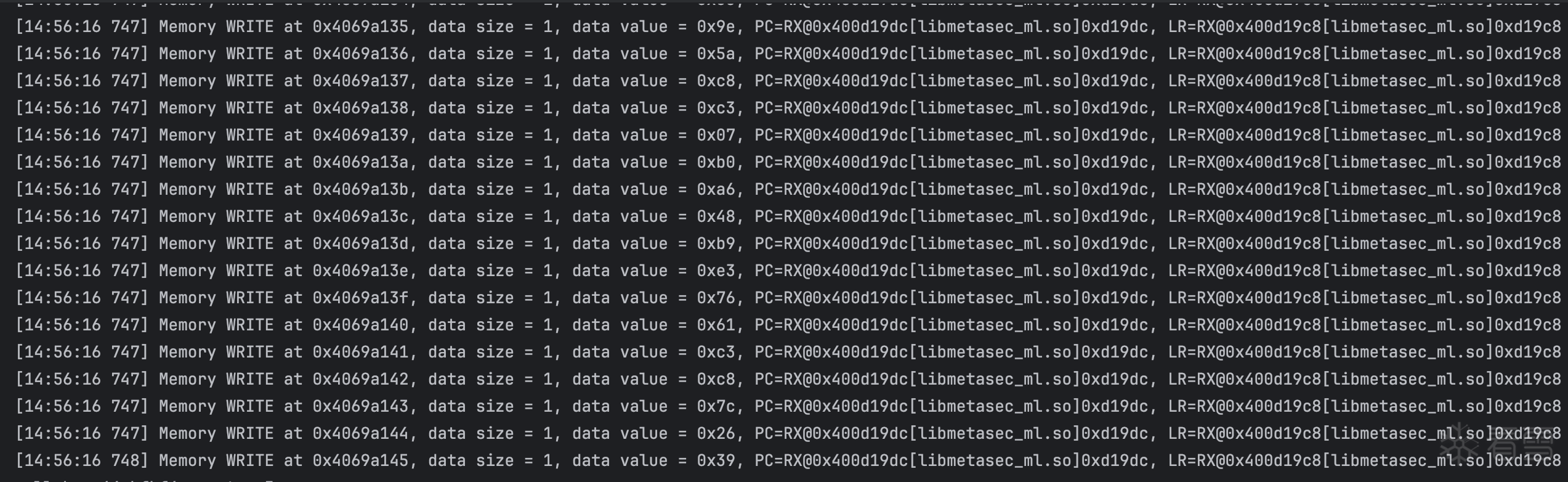
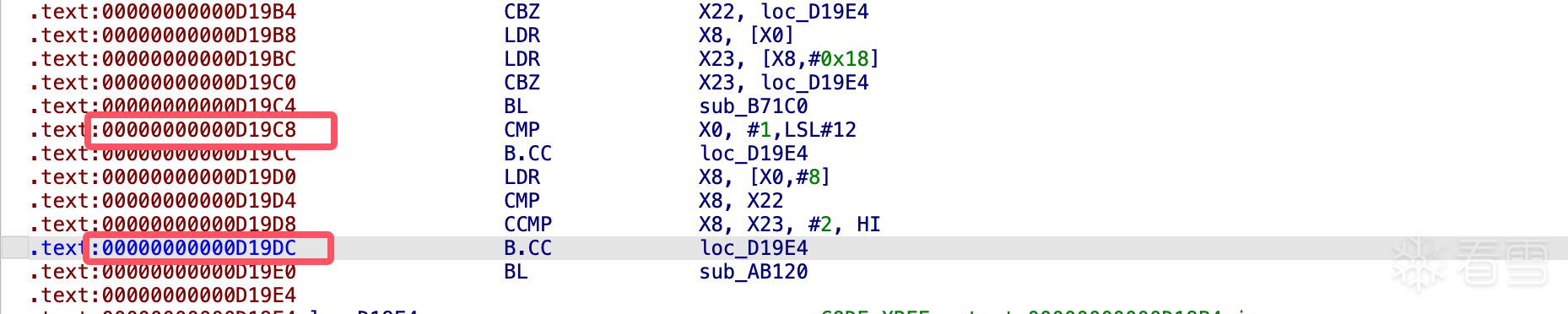
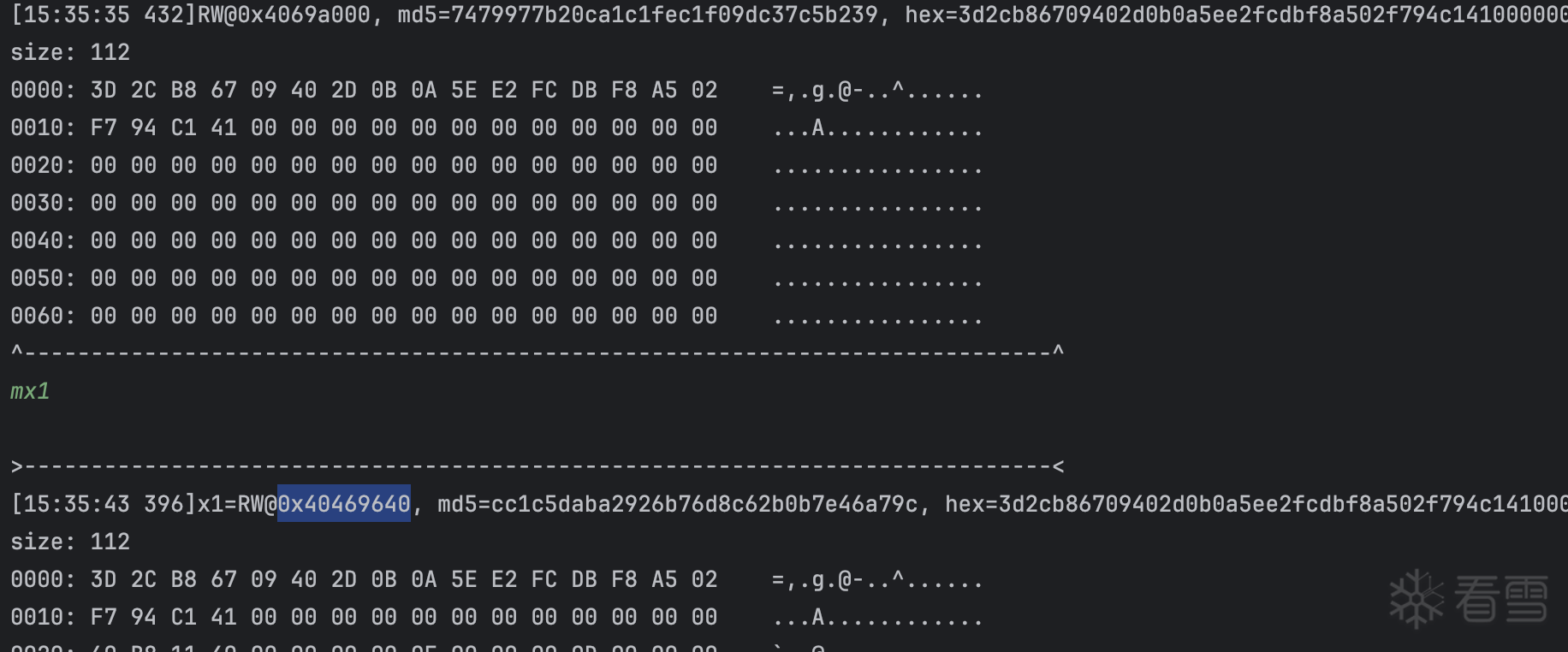
import numpy as np
from loguru import logger
from gmssl import sm3, func
from itertools import cycle
from Crypto.Util.Padding import pad
sign_key_bytes = bytes.fromhex("ac1adaae95a7af94a5114ab3b3a97dd80050aa0a39314c40528caec95256c28c")
rand_num = bytes.fromhex("7283514a")
protobuf_mixed_bytes = sm3.sm3_hash(func.bytes_to_list(sign_key_bytes + rand_num + sign_key_bytes))
logger.debug(protobuf_mixed_bytes)
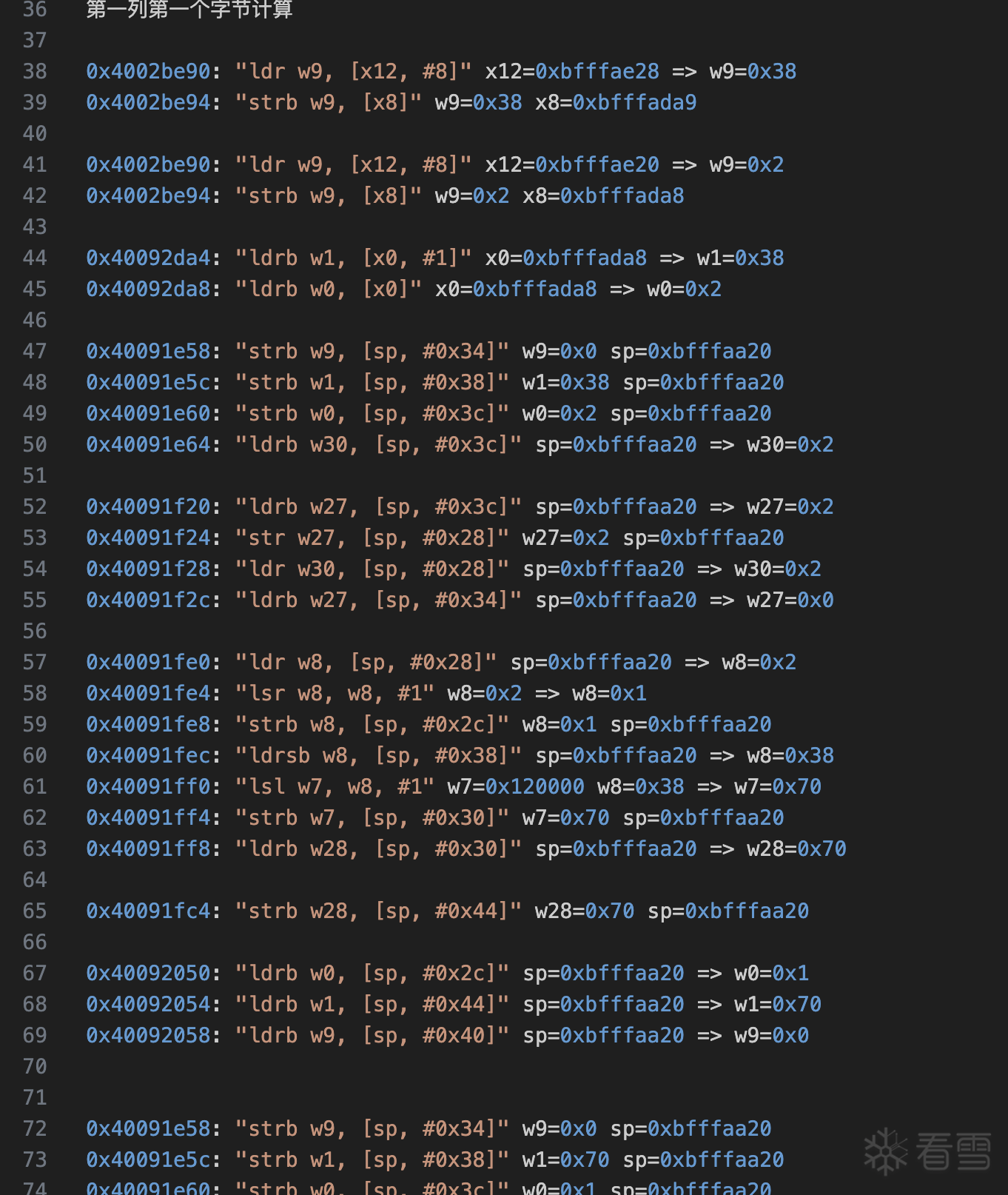
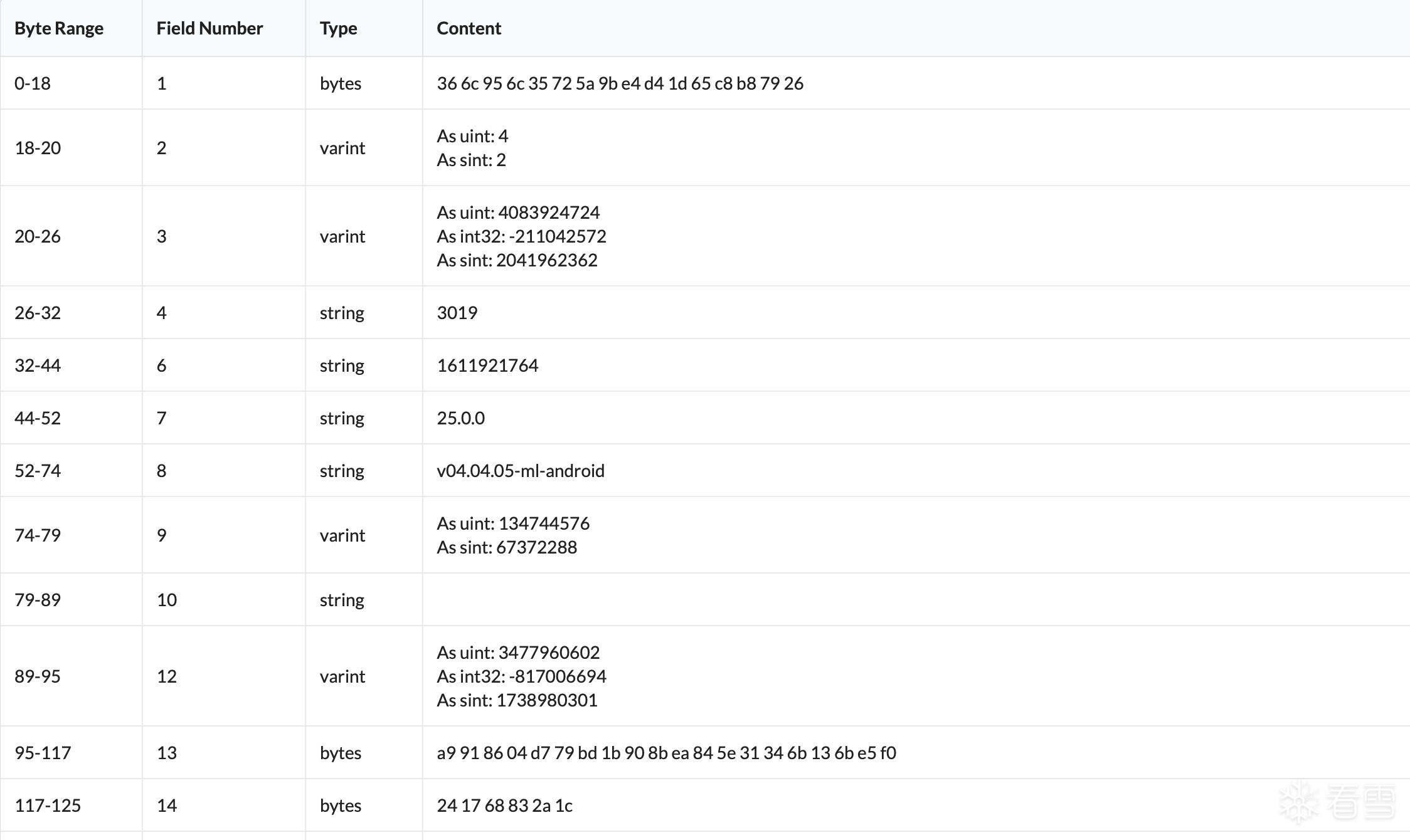
device_protobuf = bytes.fromhex("0a10366c956c35725a9be4d41d65c8b87926100418f4fdae9b0f220433303139320a313631313932313736343a0632352e302e3042147630342e30342e30352d6d6c2d616e64726f6964488094a04052080000000000000000609aefb5fa0c6a14a9918604d779bd1b908bea845e31346b136be5f07206241768832a1c7a0e080210bee