-
-
[原创]安卓逆向基础知识之ARM汇编和so层动态调试
-
发表于: 2025-5-11 14:12 9015
-

在进行so层的动态调试前需要学习些知识点,比如说arm汇编,我们在用ida反编译so文件可以看到arm汇编指令,这个指令是CPU机器指令的助记符。这是什么意思呢?首先CPU机器指令其实也就是那由1和0组成的二进制,如果要我们通过CPU的机器指令来编程那是非常难且枯燥无聊了的,反正我是做不到。但我使用汇编代码来编程就还是可以编写些简单的程序的,嘿嘿!我们先来看一段反编译出来的简单的汇编代码:
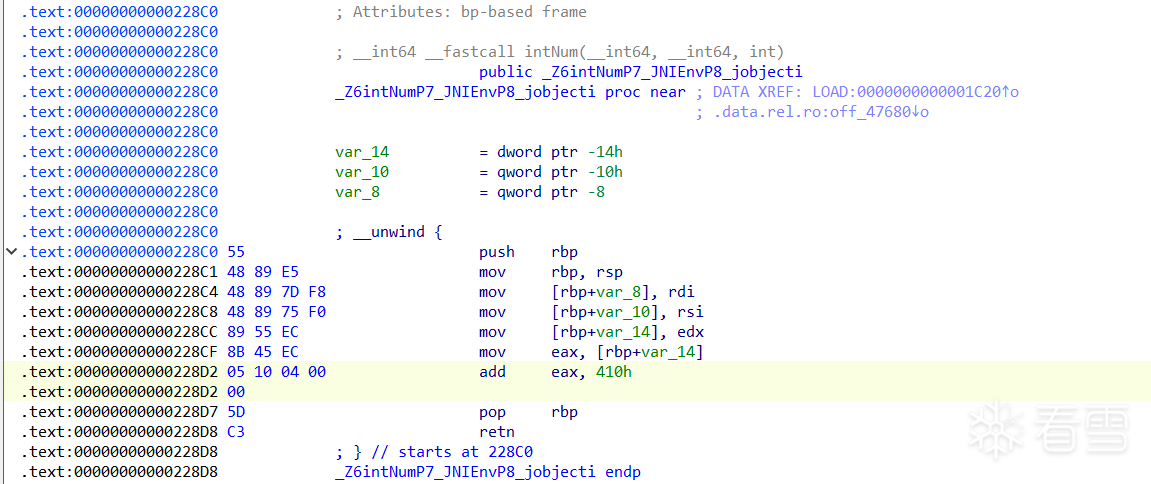
我们可以在图中看到汇编指令的左边有所对应的机器码,如push rbp这条指令所对应的机器码就是55,这个55是用十六进制表示的,它最终会被转换成二进制,也就是0和1,55占一个字节也就是8位,转换为二进制为01010101,而这串01010101就可以表示push rbp这段汇编指令出来。这里多提一嘴,从机器码01010101到汇编指令push rbp的过程就是反汇编,而从汇编指令到机器码的过程就是汇编。
arm的CPU是支持四种指令集的,分别是ARM32指令集(32-bit)、Thumb指令集(16-bit)、Thumb2指令集(16-bit&32-bit)、ARM64指令集(64-bit),但是ARM32的CPU是只支持前三种指令集的。在同一个函数中是不会出现多种指令集的,也就是某一个函数不会出现既有ARM32指令集又有Thumb指令集的情况。不过在不同的函数中可以,也就是这个函数是一个指令集,另一个函数是另外一个指令集的情况。Thumb2指令集大致情况如图所示:

在Thumb指令集中一条指令用两个字节就可以表示了,并且和arm指令集中用四个字节表示的效果是一样的。这时有些朋友可能会疑惑,那对比arm指令集节省了不少的字节,那为什么不都用Thumb指令集呢?其实原因很简单,因为有些东西并不能两个字节搞定,比如说异常处理,异常处理在arm的CPU中是要占四个字节的,遇到这种情况Thumb指令集就需要用两条Thumb指令去搞定异常处理,这么一来就需要用到两条指令,从而导致所花时间比起一条指令解决的arm指令集就更长了。所以后来就出现了Thumb2指令集,该指令集就有用两字节和四字节来表示指令,Thumb2 支持 16位和32位混合编码,处于两个字节和四个字节共存的状态。
不过怎么说Thumb2指令集的本质还是Thumb指令集,所以我们在对Thumb和Thumb2指令集进行hook时地址是需要加一的,而arm指令集则不需要,因为由LSB标识指令集状态,Thumb系地址末位为1。总之Hook 地址处理大概是这样的:
Thumb 函数地址:0x1000 → Hook 地址为 0x1001。
ARM 函数地址:0x2000 → Hook 地址为 0x2000。
这里多提一嘴,arm的CPU是向下兼容的,所以arm64的CPU依旧会支持这三种指令集。
ARM架构本质上是RISC,而RISC是精简指令集,指令复杂度是简单且单操作的,内存访问是仅通过 LDR/STR 指令实现的,寄存器使用一般通用寄存器数量多(如ARM32有16个)
因为精简指令减少晶体管数量和动态功耗,所以适合移动设备。X86的CPU是可以直接操作内存中的数据,但ARM的CPU是没法直接操作内存中的数据,就是因为ARM架构是精简指令集。
我们先来看两段arm汇编代码,第一段:

第二段:

这两段汇编代码中可以看到些看似一样却又有些不一样的指令,比如说ADD和ADDS这两种指令,这两种指令有什么区别吗?其实ADDS中的S就是指令后缀,ARM汇编是很喜欢给指令加后缀的,这样一来同一指令加不同的后缀就会变成不同的指令,但功能是差不多的啦!
