-
-
[原创] nanopb 静态分析
-
发表于: 2025-4-13 16:34 3204
-

nanopb bddK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6F1j5h3&6G2M7r3u0Q4x3V1k6F1j5h3&6G2M7r3t1`. 是 protobuf 的一个节省资源的实现。生成出来的可执行程序和 protobuf 略有区别,所以无法用 protobuf 逆向中直接输入文件,读取 descriptor 来复原 proto 的工具(例如 pbtk:b09K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6E0j5i4u0A6L8W2)9J5k6r3#2Q4x3V1k6H3j5Y4c8C8i4@1g2r3i4@1u0o6i4K6R3&6i4@1f1K6i4K6R3H3i4K6R3J5
nanopb 最终传输的数据和 protobuf 是兼容的,所以如果能够拿到数据就可以用 protobuf-decoder 之类的工具解析。但是拿不到数据的情况下,纯静态分析代码也不是不行。
网上搜了一下,发现三年前有人写了一个 nanopb ida 解析脚本 3bdK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6S2L8Y4k6A6L8s2y4W2j5%4g2J5k6g2)9J5c8X3&6S2L8X3!0H3j5W2)9J5k6r3c8W2j5$3!0E0M7r3W2D9k6i4t1`. 。可惜我这用起来老是报错,解析出来的 proto 完全不符合逻辑。
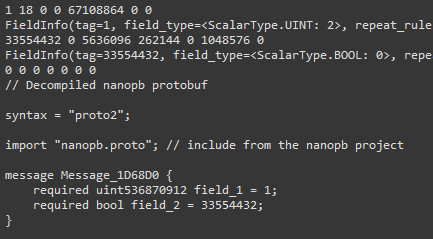
从这个脚本的实现看,nanopb 不同版本的实现细节还不一样。直接拉几份 nanopb LTS 版本的源码下来看。
经过编译比对发现,我分析的文件比较接近 3.9.10 版本,所以后面的例子版本都是 nanopb-3.9.10 。编译比对的时候最好用 linux,Windows 下编出来某些结构体调试信息的偏移似乎不太对劲。
和 protobuf 一样,用户先定义 .proto 文件。例如
编译时会生成 simple.pb.c 和 simple.pb.h。用户需要关注的其实只有 消息名_fields 这个结构体。下面这个简单的解析示例中,我们看到 SimpleMessage_fields 作为 pb_encode 和 pb_decode 的第二个参数。
查看这个结构体的具体实现。
是一个 pb_field_t 结构体数组。这个 fileds 带了所有字段的信息,最后结尾是一个全 0 的结构。所以只要在程序中找到这个字段,理论上就能恢复 .proto 文件。找到这个字段比较简单,寻找 pb_encode 和 pb_decode 的第二个参数就行。
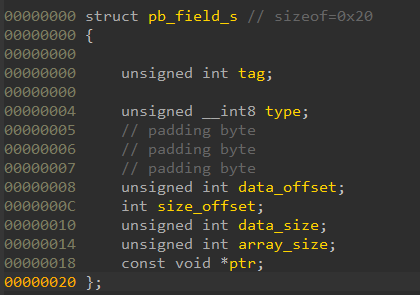
接下来详细分析 pb_field_t 这个结构体。开头的 tag 是字段 id。对应于 proto 文件中的 = 号后面的数字。type 定义了该字段的类型。最后的 ptr 定义了有没有子消息,也就是嵌套消息。中间的 offset 应该是记录该字段在结构体中的偏移。因为偏移/tag 可能超出一字节,所以 pb_size_t 做了一个变长的实现,可以是 8/16/32 位。
用户可以在编译的时候通过宏来决定结构体的长度
接下来继续分析 pb_type_t 的详细实现。这是一个一字节的描述类型的字段。在源码中搜索 PB_DECODERS,可以比较清晰的看到处理方法。低 4 位作为 PB_DECODERS 的序号决定 decoder/encoder 函数。高四位的低两位代表必须/可选/重复/Oneof,高两位代表分配类型静态/指针/回调。
到这里,拿到 fields 字段已经基本可以逆向复原出 protobuf 了。
先找到 pb_encode 或者 pb_decode,可以参考插件原作者的做法,或者通过别的字符串,或者 pb_ostream_t 定位。这一步不难。
要定位nanopb字段数组的内存位置,请按照以下步骤:
在IDA中搜索"wrong size for fixed count field"错误字符串。
跟踪XREF到记录此消息的函数。根据您的nanopb版本,这个函数可能是pb_decode_noinit或pb_decode_inner。
继续跟踪XREF到上述函数,这将是pb_decode或pb_decode_ex函数。第二个参数就是字段数组。
先看看被引用的字段之间的间隔,如果间隔有 0x20,那基本确定编译的时候用了 32 位的宏。在 ida 里定义结构体。
去 LocalTypes 里加个定义。
然后在字段上按 Y,输入pb_field_s回车。* 定义数组。
如果对不上号就调整一下结构体定义,尤其注意不同平台的对齐可能不一样。然后可以看到,结果十分的合理啊。
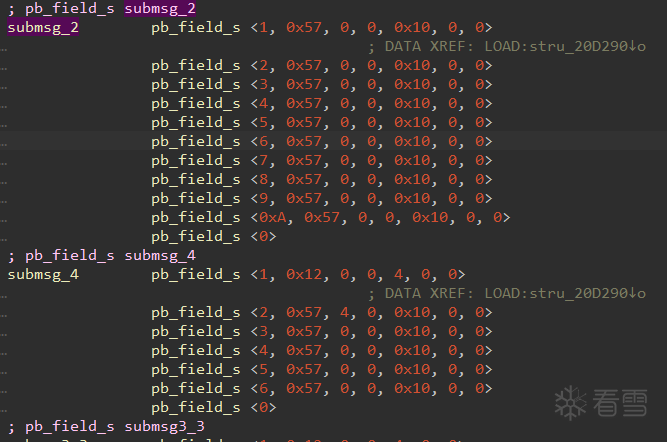
根据插件输出结果来看,结构解析肯定没对上号。插件里定义结构的函数是这样的
选择 8/16/32 位后,定义了 size_fmt,然后拼接一个 pb_filed_fmt 出来。这个结构体定义完全没有做对齐。而我这个文件里的结构是有对齐的。
那就加个对齐试试看。直接硬编码。xxx表示三字节对齐。
解出来十分合理,嵌套的子消息也都出来了。感谢前人的智慧~
本文简单分析了 nanopb 3.x 的二进制结构,并通过修复一款 nanopb 解析插件实现自动解析。nanopb 4.x 的字段定义结构有所改变,但插件修复的思路可能是一样的。