15418bee15420bee154a201046e6f6e65a801e205ba010908e68de1f90c38ac71c2016a7b0a0922636d72223a0931363737373231362c0a0922636d7232223a0931363737373231362c0a0922756e5f68223a09302c0a09226b64223a093639343336372c0a0922666b64223a09313939383031383230342c0a09227064223a092d313034333039303038350a7d")
def c_bitwise_not(num):
bit_size = 32
mask = (1 << bit_size) - 1
result = ~num & mask
if result & (1 << (bit_size - 1)):
result -= (1 << bit_size)
return result
def bfxill(w21, w8):
extracted_bits = (w8 >> 3) & 0b11111
w21 = w21 & ~0b11111
w21 = w21 | extracted_bits
return w21
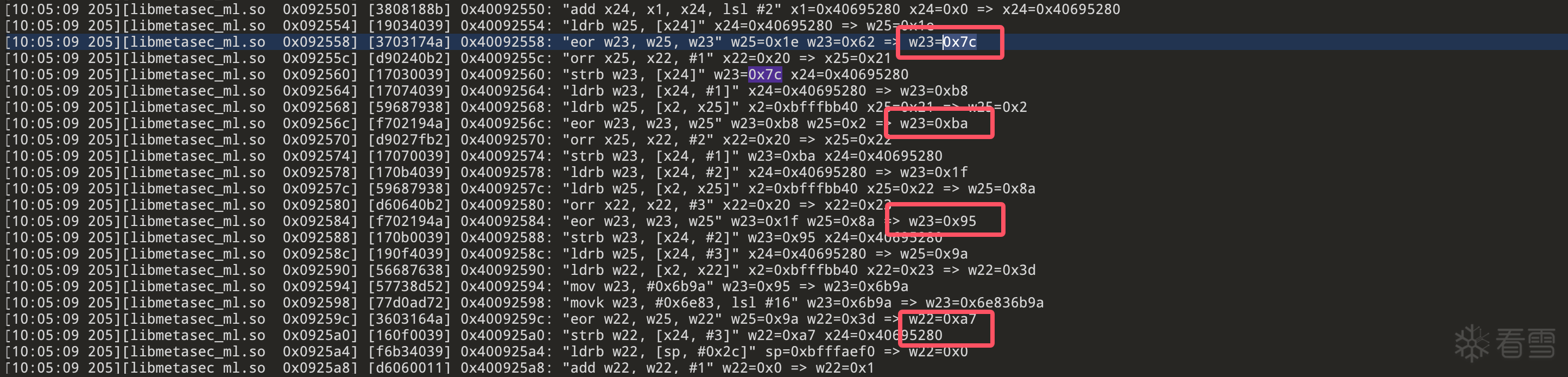
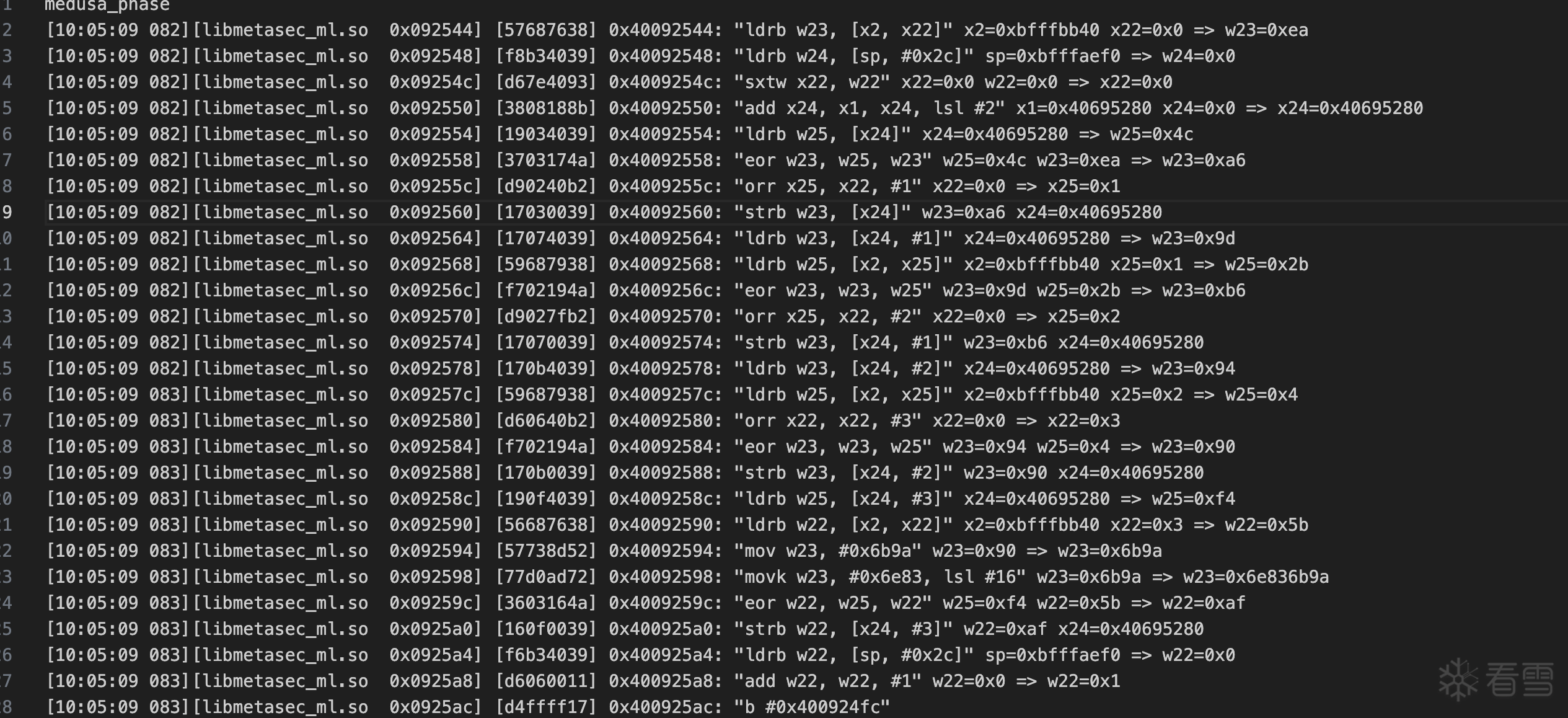
def medusa_protobuf_mixed(protobuf_bytes: bytes, mix_param_bytes: bytes):
result = []
for i, b in enumerate(protobuf_bytes):
idx = (4 * i) % len(mix_param_bytes)
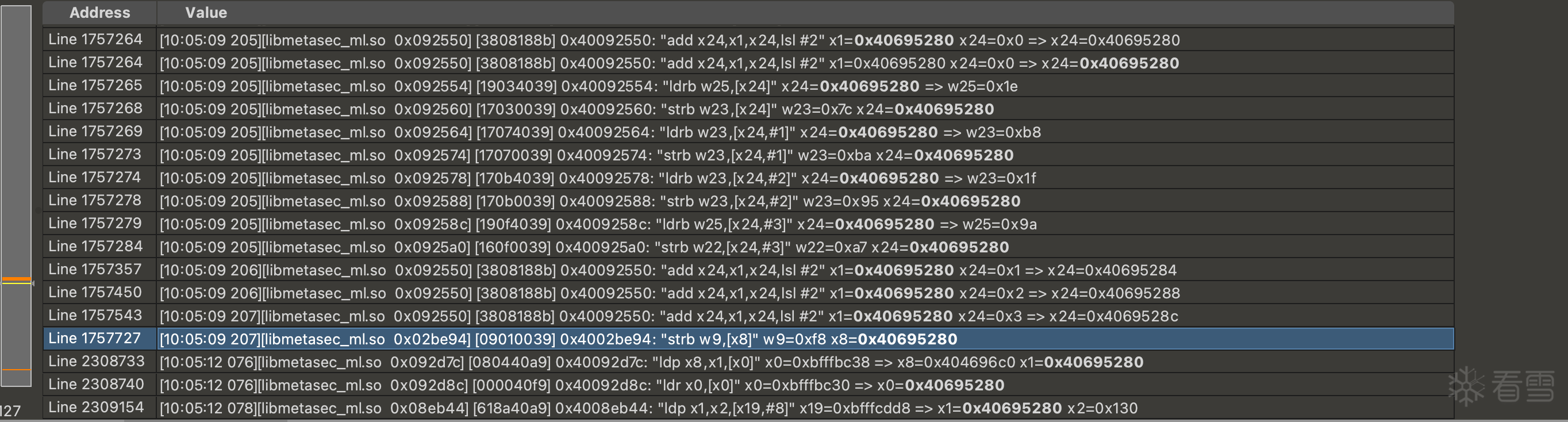
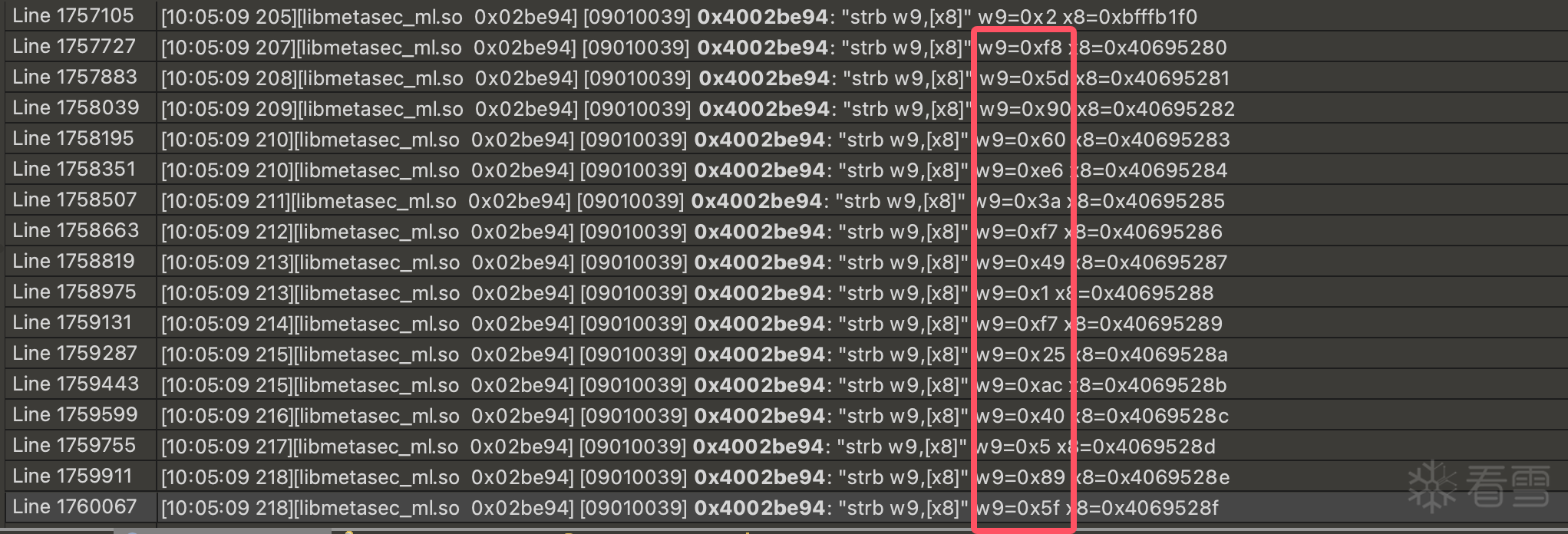
