现在企业 app 基本上都是 ollvm 平坦化,研究还原这玩意也是大势所趋。废话不多说,这篇文章主要是使用 unicorn 还原 ollvm 的执行流。
1、获取所有的真实块
2、获取真实块之间的运行流程
3、还原实际工作流程
下面是经典老图(来自于e7dK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6K6k6h3y4#2M7X3W2@1P5g2)9J5k6i4c8W2L8X3y4W2L8Y4c8Q4x3X3g2U0L8$3#2Q4x3V1k6A6L8X3c8W2P5q4)9J5k6i4m8Z5M7q4)9J5c8X3u0D9L8$3N6Q4x3V1k6E0M7$3N6Q4x3V1j5I4x3e0t1`.)

这里我们主要关注真实块部分,其余的分发器和处理器都是 ollvm 中间生成的,并不是程序原本的运作流程。上图中的 ollvm 是标准的 ollvm,可以明显的发现所有的真实块都会跳转到预处理器块。但是现在基本都会魔改 ollvm 把这个预处理器给去除,或者说可能有多个预处理器,而且真实块也不一定会跳转到预处理器,也有直接跳转到到主分发器的。
具体情况具体分析,下图是没有预处理器的 ollvm。

这里是所有的真实块都会跳转到主分发器,那么可以考虑将所有主分发器的前驱节点(序言块除外)当做真实块。
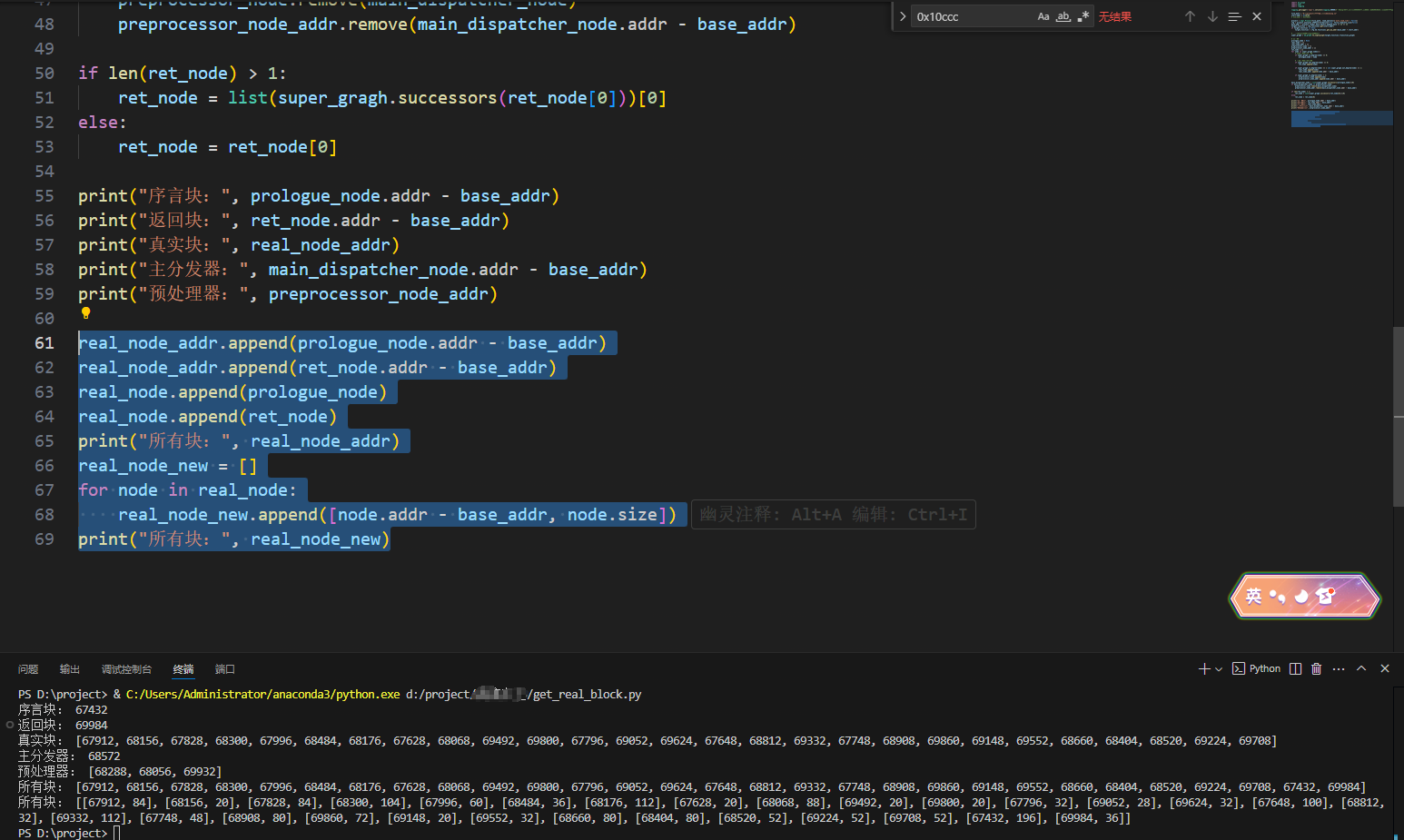
这里笔者使用 angr 获取真实块,也可以使用 IDApython 获取。载入文件到 angr,然后使用 angr 的analyses 模块获取 CFG 图,但是 angr 获取到的 CFG 图与 IDA 中看到的有点区别,可以使用3e9K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6Y4K9i4c8Z5N6h3u0Q4x3X3g2U0L8$3#2Q4x3V1k6U0M7e0j5%4y4o6x3#2x3o6f1J5z5g2)9J5c8X3c8W2k6X3I4S2N6l9`.`.里的 am_graph.py 转换。