下面罗列了 ARM 汇编指令中常见的后缀:
一、条件执行后缀(Condition Codes)
ARM 指令可通过条件后缀实现 条件执行(根据 CPSR 状态寄存器中的标志位决定是否执行指令):
示例:
二、数据操作后缀
这些后缀指定 操作的数据类型 或 内存访问模式:
示例:
三、标志位更新后缀
示例:
四、特殊操作后缀
五、协处理器操作后缀
六、浮点运算后缀(VFP/NEON)
指令后缀总结
说回正题,前面讲过ARM架构本质上是RISC,这也导致ARM的CPU是没法直接操作内存中的数据,但是CPU要操作内存中的数据又是刚需,那该怎么办呢?前面也提到过LDR/STR 是 ARM 内存访问的核心指令,所以ARM的CPU先把内存中的数据加载到寄存器中,这样CPU就可以操作寄存器中的数据,操作完成后再把寄存器中的数据存到内存中。
LDR是将内存中的数据加载到通用寄存器。STR是将通用寄存器中的数据存储到内存。这里多提一嘴,LDR/STR能处理的字节是一个字,一个字在arm32中是4字节,在arm64中是8字节,而在x86和IDA中一个字都是占两个字节,但是IDA会根据反汇编的目标架构动态调整“字”的显示,比如ARM模式显示4或8字节。接下来我们回归正题,ARM当中的寄存器数量是要比X86当中的寄存器数量要多的,arm32架构中一共有17个寄存器,而arm64架构中总共有34个寄存器。
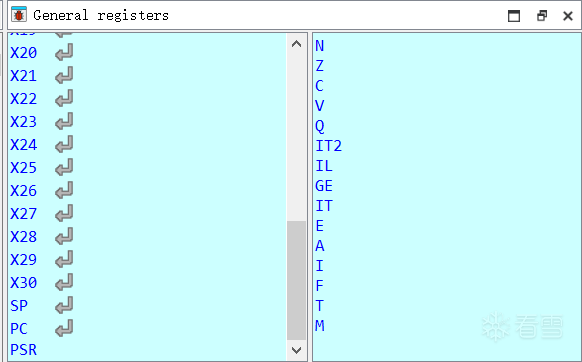
上图是arm64架构,左边是X0-X30 通用寄存器 以及 SP、PC、PSR 寄存器,下面大致讲解这些寄存器:
一、X0-X30 通用寄存器
二、特殊寄存器
上面的是比较枯燥的,所以我们大致模拟一下寄存器的使用场景,当ARM64指令调用函数时就会进行参数传递,在此过程中X0-X7 传递前8个参数,多余参数通过堆栈传递。当函数调用结束返回值的时候,X0 返回基本类型数据,X8 返回结构体地址。在 ARM64 函数调用规范中,有一套“寄存器保存” 规则,这套规则简单来说就是被调用者需保存 X19-X28,调用者需保存 X0-X18(若需保留值)。什么意思呢?其实就是当一个函数被调用时,若它需要使用 X19 - X28 寄存器,必须先将这些寄存器的原始值保存,通常会保存到堆栈。在函数执行结束前,再从堆栈中恢复这些寄存器的原始值。这样做是为了确保调用者在调用函数前后,X19 - X28 寄存器的值不受被调用函数影响。
X0 - X18 是 “调用者保存寄存器”。调用其他函数时,调用者若希望在函数调用后继续使用 X0 - X18 中的值,需自行负责保存,比如提前将值存到堆栈或其他安全位置。被调用函数无需关心这些寄存器的原始值,可直接使用。这样做是为了减轻被调用函数的负担,提高函数调用效率。
以下是栈帧管理:
这里再提一提条件执行,在ARM架构条件执行中,NZCV标志由CMP、ADDS等指令更新,用于控制条件分支,如B.EQ(相等时跳转)、B.NE(不相等时跳转)等指令的执行依赖这些标志的状态判断。
再讲讲ARM64 与 ARM32 的区别:
这里补充一个关于arm64寄存器的知识点,其实arm64寄存器除了X0到X30这种寄存器之外,还有W0到W30寄存器,而这两种寄存器的关系也十分简单,W0-W30 是 X0-X30 的低 32 位,两者共享同一物理寄存器,写入 W 寄存器时,X 寄存器的高 32 位会被清零,读取 W 寄存器时,仅访问低 32 位,高 32 位不参与运算。
在 ARM64 汇编中还有一种特殊的零寄存器WZR(32 位)和 XZR(64 位),当这两个寄存器作为源寄存器时值始终为零,举个例子:
而当 WZR 或 XZR 作为目标寄存器时,写入操作会被硬件忽略,这也举个例子:
除了W寄存器和X寄存器之外还有其他的寄存器,如果要用到浮点数运算那就需要V寄存器,ARM64架构提供 32 个浮点寄存器,命名为 V0 至 V31,每个寄存器宽度为 128 位。浮点运算所使用的指令支持 单精度(F32) 和 双精度(F64) 浮点运算,以下是浮点运算指令:
操作数可以是标量或向量。什么是标量和向量呢?标量就是单精度(32 位,用S系列寄存器表示)和双精度(64 位,用D系列寄存器表示),向量就是通过 SIMD(NEON 技术) 支持并行操作,比如同时处理 4 个单精度浮点数(4S)或 2 个双精度浮点数(2D),举个例子:
这些浮点寄存器可以通过不同的数据宽度后缀(如 B、H、S、D、Q)访问不同精度的数据。ARM64 的浮点/SIMD 寄存器支持多种数据宽度的访问方式,并非独立寄存器组,而是同一寄存器的不同视图:
除此之外浮点运算和整数运算还有一个区别,那就是需要进行类型转换,可以使用 FCVT 指令在不同精度之间转换。
ARM64架构和ARM32架构浮点寄存器使用的区别还是有不小的,在ARM32中Q0 是一个独立的 128 位寄存器,D0 是其低 64 位,S0 是 D0 的低 32 位,在ARM64中所有视图统一为 V0-V31,通过后缀指定数据宽度,没有独立的 Q0-Q31 寄存器组。
现在我们对寄存器有了一定的了解,接下来将讲解ARM汇编的寻址方式,第一种寻址方式寄存器寻址,这种方式直接使用寄存器中的值作为操作数,无需访问内存。
这种方式操作速度最快,仅涉及寄存器间的数据传输。一般适用于频繁的数据交换或临时值保存。
第二种寻址方式立即寻址,该方式操作数是直接编码在指令中的常量(立即数),就像下面的代码一样:
ARM 立即数必须符合“8 位常数 + 4 位循环右移”格式(例如 0xFF00 是合法的,因为可以表示为 0xFF << 8)。而非法立即数需通过多次指令或内存加载实现。
第三种寻址方式寄存器移位寻址,这种方式对源寄存器的值进行移位操作后作为操作数。支持四种移位类型,分别是以下四种:
(1) 逻辑左移(LSL, Logical Shift Left)
操作:将二进制位向左移动,低位补 0,高位溢出丢弃。
示例:
假设 r1 = 0b1011(4 位简化示例),左移 1 位后:
实际 ARM 环境:寄存器为 32 位,左移 1 位等效于乘以 2。例如:
(2) 逻辑右移(LSR, Logical Shift Right)
操作:将二进制位向右移动,高位补 0,低位溢出丢弃。
示例:
假设 r1 = 0b1100(4 位简化示例),右移 2 位后:
(3) 算术右移(ASR, Arithmetic Shift Right)
操作:保留符号位(最高位),其余位右移,高位补符号位。
示例:
假设 r1 = 0b1011(4 位有符号数,即十进制 -5),右移 1 位后:
(4) 循环右移(ROR, Rotate Right)
操作:将二进制位循环右移,最低位移出的位补到最高位。
示例:
假设 r1 = 0b1011(4 位简化示例),循环右移 1 位后:
这种方式能快速实现乘除运算(如 LSL #n 等效于乘 2n2n),也适用于位操作(如掩码提取、数据对齐)。
第四种寻址方式寄存器间接寻址,这种方式使用寄存器中的值作为内存地址,访问该地址处的数据。