tmp = (b >> 2) & 0xffffc03f | (b << 6)
tmp += mix_param_bytes[idx]
eon_val = (tmp ^ c_bitwise_not(mix_param_bytes[idx + 1])) & 0xffffffff
tmp = bfxill((32 * eon_val & 0xffffffff), eon_val) + mix_param_bytes[idx + 1]
tmp = (mix_param_bytes[idx] ^ c_bitwise_not(tmp)) & 0xffffffff
result.append(int.to_bytes(tmp, 4, byteorder='little')[0])
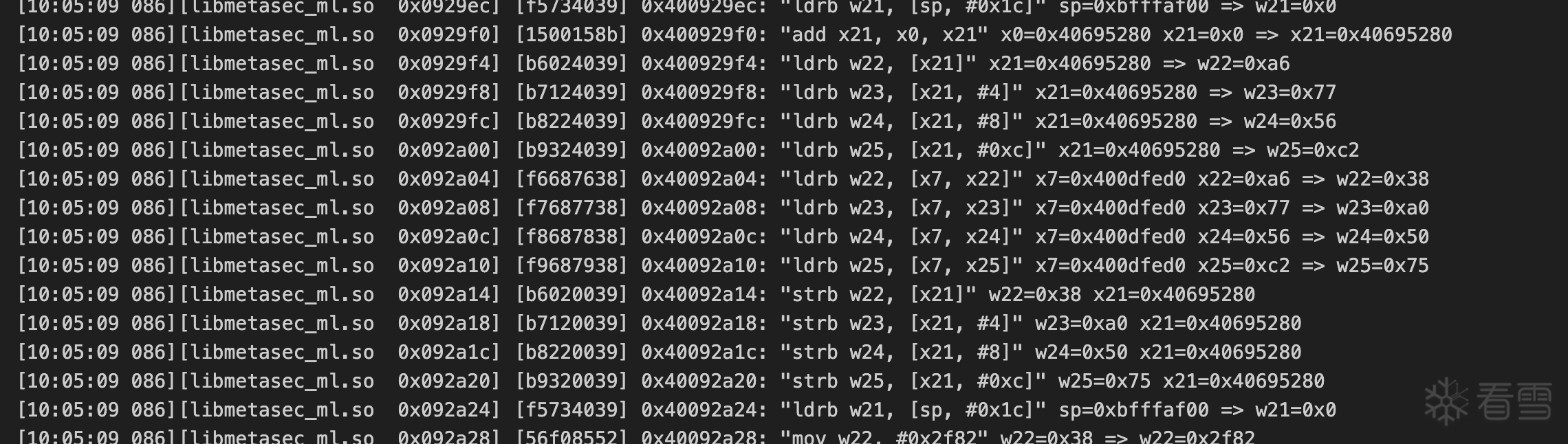
mixed_param = list(reversed(result))
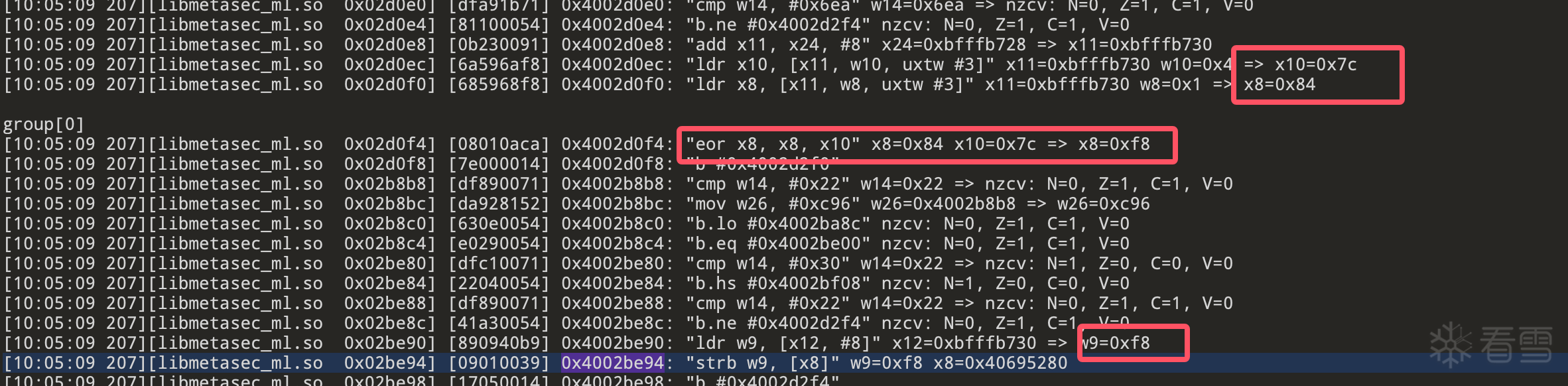
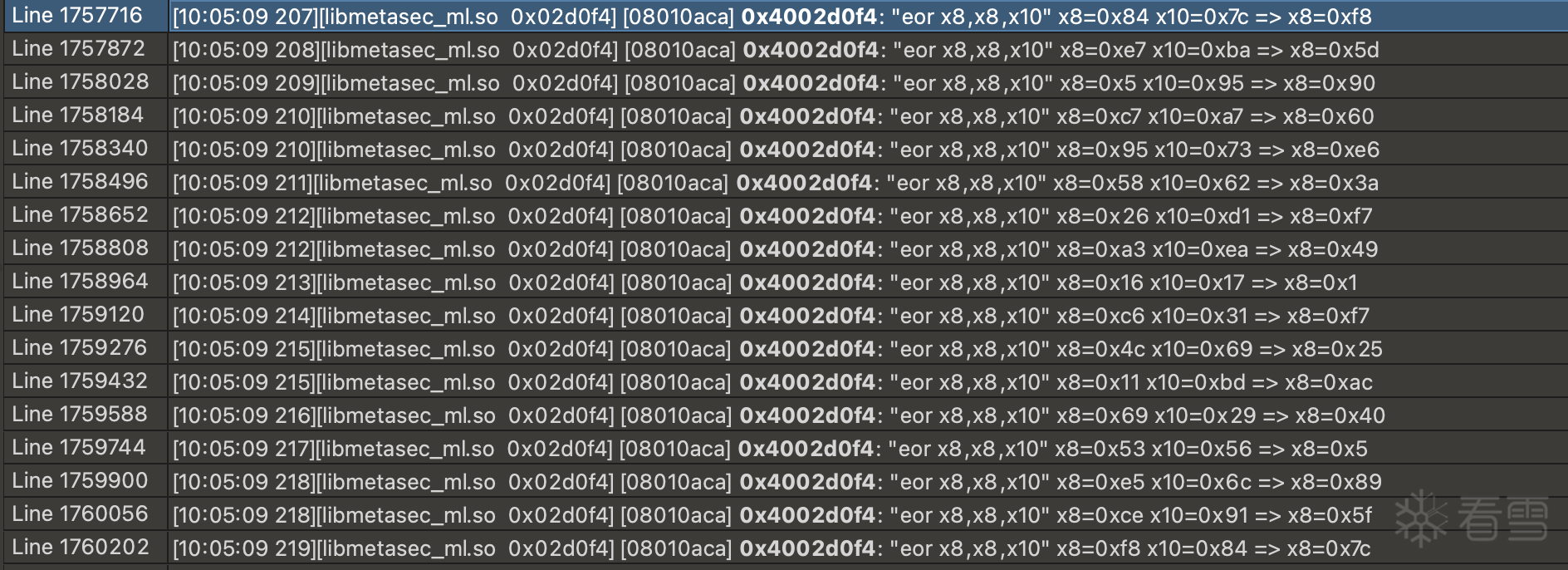
mixed_param[0] = (((c_bitwise_not(mixed_param[-2]) ^ mixed_param[-1]) & 0xffffffff) + mixed_param[0]) & 0xffffffff
mixed_param[1] = (mixed_param[0] ^ mixed_param[-1] ^ 0xfe) + mixed_param[1] & 0xffffffff
for i in range(2, len(mixed_param) - 1):
mixed_param[i] += mixed_param[i-2] ^ (((mixed_param[i-1] & 0x80 != 0)) | (2 * mixed_param[i-1])) ^ (c_bitwise_not(i) & 0xffffffff)
mixed_param[i] = int.to_bytes(mixed_param[i], 8, byteorder='little')[0]