// A very simple protocol definition, consisting of only// one message.syntax = "proto2";message SimpleMessage { required int32 lucky_number = 1;}message ExampleMessage { required int32 field1 = 1; required bytes field2 = 2;}message ExampleMessage2 { optional int32 field1 = 1; optional bytes field2 = 2;}// A very simple protocol definition, consisting of only// one message.syntax = "proto2";message SimpleMessage { required int32 lucky_number = 1;}message ExampleMessage { required int32 field1 = 1; required bytes field2 = 2;}message ExampleMessage2 { optional int32 field1 = 1; optional bytes field2 = 2;}/* Encode our message */{ /* Allocate space on the stack to store the message data. * * Nanopb generates simple struct definitions for all the messages. * - check out the contents of simple.pb.h! * It is a good idea to always initialize your structures * so that you do not have garbage data from RAM in there. */ SimpleMessage message = SimpleMessage_init_zero; /* Create a stream that will write to our buffer. */ pb_ostream_t stream = pb_ostream_from_buffer(buffer, sizeof(buffer)); /* Fill in the lucky number */ message.lucky_number = 13; /* Now we are ready to encode the message! */ status = pb_encode(&stream, SimpleMessage_fields, &message); message_length = stream.bytes_written; /* Then just check for any errors.. */ if (!status) { printf("Encoding failed: %s\n", PB_GET_ERROR(&stream)); return 1; }}/* Now we could transmit the message over network, store it in a file or * wrap it to a pigeon's leg. *//* But because we are lazy, we will just decode it immediately. */{ /* Allocate space for the decoded message. */ SimpleMessage message = SimpleMessage_init_zero; /* Create a stream that reads from the buffer. */ pb_istream_t stream = pb_istream_from_buffer(buffer, message_length); /* Now we are ready to decode the message. */ status = pb_decode(&stream, SimpleMessage_fields, &message); /* Check for errors... */ if (!status) { printf("Decoding failed: %s\n", PB_GET_ERROR(&stream)); return 1; } /* Print the data contained in the message. */ printf("Your lucky number was %d!\n", message.lucky_number);}/* Encode our message */{ /* Allocate space on the stack to store the message data. * * Nanopb generates simple struct definitions for all the messages. * - check out the contents of simple.pb.h! * It is a good idea to always initialize your structures * so that you do not have garbage data from RAM in there. */ SimpleMessage message = SimpleMessage_init_zero; /* Create a stream that will write to our buffer. */ pb_ostream_t stream = pb_ostream_from_buffer(buffer, sizeof(buffer)); /* Fill in the lucky number */ message.lucky_number = 13; /* Now we are ready to encode the message! */ status = pb_encode(&stream, SimpleMessage_fields, &message); message_length = stream.bytes_written; /* Then just check for any errors.. */ if (!status) { printf("Encoding failed: %s\n", PB_GET_ERROR(&stream)); return 1; }}/* Now we could transmit the message over network, store it in a file or * wrap it to a pigeon's leg. *//* But because we are lazy, we will just decode it immediately. */{ /* Allocate space for the decoded message. */ SimpleMessage message = SimpleMessage_init_zero; /* Create a stream that reads from the buffer. */ pb_istream_t stream = pb_istream_from_buffer(buffer, message_length); /* Now we are ready to decode the message. */ status = pb_decode(&stream, SimpleMessage_fields, &message); /* Check for errors... */ if (!status) { printf("Decoding failed: %s\n", PB_GET_ERROR(&stream)); return 1; } /* Print the data contained in the message. */ printf("Your lucky number was %d!