接下来是识别所有块的类型
这里的返回块判断后使用前驱节点是考虑到出度为 0 的返回块除了 ret 外还有堆栈检查
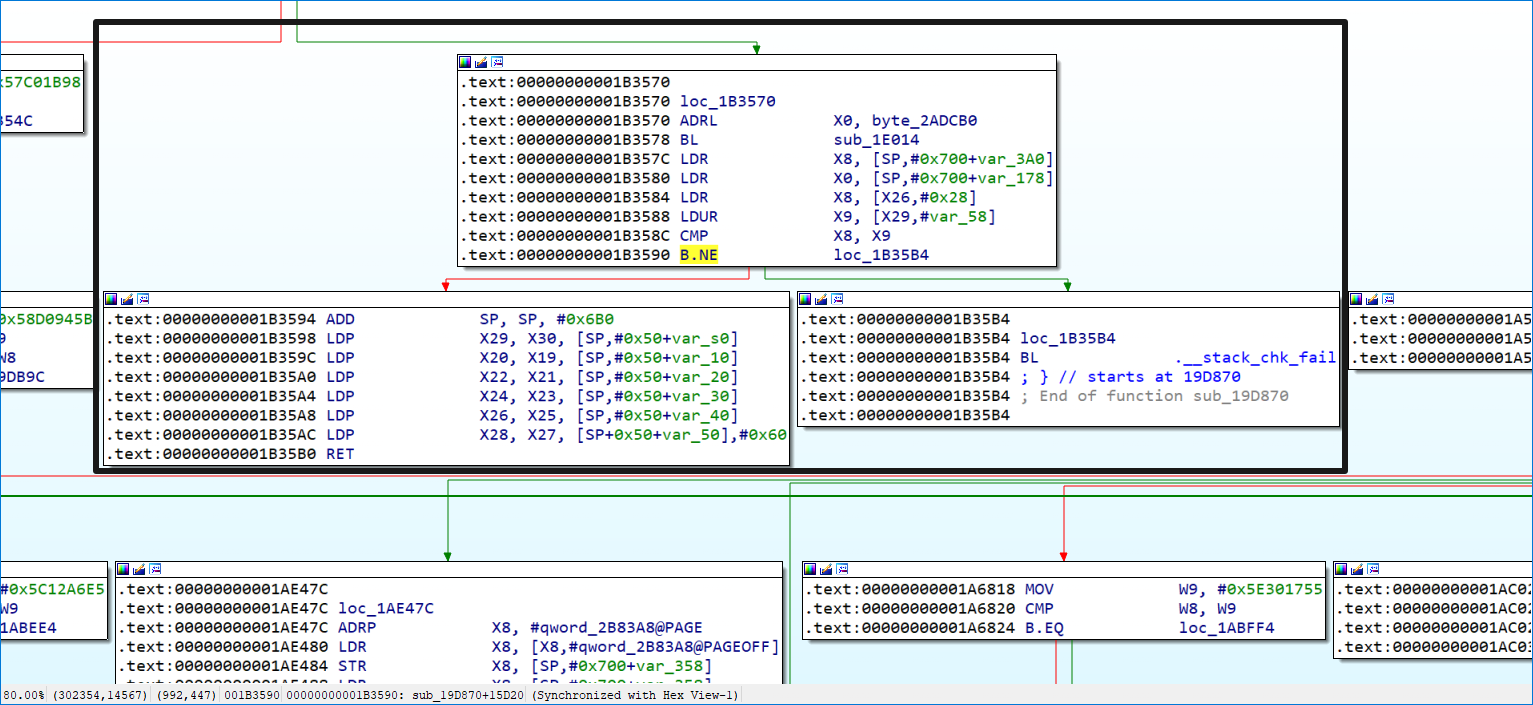
如果没有堆栈检查的情况,返回块只有一个,这里返回块的前驱节点是子分发器,不能使用。
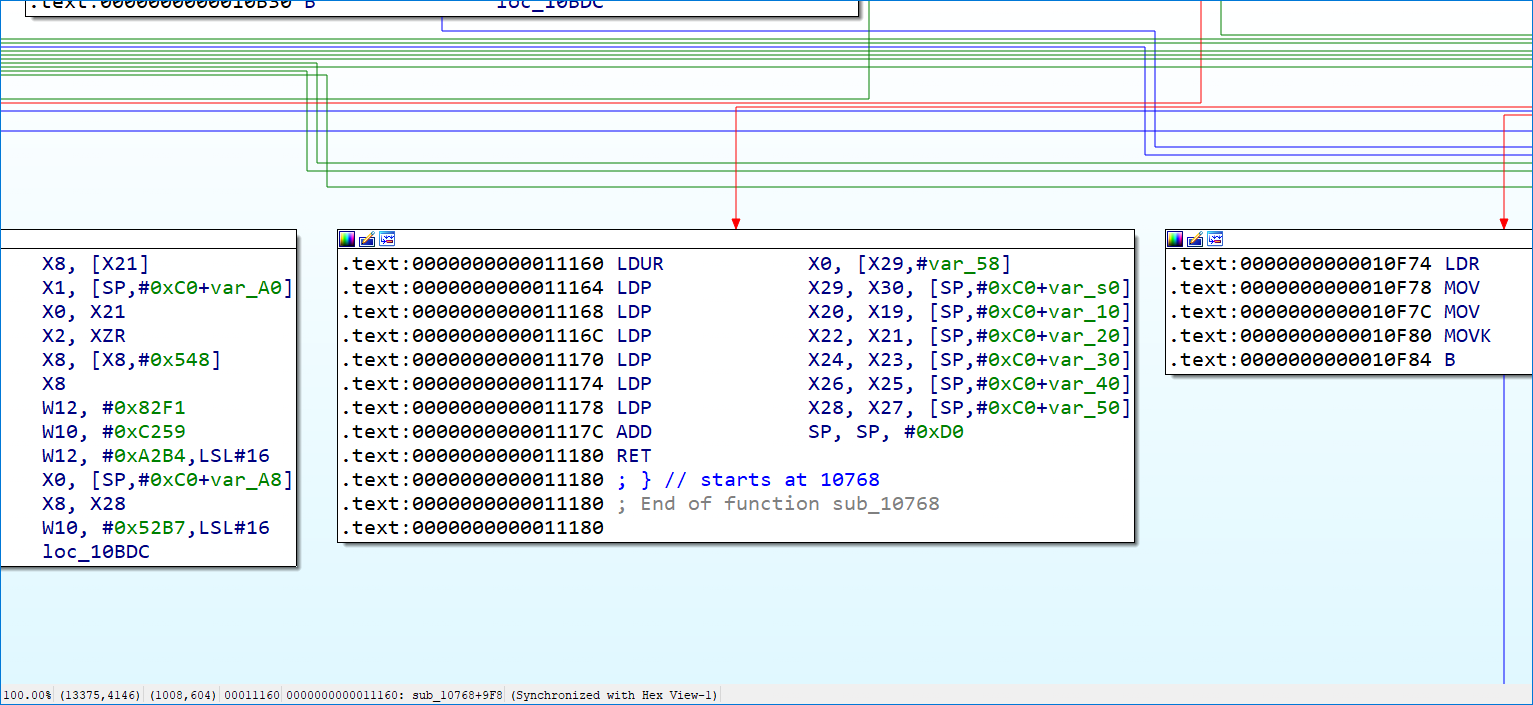
下面这个里面看起来是有三个预处理器,而且真实块也不一定会跳转到预处理器,也可能是跳转到主分发器。
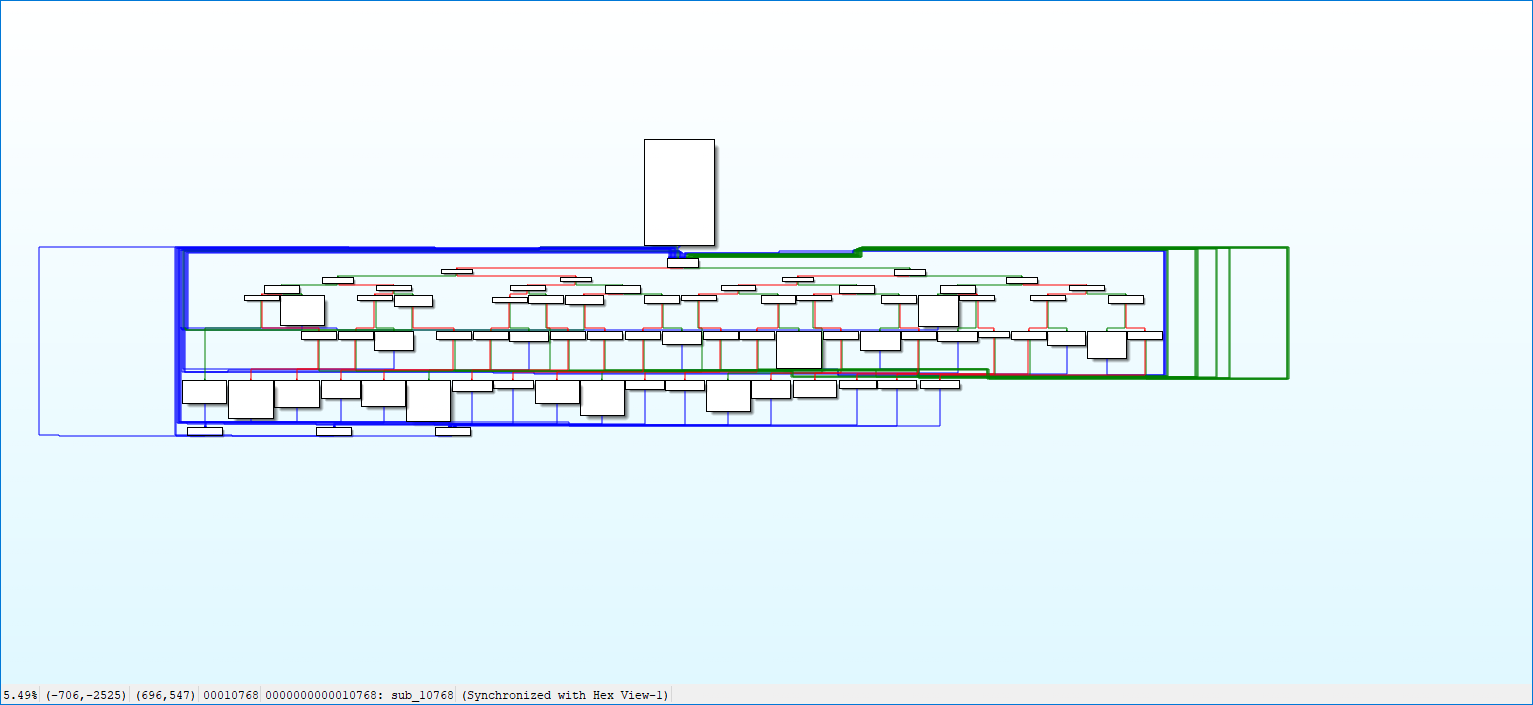
这里通过观察其实可以发现以下特征:
主分发器的特征是入度很多,出度为 2(分到两个子分发器中)
子分发器的特征是入度为 1,出度为 2
预处理器的特征是入度大于 2,出度为 1(跳转到主分发器)
返回块的特征是没有出度
序言块的特征是没有入度,也不用分析,就在函数起始位置
真实块的特征是入度为 1,出度为 1
真实块里面也不一定是真正的程序流程使用到的指令,但是可以知道入度为 1,出度为 1 这个特征里面一定会包含真正的流程。根据这个特征,稍微修改一下上面的脚本即可。
自此拿到所有的真实块
这里使用 unicorn 模拟执行来拿到真实块之间的执行流。为什么不用 angr?(有可能是我太菜了不会用)因为笔者在使用 angr 进行还原时,会被 angr 的符号变量干扰。例如图中的第一个分支:
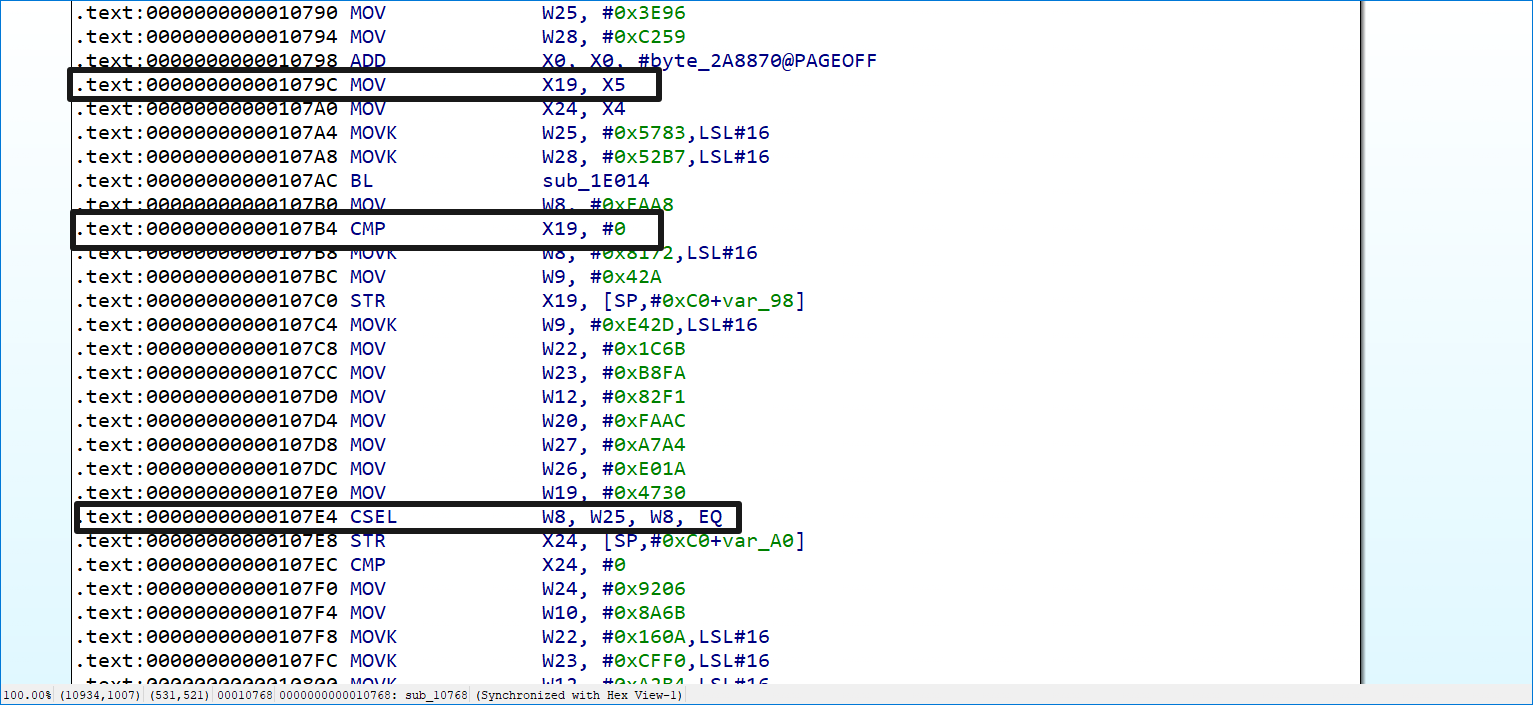
使用 angr 模拟执行时,由于没有写入函数参数,这些参数在 angr 中会以符号变量进行表示,在后面某处的分发器时 angr 会自行生成两个状态机,但是这样子会干扰到分析流程,因为不只是真实块中的分支,其他块中的分支也会生成多个状态机。使用 unicorn 时可以直接将 csel 修改成两个分支,其他的可以过滤掉。
笔者根据网上的资料,从最初的思路是遍历每一个真实块,通过模拟执行拿到真实块的后继块,如果真实块中含有 csel 指令则可以认为含有判断分支,即后继块会有两个。因为真实块的末尾会更新主分发器所使用的索引,这个索引必定可以找到下一个真实块。但是在具体分析中发现序言块中含有两个 csel 指令。