mixed_param[-1] ^= mixed_param[-2]
return bytes(mixed_param[1:])
protobuf_processed = medusa_protobuf_mixed(device_protobuf, bytes.fromhex(protobuf_mixed_bytes))
logger.debug(protobuf_processed.hex())
def get_xor_key(random_bytes: bytes):
a, b = random_bytes[-2], random_bytes[-1]
res = a ^ (a >> 0x5) ^ ((a << 0xb | b))
res = (~res) & 0xffffffff
return res
logger.debug(f"xor key calculated {hex(get_xor_key(rand_num))}")
xor_key = bytes.fromhex('fffd77e6')
pad_bytes = bytes.fromhex('00000000000000000d')
xor_result = bytearray([a ^ b for a, b in zip(reversed(pad_bytes + protobuf_processed), cycle(xor_key))])
logger.debug(f"xor result: {xor_result.hex()}" )
prefix_bytes = bytes.fromhex('a6')
prefix_bytes += bytes.fromhex("859ef750")
prefix_bytes += bytes.fromhex("01290918")
aes_lite_in_bytes = prefix_bytes + xor_result + rand_num[2:]
aes_lite_in_bytes = pad(aes_lite_in_bytes, 16)
logger.debug(f"aes lite input: {aes_lite_in_bytes.hex()}")
round_key = bytes.fromhex("ea2b045b11bf2364839e6ab27f95a9df84e705c7955826a316c64c116953e5ce62028a3df75aac9ee19ce08f88cf0541")
dfed0_table = [
0x2E, 0x5C, 0x55, 0xED, 0x1B, 0xDA, 0xA, 0x79, 0x28,
0x69, 0x57, 0xFE, 0x68, 0x3A, 0xDE, 0xAC, 0x90, 0xF9,
0xC1, 0xE1, 0xC3, 0x8B, 0x7F, 0x59, 0x26, 0xCA, 0x13,
0xBB, 0x11, 0x37, 0x39, 0x21, 0xEB, 0x9A, 0xFF, 0x5E,
0x42, 0x33, 0xBE, 0x51, 0x8D, 0x40, 0x1E, 0x91, 0xB3,
0x85, 0xB7, 0xCD, 0xDC, 0x27, 0x92, 0x83, 0x87, 0x3F,
0xE6, 0x4A, 0x64, 0x56, 0x8C, 0xA1, 0x76, 0xD2, 0xFD,
0xC0, 0x63, 0x18, 0x44, 0x1A, 0x9F, 0x61, 0xCB, 0x6E,
0x67, 0x29, 0xAF, 0xB8, 0x54, 0x60, 0xDB, 0x97, 0xE8,
0xA3, 0xC9, 0xE4, 0, 0xEC, 0x50, 0x17, 0xBD, 0x2A,
0xB6, 0x8E, 0x3B, 0x46, 0x65, 0xA6, 0x7A, 0x96, 0xD3,
0x72, 0x12, 0xBC, 0x20, 0x4D, 0x7C, 0xFA, 0x15, 0xC,
0x41, 0x9B, 0xAA, 9, 0xF8, 0xF0, 0x5D, 0x84, 0xFC,