其实这个可以理解为C 语言中的 int x = *p;
这种方式必须通过 ldr 或 str 指令访问内存,适用于动态内存操作(如指针遍历)。
第五种寻址方式基址变址寻址,这种方式是通过基址寄存器(Base Register)加偏移量(Offset)计算有效地址。
该种寻址方式还有两种变体:
前变址:先更新基址寄存器,再访问内存。
后变址:先访问内存,再更新基址寄存器。
这种方式常用于数组遍历、结构体成员访问。
第六种寻址方式为多寄存器寻址,该方式是单条指令批量操作多个寄存器。
模式:
IA(Increment After):操作后地址递增(默认模式)。
IB(Increment Before):操作前地址递增。
DA(Decrement After):操作后地址递减。
DB(Decrement Before):操作前地址递减。
这种方式常用于函数调用时批量保存/恢复寄存器(如 stmdb sp!, {r0-r12, lr})。
第七种方式为堆栈寻址,这种方式是基于堆栈指针(sp)的多寄存器操作,支持不同堆栈类型。
堆栈类型:
FD(Full Descending):堆栈向低地址增长(压栈时 sp 先减后存)。
ED(Empty Descending):堆栈向低地址增长(压栈时 sp 先存后减)。
FA/EA:类似逻辑,但方向不同。 这种方式常用于函数调用时保存上下文(如保存 lr 和局部变量)。
这里也多提一嘴,我们有时可以看到像这样的ARM汇编指令:
该指令中的**!**符号的作用是 自动更新基址寄存器(SP)的值,具体表现为:
示例分析
等效伪代码:
应用场景
寻址方式总结
! 符号在 ARM 存储多寄存器指令中,表示 基址寄存器在操作后自动更新。对于 stmfd sp!, {r1-r4},它确保栈指针 sp 在存储数据后指向新的栈顶位置,简化了堆栈管理的复杂性。
第八种寻址方式相对寻址,这种方式基于当前程序计数器(PC)的偏移量计算目标地址。
这种方式有以下特点:
偏移量为有符号数,范围受指令格式限制(如 Thumb 模式为 ±2048)。
支持位置无关代码(PIC)。
这种方式常用于条件分支、循环控制、函数调用(如 bl func)。
了解完了寻址方式,接下来聊聊一些常见的套路:
1、在ARM32函数调用中,被调用函数需保存并恢复 R4-R11 寄存器的值,以确保调用者的状态不被破坏。此外,若函数内部使用到 LR(链接寄存器),也需保存其值(例如通过压栈)。这一机制保证了函数返回后,调用者的寄存器和程序流程能正确恢复。而在arm64中被调用函数则是需要保存并恢复X19-X29寄存器的值,若被调用函数需要调用其他函数,需保存 LR(X30),通常通过 STP 指令压栈。
2、在ARM32中,SP(R13) 是专用的栈指针寄存器。通过递减SP的值(如 SUB SP, SP, #N),函数为局部变量分配栈空间;函数退出时需恢复SP(如 ADD SP, SP, #N)。这种机制实现了栈内存的高效管理,确保局部变量和函数调用的隔离性。而在arm64中SP(X31)寄存器专门用于栈指针寄存器,必须 16 字节对齐。通过 SUB SP, SP, #N 分配栈空间,N 需为 16 的倍数,函数退出前通过 ADD SP, SP, #N 恢复栈指针。
讲到这里我们来看一段arm64汇编代码:
我们可以看到首先通过SUB方法去把 SP 的值减去 0x40,通过这种方式对栈指针 SP 进行调整从而提升堆栈,也就是让栈顶指针向上提升 0x40 个字节。提升堆栈后通过STR命令将X21寄存器的值存到内存里,存放的位置为SP + 0x10 这个内存地址处,后续两次STR命令皆如此,第二行STR汇编代码把寄存器 X20 的值存到 SP + 0x20 处,把寄存器 X19 的值存到 SP + 0x28 处,第三行STR汇编代码把 X29 和 X30 的值分别存到 SP + 0x30 和 SP + 0x38 处,为什么0x28和0x38都是加8字节,因为 64 位寄存器占 8 个字节。如此便把X21、X20、X19、X29、X39寄存器中的值压入堆栈中,保存的寄存器包括 被调用者保存寄存器(X19-X21) 和 栈帧指针(X29)、返回地址(X30)。接下来就是通过ADD指令把 SP 的值加上 0x30 后赋给 X29。这样一来,X29 就指向了 SP + 0x30 这个地址,也就是把 X29 当作栈底指针。
我们继续看函数调用的最后,可以看到先是通过LDP命令将之前压入堆栈的值重新读取出来赋值给原本的寄存器,这样便把这些寄存器原本的值还给了它,恢复顺序与保存顺序相反,接下来通过 ADD SP 释放之前分配的0x40个字节栈空间,恢复 SP 到函数入口时的位置,最后通过RET汇编代码跳转到链接寄存器X30保存的返回地址,结束函数调用。
接下来我们讲解资源重定位,当程序在编译时无法确定字符串的实际加载位置,就需要依赖资源重定位。也可以说资源重定位是程序加载到内存时,根据实际基地址调整代码和数据中引用地址的过程。其核心目的是解决程序在不同内存位置运行时地址不固定的问题。
编译后的程序通常假设从固定基地址运行,但实际加载地址可能不同。若代码中直接使用绝对地址,实际运行时地址会失效。所以要记录需要修正的地址,然后通过 PC 相对寻址 或 重定位条目修正,在运行时动态计算实际地址。
我们来看一段ARM 32汇编代码,展示资源重定位的实现过程。代码通过 PC 相对寻址 动态计算字符串地址,并调用 printf 函数输出结果:
我们一行一行代码来看,首先是LDR R2, =(sResult - 0x738) ,此行代码是 编译时计算字符串与某指令的偏移量。sResult是字符串的编译时地址,0x738是ADD R2, PC, R2 指令的下一条指令地址。假设编译时地址为0x00001F88,那么偏移量是如此计算:
sResult - 0x738 = 0x1F88 - 0x738 = 0x1850(编译时固定值)
接下来是ADD R2, PC, R2 ; R2 = PC + 0x1850,这里提一点,在流水线效应下PC 指向当前指令地址 + 8,当前指令地址为 0x00000730,因此 PC = 0x730 + 8 = 0x738。所以实际地址为:
R2 = 0x738 + 0x1850 = 0x1F88(即字符串的实际运行时地址)
刚才提到了流水线效应,那什么是流水线效应呢?其实就是ARM 处理器采用 三级流水线 提升指令执行效率,一共有三个阶段,分别是取指、解码、执行。取指阶段是从内存中读取下一条指令到指令寄存器,所以在 ARM 状态下,PC 总指向当前指令地址 + 8,在Thumb 状态下,PC 总指向当前指令地址 + 4;解码阶段是解析指令的操作码和操作数,确定执行逻辑。执行阶段是执行指令的实际操作。所以在 ADD R2, PC, R2 指令执行时,PC 已提前指向后续指令(0x738)。