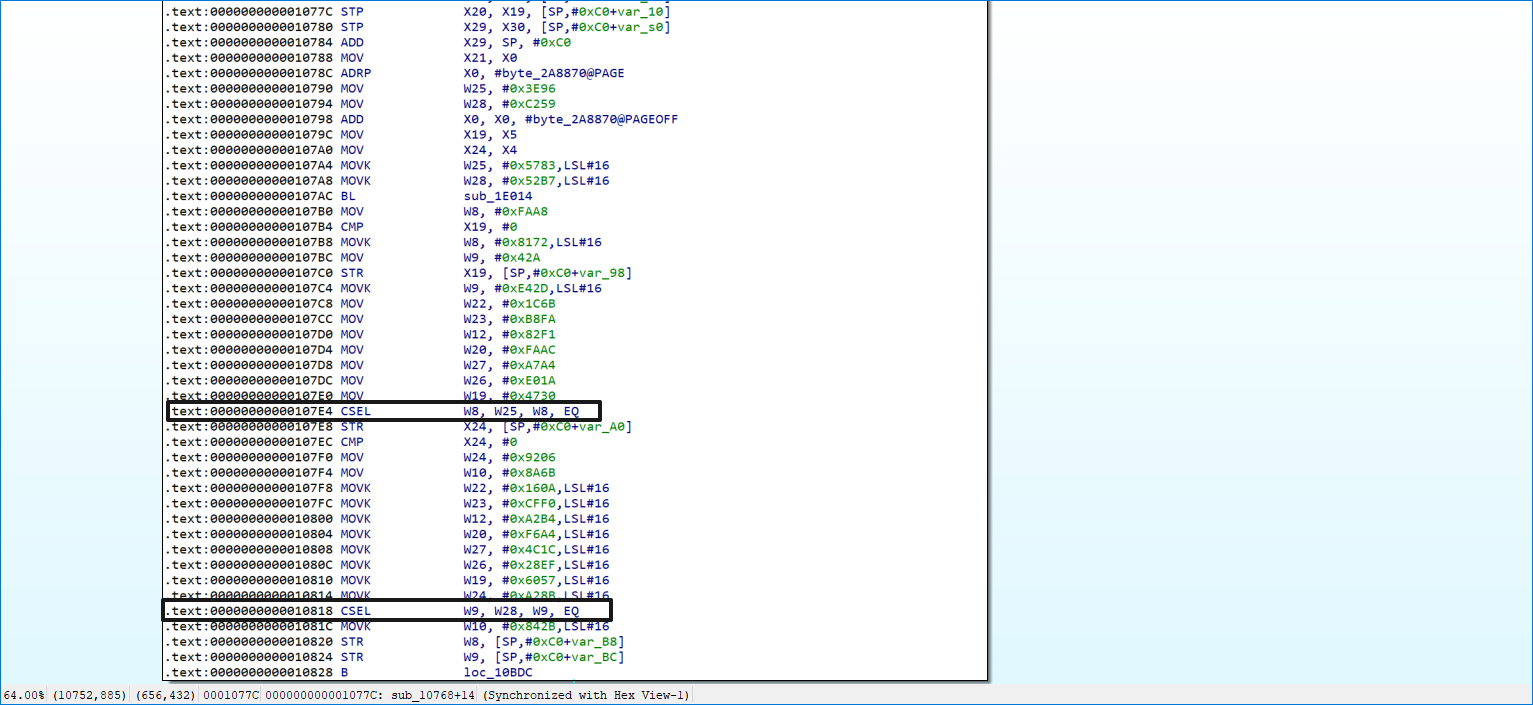
除此之外,笔者发现用于主分发器的索引存在于 x28 寄存器中,而在当前真实块里面没有对 x28 寄存器进行写入的操作。
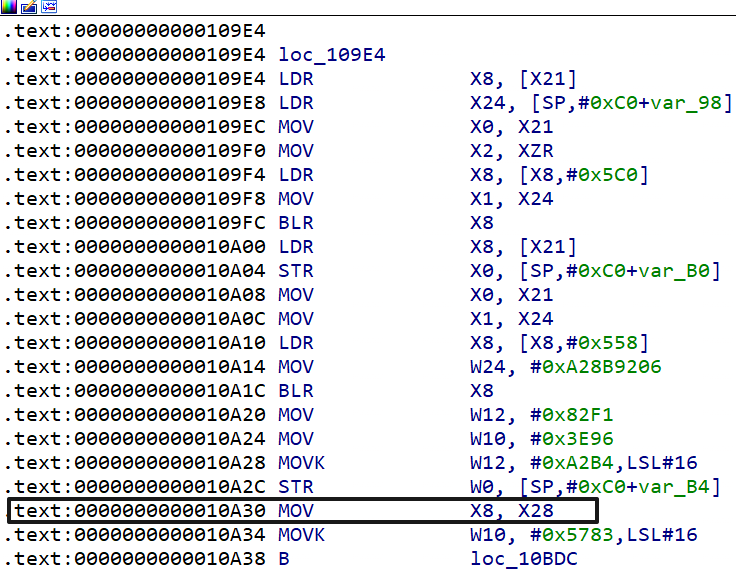
综上来说,通过遍历每一个真实块来获取后继块的方法无法在这里使用。
在上文的分析中,可以知道想要还原控制流需要在每个真实块执行后保存当前状态,包括寄存器和内存。这种重新构建每一个真实块的控制流可以想象成有向图,deepseek 向笔者推荐了 BFS 算法(广度优先算法),相比于 DFS 算法(深度优先算法),DFS 算法可能会在执行过程中遇到循环导致无法跳出等问题。
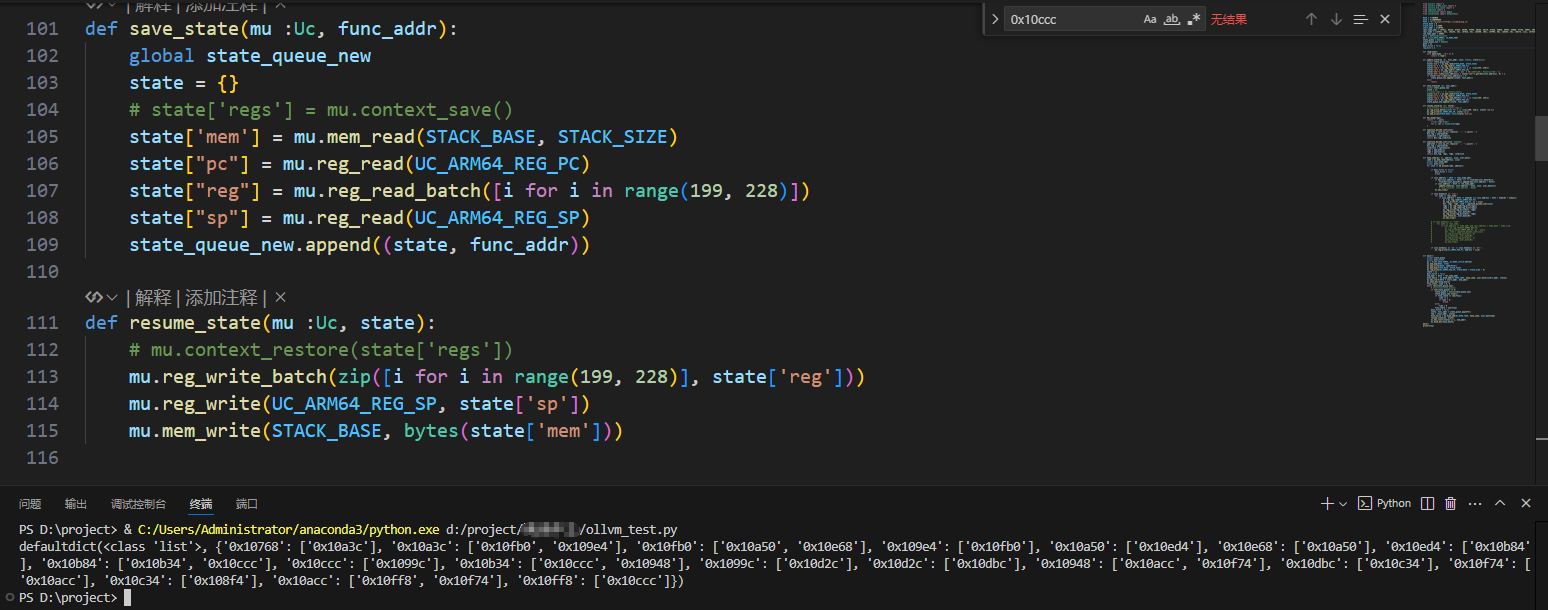
在上文获取到真实块之后,还需要把返回块也放入到真实块列表中,然后为了下文所需要,还要拿到真实块中的地址和大小。
unicorn 不同于 angr,该模拟器只能模拟 cpu 指令,并且需要自行配置内存。
这里将文件读取后写入到模拟器内存中,然后再拓展出一个栈以供模拟器使用
unicorn 可以使用hook_add 函数添加回调函数对每一次运行指令进行 hook。这里可以使用capstone 模块对指令进行反编译。
当指令是 csel 时进行处理,并且如果 csel 指令在真实块中执行的,则解析 csel 指令后面的四个操作数,并保存出两个分支。
当指令是 bl、blr 调用函数时,将其跳过
当运行到真实块时,则记录下来,并更新状态
这里可以衍生出一个笔者遇到的问题,由于 unicorn 没有单步执行功能,如果在下一次恢复状态后运行的情况下同样会进入该判断然后死循环。这里添加了一个公共变量用于跳过第一条指令进入后续判断流程。