0xE, 0xD6, 0xA0, 0xF2, 0xEF, 0x4E, 0x10, 0xBF, 0x89,
0x6D, 0x9C, 0x98, 6, 0xC2, 0xC7, 0x5A, 0xF1, 0xB1,
0xA5, 0xF4, 0xB9, 0xA2, 0xF5, 0x78, 0xAE, 0x3D, 0x24,
0xFB, 0x30, 0x9D, 0xD8, 0xA4, 0x6F, 0x1F, 0x49, 0xD0,
0x95, 0x3C, 0x99, 0xBA, 0x23, 0xEA, 0x53, 0x14, 0x2B,
0xE0, 0xD, 0x5B, 0x94, 0x38, 0x4B, 0x1C, 0xCC, 0x4C,
0x88, 0x2C, 0x81, 0xF3, 0x9E, 0x70, 0xF6, 0x58, 0x45,
0xB0, 0x35, 0x5F, 0x6A, 0x8A, 0x32, 0x19, 0x34, 0xDD,
0x4F, 0x7D, 0x36, 0xEE, 0xAB, 0x75, 0x71, 0xF, 0x25,
0xB5, 0xE9, 0x47, 0xF7, 0xCF, 0x43, 0x6C, 0xC6, 0x8F,
0x31, 0xB2, 0x2F, 0xD9, 0x1D, 0xC4, 0xA8, 0xD4, 0x93,
0x73, 0xA7, 0x82, 0x77, 0x66, 8, 0x6B, 1, 0xA9, 0xE3,
0xD5, 0xAD, 0xD7, 0xE5, 0x62, 0x86, 3, 0x22, 0xB4,
0x2D, 0xD1, 0xDF, 0x3E, 0x7B, 0x52, 0xE2, 0x7E, 0x48,
0xE7, 0xB, 4, 0xC8, 0x16, 0xC5, 2, 0xCE, 7, 0x74, 0x80,
5, 0x8D, 1, 2, 4, 8, 0x10, 0x20, 0x40, 0x80, 0x1B,
0x36, 0, 0, 0, 0, 0,
]
def shift_rows(s):
