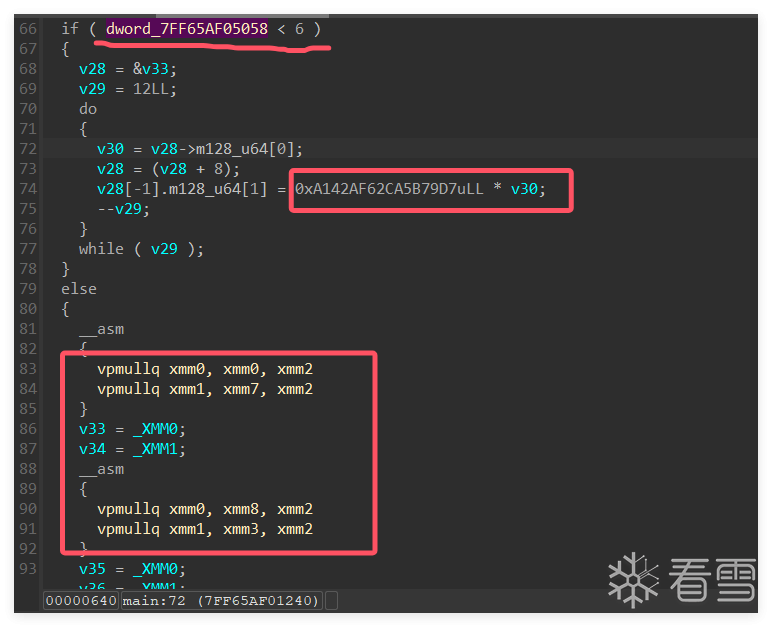
#include <stdio.h>
#include <iostream>
#include <xmmintrin.h>
int main()
{
unsigned long unk_140003280[96] = {
0x00000000000000BF, 0x000000000000002E, 0x00000000000000DD, 0x0000000000000028,
0x0000000000000097, 0x0000000000000084, 0x00000000000000B5, 0x0000000000000040,
0x000000000000005F, 0x00000000000000A9, 0x000000000000005D, 0x0000000000000018,
0x00000000000000A8, 0x000000000000000C, 0x0000000000000098, 0x0000000000000009,
0x00000000000000FA, 0x000000000000006D, 0x00000000000000B1, 0x0000000000000032,
0x00000000000000B7, 0x00000000000000A6, 0x000000000000001A, 0x0000000000000079,
0x00000000000000CF, 0x00000000000000CA, 0x00000000000000AD, 0x000000000000002E,
0x0000000000000059, 0x00000000000000B2, 0x0000000000000056, 0x00000000000000D4,
0x00000000000000AA, 0x000000000000002B, 0x000000000000000D, 0x0000000000000042,
0x0000000000000090, 0x0000000000000083, 0x00000000000000C0, 0x000000000000000F,
0x0000000000000016, 0x0000000000000030, 0x0000000000000027, 0x0000000000000081,
0x00000000000000CD, 0x000000000000009C, 0x0000000000000038, 0x00000000000000C0,
0x00000000000000F1, 0x000000000000004D, 0x00000000000000A5, 0x000000000000007F,
0x0000000000000062, 0x0000000000000076, 0x00000000000000AE, 0x00000000000000DD,
0x000000000000009B, 0x0000000000000032, 0x00000000000000D8, 0x000000000000003C,
0x00000000000000CA, 0x000000000000000D, 0x00000000000000A2, 0x00000000000000D4,
0x00000000000000D5, 0x00000000000000DD, 0x000000000000002C, 0x000000000000006D,
0x00000000000000FB, 0x000000000000000E, 0x000000000000005D, 0x00000000000000CD,
0x00000000000000F9, 0x0000000000000088, 0x000000000000006B, 0x00000000000000A1,
0x0000000000000002, 0x00000000000000AD, 0x0000000000000079, 0x000000000000001E,
0x000000000000009E, 0x00000000000000AF, 0x0000000000000006, 0x000000000000001D,
0x0000000000000052, 0x000000000000001E, 0x0000000000000031, 0x00000000000000D1,
0x0000000000000002, 0x0000000000000053, 0x0000000000000096, 0x000000000000006C,
0x0000000000000004, 0x000000000000004C, 0x0000000000000030, 0x000000000000002E
};
unsigned char temp[16]={0};
for(int i=0;i<96;)
{
for(int j=0;j<8;j++)
{
temp[j]=unk_140003280[i];
i++;
}
printf("0x");
for(int j=7;j>=0;j--)
{
printf("%02x",temp[j]);
}
printf(",\n");
}
return 0;
}