首先执行一次函数,无论是遇到分支还是后继块都是保存状态到队列中,然后循环执行队列中的状态,遇到后继块或分支则保存状态到新的队列中,最终执行到返回块,当队列中没有了新的状态则代表完成运行。针对陷入循环的情况,在更新状态时有一次剪枝判断,同时使用了两个队列,一个队列用于运行另一个队列用于保存新的状态,当一个队列执行完之后可以认定为一个轮次,当执行多个轮次后,如果控制流的记录列表没有再更新的情况下可以认为是进入了循环,直接结束。
结果如下
这一部分还没有完成,从网上有的资料来看,基本上都是将 csel 直接修改成
b.{cond} addr
b addr
但是在该样本中,序言块会有两个 csel,并将结果存储下来到了后面的真实块再使用,在后续真实块时如果再改变指令为跳转的话无法与前面的 cmp 对应上。
import am_graph
import angr
import logging
file_path = "文件地址"
start_addr = 0x19D870
project = angr.Project(file_path, load_options={'auto_load_libs': False})
cfg = project.analyses.CFGFast(normalize=True, force_complete_scan=False)
base_addr = project.loader.main_object.mapped_base >> 12 << 12
target_function = cfg.functions.get(start_addr)
if target_function is None:
target_function = cfg.kb.functions.get_by_addr(base_addr + start_addr)
super_gragh = am_graph.to_supergraph(target_function.transition_graph)
import am_graph
import angr
import logging
file_path = "文件地址"
start_addr = 0x19D870
project = angr.Project(file_path, load_options={'auto_load_libs': False})