\n", message.lucky_number);}const pb_field_t SimpleMessage_fields[2] = { PB_FIELD( 1, INT32 , REQUIRED, STATIC , FIRST, SimpleMessage, lucky_number, lucky_number, 0), PB_LAST_FIELD};const pb_field_t ExampleMessage_fields[3] = { PB_FIELD( 1, INT32 , REQUIRED, STATIC , FIRST, ExampleMessage, field1, field1, 0), PB_FIELD( 2, BYTES , REQUIRED, CALLBACK, OTHER, ExampleMessage, field2, field1, 0), PB_LAST_FIELD};const pb_field_t ExampleMessage2_fields[3] = { PB_FIELD( 1, INT32 , OPTIONAL, STATIC , FIRST, ExampleMessage2, field1, field1, 0), PB_FIELD( 2, BYTES , OPTIONAL, CALLBACK, OTHER, ExampleMessage2, field2, field1, 0), PB_LAST_FIELD};const pb_field_t SimpleMessage_fields[2] = { PB_FIELD( 1, INT32 , REQUIRED, STATIC , FIRST, SimpleMessage, lucky_number, lucky_number, 0), PB_LAST_FIELD};const pb_field_t ExampleMessage_fields[3] = { PB_FIELD( 1, INT32 , REQUIRED, STATIC , FIRST, ExampleMessage, field1, field1, 0), PB_FIELD( 2, BYTES , REQUIRED, CALLBACK, OTHER, ExampleMessage, field2, field1, 0), PB_LAST_FIELD};const pb_field_t ExampleMessage2_fields[3] = { PB_FIELD( 1, INT32 , OPTIONAL, STATIC , FIRST, ExampleMessage2, field1, field1, 0), PB_FIELD( 2, BYTES , OPTIONAL, CALLBACK, OTHER, ExampleMessage2, field2, field1, 0), PB_LAST_FIELD};typedef struct pb_field_s pb_field_t;struct pb_field_s { pb_size_t tag; pb_type_t type; pb_size_t data_offset; /* Offset of field data, relative to previous field. */ pb_ssize_t size_offset; /* Offset of array size or has-boolean, relative to data */ pb_size_t data_size; /* Data size in bytes for a single item */ pb_size_t array_size; /* Maximum number of entries in array */ /* Field definitions for submessage * OR default value for all other non-array, non-callback types * If null, then field will zeroed. */ const void *ptr;} pb_packed;typedef struct pb_field_s pb_field_t;struct pb_field_s { pb_size_t tag; pb_type_t type; pb_size_t data_offset; /* Offset of field data, relative to previous field. */ pb_ssize_t size_offset; /* Offset of array size or has-boolean, relative to data */ pb_size_t data_size; /* Data size in bytes for a single item */ pb_size_t array_size; /* Maximum number of entries in array */ /* Field definitions for submessage * OR default value for all other non-array, non-callback types * If null, then field will zeroed. */ const void *ptr;} pb_packed;/* Data type used for storing sizes of struct fields * and array counts. */#if defined(PB_FIELD_32BIT) typedef