以上是arm32的资源重定位方式,前面提到 PC 指向当前指令地址 + 8,这是 ARM32 三级流水线的特性,其实ARM64 中 PC 的行为与 ARM32 类似,但地址计算通常依赖ADRP + ADD/LDR 指令组合,而非直接通过 LDR + ADD 操作。
ARM64 通过 PC 相对寻址 实现地址计算的关键指令如下:
ADRP:计算目标地址的页基地址(高 21 位)。
ADD 或 LDR:补充低 12 位地址。
访问全局变量 global_var示例:
我们再来看一段arm64的汇编代码:
ADRP指令用于计算符号 isOurApk_ptr 所在内存页的基地址,@PAGE 表示获取符号 isOurApk_ptr 的页基地址(高 21 位),并将其写入寄存器 X8。
ARM64 地址空间按 4KB 页对齐,ADRP 将当前 PC 值的页基地址与目标符号的页偏移相加,生成目标符号的页基地址。在程序加载时,链接器根据实际基地址修正 @PAGE 的页偏移,这样就可以确保 X8 指向正确的页。
LDR指令从内存加载数据到寄存器,@PAGEOFF 表示符号 isOurApk_ptr 在页内的低 12 位偏移。第二行代码就是将 X8(页基地址)与 @PAGEOFF(页内偏移)相加,形成完整地址,并从中加载数据到 X8。
第三行代码将X8 指向的地址加载 32 位数据 到 W8,而W8 存储的是 isOurApk_ptr 指针所指向的值。
通过 ADRP + LDR 组合,将符号 isOurApk_ptr 的地址从 编译时假设的地址 转换为 运行时实际地址,ADRP 处理高 21 位页基地址偏移,LDR 处理低 12 位页内偏移。
重定位表(如 .rela.dyn 和 .rela.plt)记录了需要修正的地址及其类型。在这里链接器生成重定位表(如 .rela.dyn),记录 @PAGE 和 @PAGEOFF 的修正信息,加载器根据实际基地址修正指令中的偏移量,使程序能正确访问内存。加载器的工作流程是先根据程序实际加载的基地址,计算目标符号的运行时地址,然后遍历重定位表,按类型修正指令中的偏移量。
动态链接 通过 GOT 和 PLT 减少启动开销,支持延迟绑定。全局偏移表GOT会存储外部符号(如全局变量、函数)的实际地址。当首次访问时,通过重定位动态解析地址并填充 GOT。过程链接表PLT能实现延迟绑定,减少启动开销。
PLT 桩代码先从 GOT 中读取函数地址,若地址未解析,触发动态链接器解析并更新 GOT,最后跳转到实际函数地址。
我们来模拟一下在动态库中访问全局变量 global_var的场景,以下是编译时生成的代码:
在运行时进行修正,假设程序加载到基地址 0x5500000000,实际 global_var 地址为 0x5500001000。那么重定位表条目应当如此:
加载器进行操作会修正 ADRP 指令的高 21 位偏移,使其指向 0x5500001000 的页基地址,然后修正 ADD 指令的低 12 位偏移,补全地址。
在 ARM64 中,执行某条指令时,PC 指向当前指令地址 + 8依旧与 ARM32 类似。
现在我们搞清楚了资源重定位,我们接下来了解ARM64 汇编中全局变量与静态变量的存储与访问,我们需要知道.bss 段存储未初始化或初始化为 0 的全局变量、静态变量,这种方式不占用可执行文件的实际磁盘空间,仅在加载到内存时分配空间并清零,这样一来也比较节省存储资源。
.data 段存储初始化且值不为 0 的全局变量、静态变量,包含变量的初始值,占用可执行文件的实际磁盘空间,这种方式比较适合需要显式初始化的数据,如 int global_var = 42;
全局变量会定义在函数外部,作用域为整个程序。静态变量在定义时使用 static 关键字,作用域为定义它的文件或函数。全局变量和静态变量的地址在编译时或通过重定位表动态计算确定,函数通过 LDR/STR 指令从内存加载或存储数据。
当函数需要多次操作全局变量的值,编译器可能将值加载到寄存器或栈中进行临时保存。
有一点要注意,全局变量和静态变量本身仍存储在 .bss 或 .data 段,栈仅用于临时保存其值的副本。将变量值保存到栈中是编译器的优化行为,并非变量本身的存储位置发生变化。
前面讲过在 ARM64 架构中前 8 个参数通过 X0-X7 传递,这里我们详细讲讲不同类型参数传递和返回值处理。
首先是基本数据类型,如果是基本数据类型作为函数参数那么就是和前面说的一样前 8 个参数通过 X0-X7 传递,我们来举个例子。
C 代码示例:
ARM64 汇编:
除了基本数据类型之外肯定少不了浮点型,而浮点型则是前 8 个浮点参数通过 V0-V7 传递,返回值通过 V0 返回。这里还是举个例子。
C 代码示例:
ARM64 汇编:
基本数据类型和浮点型都有了那自然少不了结构体,结构体≤16 字节的称为小结构体,而>16 字节的叫做大结构体。小结构体的结构体成员按顺序拆解到 X0-X7 或 V0-V7 寄存器,返回值通过 X0-X1 或 V0-V3 返回。
C 代码示例:
ARM64 汇编:
大结构体的结构体则是通过 隐式指针(调用者分配内存,地址通过 X8 传递)传递,返回值需调用者预先分配内存,地址通过 X8 传递。
C 代码示例:
ARM64 汇编:
结构体都讲了,那么数组自然是少不了的,数组作为指针传递(等同于传递首地址),若数组是结构体的一部分,按结构体规则处理。
C 代码示例:
ARM64 汇编:
除此之外函数传参一般都是混合类型参数,就是啥类型都可能会有,我们也来举个例子。
C 代码示例:
ARM64 汇编:
到此为止我们对arm汇编有了一定的了解,接下来我将对ARM32 和 ARM64 的主要指令集进行个总结。
ARM32指令集详解
1. 通用指令
2. 浮点与 SIMD 指令(VFP/NEON)
3. 系统与控制指令
ARM64(AArch64)指令集详解
1. 通用指令
2. 浮点与 SIMD 指令(NEON/Advanced SIMD)
3. 系统与控制指令
以上只是一些主要的指令集,如若有误,还请大佬指正。arm汇编我们算是讲完了,那么接下来就开始讲如何使用IDA进行动态调试吧。
关于IDA动态调试我们需要进行一些准备工作,不管是模拟器还是真机都需要先将IDA调试服务器push到其上面去,当你进入到IDA文件夹下的dbgsrv文件夹中就可以看到有不少的IDA调试服务器。
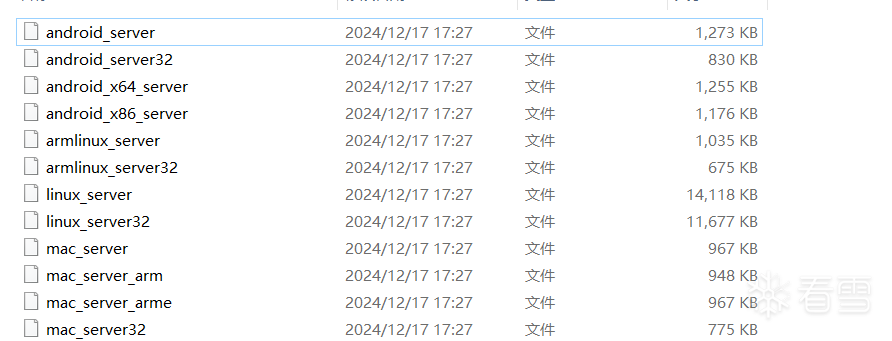
具体使用哪个就要根据你模拟器或者真机的架构选择对应的IDA调试服务器,比如手机是v8a架构就可以选择android_server,当然你那可能是android_server64,当然现在的真机大部分都是v8a架构的。
选择好架构对应的IDA调试服务器后,我们需要通过adb将IDA调试服务器给push到手机或者模拟器上,命令如下:
android_server这里需要是你IDA服务器的位置,当然你也可以在dbgsrv文件夹下直接这样运行,/data/local/tmp为你要push到的位置,一般服务器我都放这个位置,但其实存放位置随意,导入成功后最好是进行重命名,这样可以避免一些反调试,重命名完成后可以长按IDA服务器,点击属性,将权限从666更改为777。当我们把服务器push成功后,接下来我们要动态调试某个APP可以选择像之前一样添加可调试权限,也可以通过XAppDebug去hook要调试的APP,XAppDebug项目地址:
GitHub - Palatis/XAppDebug: toggle app debuggable
hook成功后就可以通过adb shell命令进入 Android 设备的 shell 环境,然后通过su命令切换到超级用户权限,接下来通过cd data/local/tmp 命令切换到存储IDA服务器的目录下,最后通过./android_service命令来启动IDA服务器,在启动的时候我们可以选择在该命令后面加上-p <端口号>来指定端口号,这样做可以一定程度上避免一些反调试手段。我们成功启动IDA服务之后,接下来就应该进行端口转发,可以使用以下命令进行端口转发:
成功完成端口转发后,就可以进行动态调试,动态调试分为两种模式启动,分别是以debug模式启动和以普通模式启动,我们先来尝试以普通模式启动,先进入IDA打开我们要调试的so文件,进入后点击左上的“debugger”选项,这时就会弹出“select debugger...”选项后点击,或者也可以直接按F9直接弹出如下弹窗:
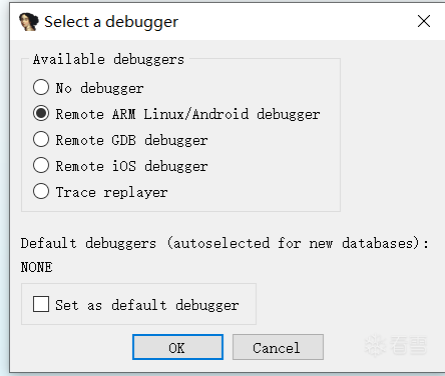
因为我们要调试so文件,所以选择"Remote ARM Linux/Android debugger"选项,如果要将该选项所使用的调试器设置为默认调试器就可以勾选“Set as default debugger”,最后点击OK即可。
再次点击“debugger”选项你就会发现当中选项变多了,接下来还要配置点东西,在“debugger”选项下选择“process options...”选项,这时就需要配置主机名和端口号:
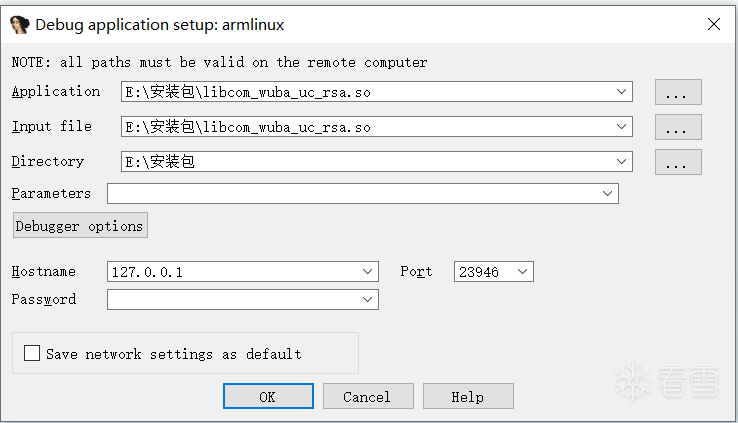
主机名选择127.0.0.1即可,端口号默认23946,如果指定了其他端口号就需要修改为指定的端口号。配置好后就可以点击“Attach to process”选项,点击后会显示模拟器/真机中运行的进程,这时直接搜索我们要附加的进程的包名,直接选择Name为包名的那个点击 ok 打开即可。普通模式配置流程大致如此,其实我不咋爱用动态调试,因为反调试手段贼多而且问题也特别多,我还是用frida进行hook用的更多,我再跟大伙聊聊以debug模式进行动态调试,为什么会有debug模式的动态调试呢?因为程序中有的代码只在加载阶段会执行,有的参数只在加载阶段会生成,加载过一次之后就不再会执行了,所以就有了通过debug模式去挂起app。
debug模式启动就需要在端口转发之后运行命令:
运行以上命令后就通过IDA附加要调试APP的进程,在执行接下来的命令之前我们需要先获取进程的PID,可以使用以下命令:
获取到进程的PID后,我们就需要打开DDMS查看应用端口8700,打开DDMS后就可以运行以下命令:
命令中的PID是我们前面获取的APP进程的PID,接下来IDA中运行程序,然后再在命令行中执行以下命令:
如果运行报致命错误:无法附加到目标 VM,或者遇到其他问题,也可以试着先运行jdb命令再F9运行程序,如果还不行就试试先运行jdb命令进行连接然后再快速使用ida附加到进程,慢了的话应用可能会跑起来。
我还是说一下比较好,我在使用动态调试的时候遇到了不少的问题,而且反调试手段也颇多,我还是推荐尝试去使用frida,效果不比这个差的,甚至效果可能还会更好。
| 后缀 | 全称 | 触发条件 | 典型应用场景 |
|---|---|---|---|
EQ |
Equal | Z=1(结果为零) | 比较相等后的跳转或操作 |
NE |
Not Equal | Z=0(结果非零) | 循环退出条件判断 |
CS/HS |
Carry Set / Higher or Same | C=1(进位标志置位或无符号数大于等于) | 无符号数比较后的分支 |
CC/LO |
Carry Clear / Lower | C=0(进位标志清零或无符号数小于) | 无符号数小于时的操作 |
MI |
Minus | N=1(结果为负数) | 负数处理逻辑 |
PL |
Plus | N=0(结果非负) | 非负数条件操作 |
VS |
Overflow Set | V=1(有符号溢出) | 溢出错误处理 |
VC |
Overflow Clear | V=0(无符号溢出) | 安全运算检查 |
HI |
Higher | C=1 且 Z=0(无符号数大于) | 无符号数的大于判断 |
LS |
Lower or Same | C=0 或 Z=1(无符号数小于等于) | 无符号数的循环终止条件 |
GE |
Greater or Equal | N=V(有符号数大于等于) | 有符号数比较后的分支 |
LT |
Less Than | N≠V(有符号数小于) | 有符号数的小于判断 |
GT |
Greater Than | Z=0 且 N=V(有符号数大于) | 有符号数的大于判断 |
LE |
Less or Equal | Z=1 或 N≠V(有符号数小于等于) | 有符号数的循环终止条件 |
ADDEQ R0, R1, R2 @ 当 Z=1 时执行 R0 = R1 + R2BNE loop @ 当 Z=0 时跳转到 loop 标签ADDEQ R0, R1, R2 @ 当 Z=1 时执行 R0 = R1 + R2BNE loop @ 当 Z=0 时跳转到 loop 标签| 后缀 | 含义 | 用途 |
|---|---|---|
B |
Byte | 操作 8 位数据(如 LDRB, STRB) |
H |
Halfword | 操作 16 位数据(如 LDRH, STRH) |
SB |
Signed Byte | 加载有符号 8 位数据(如 LDRSB) |
SH |
Signed Halfword | 加载有符号 16 位数据(如 LDRSH) |
T |
User Mode (Translated) | 在用户模式下访问内存(如 LDRT, STRT) |
D |
Doubleword | 操作 64 位数据(ARMv8+,如 LDP, STP) |
LDRB R0, [R1] @ 从 R1 地址加载 8 位数据到 R0(高位补零)LDRSH R2, [R3] @ 从 R3 地址加载 16 位有符号数据到 R2LDRB R0, [R1] @ 从 R1 地址加载 8 位数据到 R0(高位补零)LDRSH R2, [R3] @ 从 R3 地址加载 16 位有符号数据到 R2| 后缀 | 作用 | 典型指令 |
|---|---|---|
S |
更新 CPSR 中的标志位(Z, N, C, V) | ADDS, SUBS |
! |
更新基址寄存器(写回地址) | LDR R0, [R1, #4]! |