cfg = project.analyses.CFGFast(normalize=True, force_complete_scan=False)
base_addr = project.loader.main_object.mapped_base >> 12 << 12
target_function = cfg.functions.get(start_addr)
if target_function is None:
target_function = cfg.kb.functions.get_by_addr(base_addr + start_addr)
super_gragh = am_graph.to_supergraph(target_function.transition_graph)
real_node = []
real_node_addr = []
ret_node = []
for node in super_gragh.nodes():
if super_gragh.in_degree(node) == 0:
prologue_node = node
if super_gragh.out_degree(node) == 0:
ret_node.append(node)
main_dispatcher_node = list(super_gragh.successors(prologue_node))[0]
for node in super_gragh.predecessors(main_dispatcher_node):
if node.addr != prologue_node.addr:
real_node.append(node)
real_node_addr.append(node.addr - base_addr)
if len(ret_node) > 1:
ret_node = list(super_gragh.predecessors(ret_node[0]))[0]
else:
ret_node = ret_node[0]
print("序言块:", prologue_node.addr - base_addr)
print("返回块:", ret_node.addr - base_addr)
print("真实块:", real_node_addr)
print("主分发器:", main_dispatcher_node.addr - base_addr)
real_node = []
real_node_addr = []
ret_node = []
for node in super_gragh.nodes():
if super_gragh.in_degree(node) == 0:
prologue_node = node
if super_gragh.out_degree(node) == 0:
ret_node.append(node)
main_dispatcher_node = list(super_gragh.successors(prologue_node))[0]
for node in super_gragh.predecessors(main_dispatcher_node):
if node.addr != prologue_node.addr:
real_node.append(node)
real_node_addr.append(node.addr - base_addr)
if len(ret_node) > 1:
ret_node = list(super_gragh.predecessors(ret_node[0]))[0]
else:
ret_node = ret_node[0]
print("序言块:", prologue_node.addr - base_addr)
print("返回块:", ret_node.addr - base_addr)
print("真实块:", real_node_addr)
print("主分发器:", main_dispatcher_node.addr - base_addr)
real_node = []
real_node_addr = []