uint32_t pb_size_t; typedef int32_t pb_ssize_t;#elif defined(PB_FIELD_16BIT) typedef uint_least16_t pb_size_t; typedef int_least16_t pb_ssize_t;#else typedef uint_least8_t pb_size_t; typedef int_least8_t pb_ssize_t;#endif/* Data type used for storing sizes of struct fields * and array counts. */#if defined(PB_FIELD_32BIT) typedef uint32_t pb_size_t; typedef int32_t pb_ssize_t;#elif defined(PB_FIELD_16BIT) typedef uint_least16_t pb_size_t; typedef int_least16_t pb_ssize_t;#else typedef uint_least8_t pb_size_t; typedef int_least8_t pb_ssize_t;#endifstatic const pb_decoder_t PB_DECODERS[PB_LTYPES_COUNT] = { &pb_dec_bool, &pb_dec_varint, &pb_dec_uvarint, &pb_dec_svarint, &pb_dec_fixed32, &pb_dec_fixed64, &pb_dec_bytes, &pb_dec_string, &pb_dec_submessage, NULL, /* extensions */ &pb_dec_fixed_length_bytes};static bool checkreturn decode_static_field(pb_istream_t *stream, pb_wire_type_t wire_type, pb_field_iter_t *iter){ pb_type_t type; pb_decoder_t func; type = iter->pos->type; func = PB_DECODERS[PB_LTYPE(type)]; switch (PB_HTYPE(type)) { case PB_HTYPE_REQUIRED: return func(stream, iter->pos, iter->pData); case PB_HTYPE_OPTIONAL: if (iter->pSize != iter->pData) *(bool*)iter->pSize = true; return func(stream, iter->pos, iter->pData); case PB_HTYPE_REPEATED: if (wire_type == PB_WT_STRING && PB_LTYPE(type) <= PB_LTYPE_LAST_PACKABLE) { /* Packed array */ bool status = true; pb_size_t *size = (pb_size_t*)iter->pSize; pb_istream_t substream; if (!pb_make_string_substream(stream, &substream)) return false; while (substream.bytes_left > 0 && *size < iter->pos->array_size) { void *pItem = (char*)iter->pData + iter->pos->data_size * (*size); if (!func(&substream, iter->pos, pItem)) { status = false; break; } (*size)++; } if (substream.bytes_left != 0) PB_RETURN_ERROR(stream, "array overflow"); if (!pb_close_string_substream(stream, &substream)) return false; return status; } else { /* Repeated field */ pb_size_t *size = (pb_size_t*)iter->pSize; char *pItem = (char*)iter->pData + iter->pos->data_size * (*size); if ((*size)++ >= iter->pos->array_size) PB_RETURN_ERROR(stream, "array overflow"); return func(stream, iter->pos, pItem); } case PB_HTYPE_ONEOF: if (PB_LTYPE(type) == PB_LTYPE_SUBMESSAGE && *(pb_size_t*)iter->pSize != iter->pos->tag) { /* We memset to zero so that any callbacks are set to NULL. * This is because the callbacks might otherwise have values * from some other union field. */ memset(iter->pData, 0, iter->pos->data_size); pb_message_set_to_defaults((const pb_field_t*)iter->pos->ptr, iter->pData); } *(pb_size_t*)iter->pSize = iter->pos->tag; return func(stream, iter->pos, iter->pData); default: PB_RETURN_ERROR(stream, "invalid field type"); }}static const pb_decoder_t PB_DECODERS[PB_LTYPES_COUNT] = { &pb_dec_bool, &pb_dec_varint,赞赏
|
|
|---|---|
|
|
有大佬可以帮忙追回被骗的钱吗,差不多被骗了七万多,报酬好说
|
|
|
|