ADDS R0, R1, R2 @ R0 = R1 + R2,并更新 CPSR 标志LDMIA R0!, {R1-R3} @ 从 R0 加载数据到 R1-R3,R0 自动递增ADDS R0, R1, R2 @ R0 = R1 + R2,并更新 CPSR 标志LDMIA R0!, {R1-R3} @ 从 R0 加载数据到 R1-R3,R0 自动递增| 后缀 | 用途 | 示例指令 |
|---|---|---|
L |
长跳转(用于 BL 指令,保存返回地址到 LR) |
BL subroutine |
X |
交换指令集模式(如 ARM ↔ Thumb) | BX LR |
W |
32位操作(ARMv8,如 ADDW) |
ADDW R0, R1, #42 |
N |
否定条件(仅限 Thumb-2) | IT NE |
| 后缀 | 用途 | 示例指令 |
|---|---|---|
P |
协处理器数据传输(如 MCR, MRC) |
MCR p15, 0, R0, c1, c0, 0 |
L |
协处理器加载/存储(如 LDC, STC) |
LDC p2, c3, [R0] |
| 后缀 | 用途 | 示例指令 |
|---|---|---|
F32 |
单精度浮点操作(32位) | VADD.F32 S0, S1, S2 |
F64 |
双精度浮点操作(64位) | VMOV.F64 D0, #3.14 |
I8/I16 |
整数向量操作(8/16位) | VADD.I8 Q0, Q1, Q2 |
| 后缀类型 | 核心功能 |
|---|---|
| 条件执行后缀 | 根据标志位决定是否执行指令 |
| 数据操作后缀 | 指定操作的数据类型或内存模式 |
| 标志位更新后缀 | 更新状态寄存器或基址寄存器 |
| 特殊操作后缀 | 支持长跳转、模式切换等高级操作 |
| 协处理器后缀 | 控制协处理器行为 |
| 浮点运算后缀 | 定义浮点或向量运算的数据类型 |
| 寄存器 | 名称/用途 | 详细说明 |
|---|---|---|
| X0-X7 | 参数/返回值寄存器 | 用于函数调用时传递参数(前8个参数),X0 同时用于函数返回值。 |
| X8 | 间接结果寄存器 | 当函数返回结构体等较大数据时,X8 保存返回结构的地址。 |
| X9-X15 | 临时寄存器 | 临时存储数据,调用者无需保存,函数调用后可能被覆盖。 |
| X16-X17 | 平台专用寄存器(IP0/IP1) | 内部过程调用(Intra-Procedure Call)临时寄存器,通常由链接器或编译器使用。 |
| X18 | 平台保留寄存器 | 保留给操作系统或特定平台使用,应用程序不应修改。 |
| X19-X28 | 被调用者保存寄存器 | 函数调用时,若需使用这些寄存器,被调用者必须保存其原始值并在返回前恢复。 |
| X29 | 帧指针(FP) | 指向当前函数的栈帧基址,用于调试和栈回溯。 |
| X30 | 链接寄存器(LR) | 保存函数返回地址(如 BL 指令的返回地址)。 |
| 寄存器 | 全称 | 详细说明 |
|---|---|---|
| SP | 堆栈指针(Stack Pointer) | 指向当前栈顶地址,用于函数调用时的局部变量分配和寄存器保存。 |
| PC | 程序计数器(Program Counter) | 指向当前执行指令的地址。在 ARM 中不可直接修改,但可通过分支指令(如 B、BL)间接控制。 |
| PSR | 程序状态寄存器(Program Status Register) | 包含处理器状态信息,ARM64 中分为多个专用寄存器: - NZCV: 条件标志(Negative, Zero, Carry, oVerflow) - DAIF: 中断屏蔽标志(Debug, SError, IRQ, FIQ) - CurrentEL: 当前异常等级(EL0-EL3) |
SUB SP, SP, #16 @ 分配16字节栈空间STR X29, [SP, #8] @ 保存帧指针ADD X29, SP, #8 @ 设置新帧指针...LDR X29, [SP, #8] @ 恢复帧指针ADD SP, SP, #16 @ 释放栈空间RET @ 返回(使用X30中的地址)SUB SP, SP, #16 @ 分配16字节栈空间STR X29, [SP, #8] @ 保存帧指针ADD X29, SP, #8 @ 设置新帧指针...LDR X29, [SP, #8] @ 恢复帧指针ADD SP, SP, #16 @ 释放栈空间RET @ 返回(使用X30中的地址)| 特性 | ARM64(AArch64) | ARM32(AArch32) |
|---|---|---|
| 寄存器位数 | 64位(X0-X30) | 32位(R0-R15) |
| 链接寄存器 | X30(LR) | R14(LR) |
| 程序计数器 | PC 不可直接访问 | PC 为 R15,可直接修改 |
| 状态寄存器 | 分解为 NZCV、DAIF 等专用寄存器 | CPSR(单一程序状态寄存器) |
ADD W0, W1, WZR ; W0 = W1 + 0 → 等价于 MOV W0, W1SUB X2, X3, XZR ; X2 = X3 - 0 → 等价于 MOV X2, X3ADD W0, W1, WZR ; W0 = W1 + 0 → 等价于 MOV W0, W1SUB X2, X3, XZR ; X2 = X3 - 0 → 等价于 MOV X2, X3MOV WZR, W1 ; 无效操作,WZR 的值仍为 0STR X0, [XZR] ; 尝试写入内存地址 0,通常触发异常(取决于系统配置)MOV WZR, W1 ; 无效操作,WZR 的值仍为 0STR X0, [XZR] ; 尝试写入内存地址 0,通常触发异常(取决于系统配置)| 指令 | 功能 | 示例 |
|---|---|---|
FADD |
浮点加法 | FADD S0, S1, S2 |
FSUB |
浮点减法 | FSUB D0, D1, D2 |
FMUL |
浮点乘法 | FMUL S3, S4, S5 |
FDIV |
浮点除法 | FDIV D3, D4, D5 |
FABS |
取绝对值 | FABS S6, S7 |
FNEG |
取反 | FNEG D6, D7 |
FSQRT |
平方根 | FSQRT S8, S9 |
FCMP |
浮点比较 | FCMP S10, S11 |
FMOV |
浮点数移动 | FMOV D8, D9 |
FADD V0.4S, V1.4S, V2.4S ; 并行计算 4 个单精度浮点数的加法FMUL D0, D1, D2 ; 双精度浮点数乘法FADD V0.4S, V1.4S, V2.4S ; 并行计算 4 个单精度浮点数的加法FMUL D0, D1, D2 ; 双精度浮点数乘法| 后缀 | 数据宽度 | 描述 | 示例指令 |
|---|---|---|---|