s[0][1], s[1][1], s[2][1], s[3][1] = s[2][1], s[3][1], s[0][1], s[1][1]
s[0][2], s[1][2], s[2][2], s[3][2] = s[3][2], s[0][2], s[1][2], s[2][2]
s[0][3], s[1][3], s[2][3], s[3][3] = s[1][3], s[2][3], s[3][3], s[0][3]
def gf_multiply(a, b):
p = 0
counter = 0
while b:
if b & 1:
p ^= a
a <<= 1
if a & 0x100:
a ^= 0x11B
b >>= 1
counter += 1
return p
def mix_columns(state):
new_state = [[0 for _ in range(4)] for _ in range(4)]
mix_matrix = [
[0x02, 0x03, 0x01, 0x01],
[0x01, 0x02, 0x03, 0x01],
[0x01, 0x01, 0x02, 0x03],
[0x03, 0x01, 0x01, 0x02]
]
for col in range(4):
for row in range(4):
for k in range(4):
new_state[row][col] ^= gf_multiply(mix_matrix[row][k], state[k][col])
return new_state
def add_round_key(matrix, round_key):
for i in range(4):
for j in range(4):
matrix[i][j] ^= round_key[i * 4 + j]
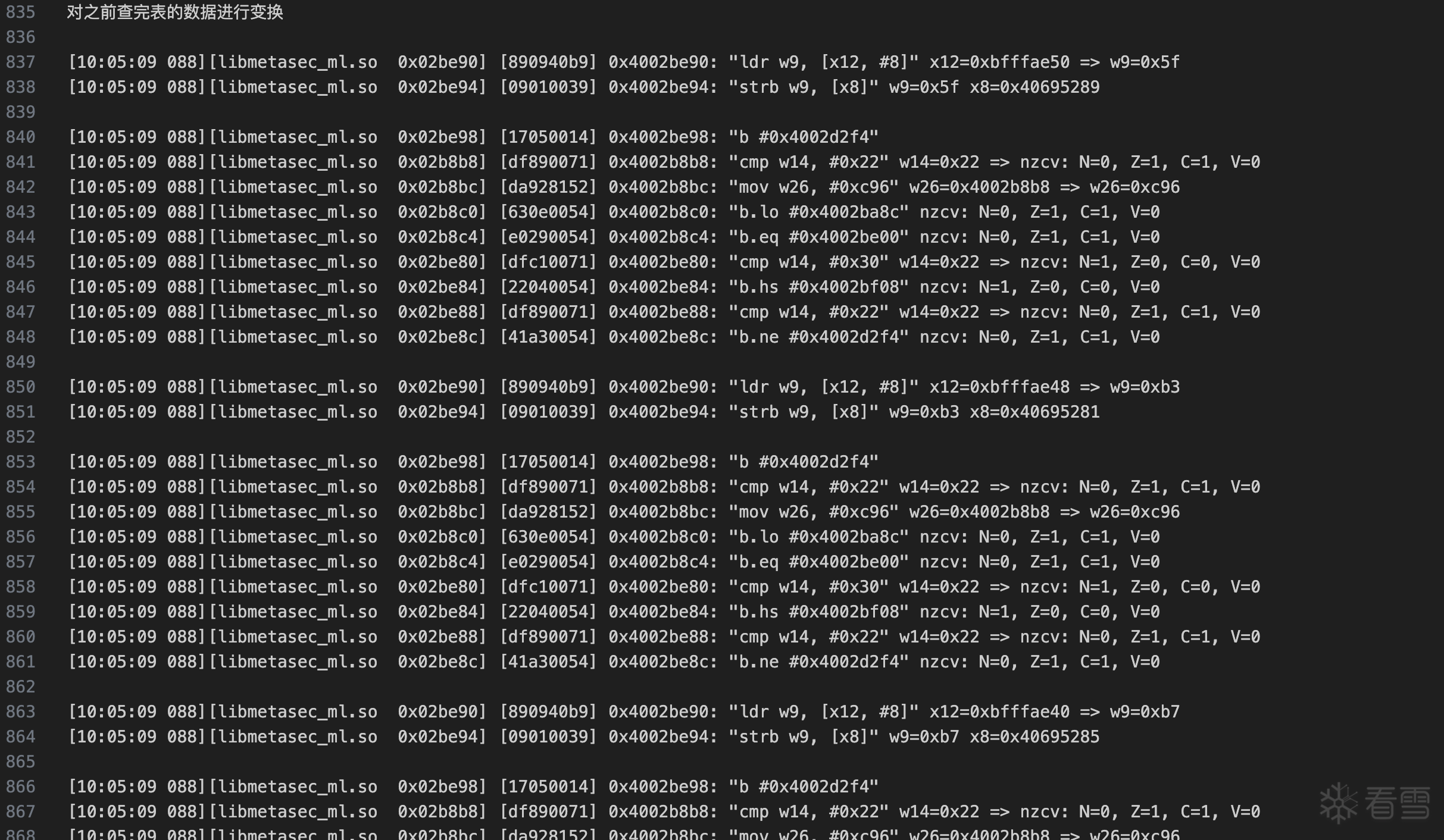
def round_encrypt(block_bytes: bytes):
iv = round_key[:16]
state = bytes([a ^ b for a, b in zip(block_bytes, iv)])
state = [dfed0_table[a] for a in state]
state = np.asarray(state).reshape((4, 4))
shift_rows(state)
state = mix_columns(state)
add_round_key(state, round_key[16:32])
state = [dfed0_table[a] for a in np.asarray(state).flatten()]
state = np.asarray(state).reshape((4, 4))
shift_rows(state)
add_round_key(state, round_key[32:])
add_round_key(state, round_key[16:32])
return bytes(state.flatten().astype(np.uint8))
def aes_encrypt(message: bytes):
assert len(message) % 16 == 0, 'Message must be padded for AES block size!'
encrypted_msg = b''
iv = bytes.fromhex("ea180a0336ed352fcd24e4d50018ae54")
for i in range(0, len(message), 16):
msg = message[i:i+16] if iv is None else bytes([a ^ b for a, b in zip(message[i:i+16], iv)])
iv = round_encrypt(msg)
encrypted_msg += iv
return encrypted_msg
aes_result = aes_encrypt(aes_lite_in_bytes)
logger.debug(f"aes lite result: {aes_result.hex()}")