| Q | 128 位 | 访问整个 128 位寄存器 | ADD V0.Q, V1.Q, V2.Q |
| D | 64 位 | 访问寄存器的低 64 位 | FMUL D0, D1, D2 |
| S | 32 位 | 访问寄存器的低 32 位 | FADD S0, S1, S2 |
| H | 16 位 | 访问寄存器的低 16 位 | FCVT H0, S1 |
| B | 8 位 | 访问寄存器的低 8 位 | LD1 {B0}, [X0] |
FCVT H0, S1 ; 将 S1 的单精度浮点数转换为半精度(H0)FCVT D0, S1 ; 将 S1 的单精度浮点数转换为双精度(D0)FCVT H0, S1 ; 将 S1 的单精度浮点数转换为半精度(H0)FCVT D0, S1 ; 将 S1 的单精度浮点数转换为双精度(D0)mov r1, r2 ; 将 r2 的值复制到 r1mov r1, r2 ; 将 r2 的值复制到 r1mov r0, #0xFF00 ; 将立即数 0xFF00 加载到 r0mov r0, #0xFF00 ; 将立即数 0xFF00 加载到 r0mov r0, r1, lsl #1 ; 将 r1 的值左移 1 位后存入 r0mov r0, r1, lsl #1 ; 将 r1 的值左移 1 位后存入 r0原始值: 1 0 1 1 原始值: 1 0 1 1 左移 1 位:0 1 1 0 (最高位 1 被丢弃,最低位补 0) 左移 1 位:0 1 1 0 (最高位 1 被丢弃,最低位补 0) 结果:r0 = 0b0110(即 6) 结果:r0 = 0b0110(即 6) r1 = 0x0000000F(十进制 15) r1 = 0x0000000F(十进制 15) r0 = r1, lsl #1 → r0 = 0x0000001E(十进制 30) r0 = r1, lsl #1 → r0 = 0x0000001E(十进制 30) mov r0, r1, lsr #2 ; 将 r1 的值右移 2 位后存入 r0mov r0, r1, lsr #2 ; 将 r1 的值右移 2 位后存入 r0原始值: 1 1 0 0 原始值: 1 1 0 0 右移 2 位:0 0 1 1 (最低两位 00 被丢弃,高位补 0) 右移 2 位:0 0 1 1 (最低两位 00 被丢弃,高位补 0) 结果:r0 = 0b0011(即 3) 结果:r0 = 0b0011(即 3) mov r0, r1, asr #1 ; 将 r1 的值算术右移 1 位后存入 r0mov r0, r1, asr #1 ; 将 r1 的值算术右移 1 位后存入 r0原始值: 1 0 1 1 原始值: 1 0 1 1 右移 1 位:1 1 0 1 (符号位 1 被保留,低位 1 丢弃) 右移 1 位:1 1 0 1 (符号位 1 被保留,低位 1 丢弃) 结果:r0 = 0b1101(即十进制 -3) 结果:r0 = 0b1101(即十进制 -3) mov r0, r1, ror #1 ; 将 r1 的值循环右移 1 位后存入 r0mov r0, r1, ror #1 ; 将 r1 的值循环右移 1 位后存入 r0原始值: 1 0 1 1 原始值: 1 0 1 1 循环右移 1 位:1 1 0 1 (最低位 1 移到最高位) 循环右移 1 位:1 1 0 1 (最低位 1 移到最高位) 结果:r0 = 0b1101(即 13) 结果:r0 = 0b1101(即 13) ldr r1, [r2] ; 将 r2 指向的内存地址的值加载到 r1ldr r1, [r2] ; 将 r2 指向的内存地址的值加载到 r1ldr r1, [r2, #4] ; 访问 r2 + 4 地址处的值ldr r1, [r2, #4] ; 访问 r2 + 4 地址处的值ldr r1, [r2, #4]! ; 等效于 r2 = r2 + 4,然后 r1 = [r2]ldr r1, [r2, #4]! ; 等效于 r2 = r2 + 4,然后 r1 = [r2]ldr r1, [r2], #4 ; 先 r1 = [r2],然后 r2 = r2 + 4ldr r1, [r2], #4 ; 先 r1 = [r2],然后 r2 = r2 + 4ldmia r11, {r2-r7, r12} ; 从 r11 指向的地址连续加载数据到多个寄存器ldmia r11, {r2-r7, r12} ; 从 r11 指向的地址连续加载数据到多个寄存器stmfd sp!, {r2-r7, lr} ; 将寄存器压入满递减堆栈(ARM 默认)stmfd sp!, {r2-r7, lr} ; 将寄存器压入满递减堆栈(ARM 默认)stmfd sp!, {r1-r4}stmfd sp!, {r1-r4}stmfd sp!, {r1-r4} ; 存储前 sp -= 16,存储 r1-r4,sp 更新为新地址stmfd sp!, {r1-r4} ; 存储前 sp -= 16,存储 r1-r4,sp 更新为新地址sp = sp - 16; // 预递减sp = sp - 16; // 预递减*(sp + 0) = r1; // 存储 r1*(sp + 0) = r1; // 存储 r1*(sp + 4) = r2; // 存储 r2*(sp + 4) = r2; // 存储 r2*(sp + 8) = r3; // 存储 r3*(sp + 8) = r3; // 存储 r3*(sp + 12) = r4; // 存储 r4*(sp + 12) = r4; // 存储 r4sp = sp; // 由于有 `!`,sp 已更新为递减后的地址sp = sp; // 由于有 `!`,sp 已更新为递减后的地址beq flag ; 若条件满足,跳转到标签 flag 处flag: ; 目标地址 = PC + 偏移量(由汇编器自动计算)beq flag ; 若条件满足,跳转到标签 flag 处flag: ; 目标地址 = PC + 偏移量(由汇编器自动计算).text:0000000000005318 ; jint JNI_OnLoad(JavaVM *vm, void *reserved).text:0000000000005318 EXPORT JNI_OnLoad.text:0000000000005318 JNI_OnLoad ; DATA XREF: LOAD:0000000000000918↑o.text:0000000000005318.text:0000000000005318 var_30 = -0x30.text:0000000000005318 var_28 = -0x28.text:0000000000005318 var_20 = -0x20.text:0000000000005318 var_10 = -0x10.text:0000000000005318 var_8 = -8.text:0000000000005318 var_s0 = 0.text:0000000000005318 var_s8 = 8.text:0000000000005318.text:0000000000005318 ; __unwind {.text:0000000000005318 SUB SP, SP, #0x40.text:000000000000531C STR X21, [SP,#0x30+var_20].text:0000000000005320 STP X20, X19, [SP,#0x30+var_10].text:0000000000005324 STP X29, X30, [SP,#0x30+var_s0].text:0000000000005328 ADD X29, SP, #0x30………….text:00000000000053C0 LDP X29, X30, [SP,#0x30+var_s0].text:00000000000053C4 LDP X20, X19, [SP,#0x30+var_10].text:00000000000053C8 LDR X21, [SP,#0x30+var_20].text:00000000000053CC ADD SP, SP, #0x40 ; '@'.text:00000000000053D0 RET.text:0000000000005318 ; jint JNI_OnLoad(JavaVM *vm, void *reserved).text:0000000000005318 EXPORT JNI_OnLoad.text:0000000000005318 JNI_OnLoad ; DATA XREF: LOAD:0000000000000918↑o.text:0000000000005318.text:0000000000005318 var_30 = -0x30.text:0000000000005318 var_28 = -0x28.text:0000000000005318 var_20 = -0x20.text:0000000000005318 var_10 = -0x10.text:0000000000005318 var_8 = -8.text:0000000000005318 var_s0 = 0.text:0000000000005318 var_s8 = 8.text:0000000000005318.text:0000000000005318 ; __unwind {.text:0000000000005318 SUB SP, SP, #0x40.text:000000000000531C STR X21, [SP,#0x30+var_20].text:0000000000005320 STP X20, X19, [SP,#0x30+var_10].text:0000000000005324 STP X29, X30, [SP,#0x30+var_s0].text:0000000000005328 ADD X29, SP, #0x30………….text:00000000000053C0 LDP X29, X30, [SP,#0x30+var_s0].text:00000000000053C4 LDP X20, X19, [SP,#0x30+var_10].text:00000000000053C8 LDR X21, [SP,#0x30+var_20].text:00000000000053CC ADD SP, SP, #0x40 ; '@'.text:00000000000053D0 RET; 代码段 (.text).text:0000072C LDR R2, =(sResult - 0x738) ; 加载字符串偏移量到 R2.text:00000730 ADD R2, PC, R2 ; 计算字符串实际地址:R2 = PC + 偏移量.text:00000734 MOV R0, R2 ; R0 = 字符串地址("Result: %d").text:00000738 MOV R1, #42 ; R1 = 要输出的数值(示例值 42).text:0000073C BL printf ; 调用 printf 函数.text:00000740 ... ; 后续代码; 只读数据段 (.rodata).rodata:00001F88 sResult DCB "Result: %d", 0 ; 字符串定义; 代码段 (.text).text:0000072C LDR R2, =(sResult - 0x738) ; 加载字符串偏移量到 R2.text:00000730 ADD R2, PC, R2 ; 计算字符串实际地址:R2 = PC + 偏移量.text:00000734 MOV R0, R2 ; R0 = 字符串地址("Result: %d").text:00000738 MOV R1, #42 ; R1 = 要输出的数值(示例值 42).text:0000073C BL printf ; 调用 printf 函数.text:00000740 ... ; 后续代码; 只读数据段 (.rodata).rodata:00001F88 sResult DCB "Result: %d", 0 ; 字符串定义ADRP X0, target_label ; X0 = (PC 的页基地址) + (target_label 的页偏移)ADRP X0, target_label ; X0 = (PC 的页基地址) + (target_label 的页偏移)ADD X0, X0, :lo12:target_label ; 组合完整地址LDR X1, [X0] ; 加载目标数据ADD X0, X0, :lo12:target_label ; 组合完整地址LDR X1, [X0] ; 加载目标数据ADRP X0, global_var ; 获取 global_var 的页基地址(高 21 位)ADD X0, X0, :lo12:global_var ; 补全低 12 位地址LDR X1, [X0] ; 加载 global_var 的值到 X1ADRP X0, global_var ; 获取 global_var 的页基地址(高 21 位)赞赏
|
|
|---|---|
|
|
请问你有没有尝试在安卓15去动态调试app,我这边一直频繁报信号,最后ida不断循环执行一些指令
最后于 2025-5-13 09:01
被onlythis编辑
,原因:
|
|
|
我用的是安卓13的系统,虽然也经常出问题,但我没遇到过你所说的问题,或许可以尝试使用低版本的系统进行尝试,没有真机可以试着用模拟器看看,动态调试确实经常遇到问题。 |
|
|
|


- [原创]安卓逆向基础知识之ARM汇编和so层动态调试 9016
- [原创]安卓逆向基础知识之JNI开发与so层逆向基础 60428
- [原创]安卓逆向基础知识之加解密算法与Hook基础 45968
- [原创]安卓逆向基础知识之动态调试以及安卓逆向的那些常规手段 15456
- [原创]安卓逆向基础知识之安卓开发与逆向基础 13056