preprocessor_node = []
preprocessor_node_addr = []
ret_node = []
for node in super_gragh.nodes():
if super_gragh.in_degree(node) == 0:
prologue_node = node
if super_gragh.out_degree(node) == 0:
ret_node.append(node)
if super_gragh.in_degree(node) == 1 and super_gragh.out_degree(node) == 1:
real_node.append(node)
real_node_addr.append(node.addr - base_addr)
if super_gragh.in_degree(node) > 1 and super_gragh.out_degree(node) == 1:
preprocessor_node.append(node)
preprocessor_node_addr.append(node.addr - base_addr)
main_dispatcher_node = list(super_gragh.successors(prologue_node))[0]
if main_dispatcher_node in preprocessor_node:
preprocessor_node.remove(main_dispatcher_node)
preprocessor_node_addr.remove(main_dispatcher_node.addr - base_addr)
if len(ret_node) > 1:
ret_node = list(super_gragh.predecessors(ret_node[0]))[0]
else:
ret_node = ret_node[0]
real_node = []
real_node_addr = []
preprocessor_node = []
preprocessor_node_addr = []
ret_node = []
for node in super_gragh.nodes():
if super_gragh.in_degree(node) == 0:
prologue_node = node
if super_gragh.out_degree(node) == 0:
ret_node.append(node)
if super_gragh.in_degree(node) == 1 and super_gragh.out_degree(node) == 1:
real_node.append(node)
real_node_addr.append(node.addr - base_addr)
if super_gragh.in_degree(node) > 1 and super_gragh.out_degree(node) == 1:
preprocessor_node.append(node)
preprocessor_node_addr.append(node.addr - base_addr)
main_dispatcher_node = list(super_gragh.successors(prologue_node))[0]
if main_dispatcher_node in preprocessor_node:
preprocessor_node.remove(main_dispatcher_node)
preprocessor_node_addr.remove(main_dispatcher_node.addr - base_addr)
if len(ret_node) > 1:
ret_node = list(super_gragh.predecessors(ret_node[0]))[0]
else:
ret_node = ret_node[0]
real_node_addr.append(prologue_node.addr - base_addr)
real_node_addr.append(ret_node.addr - base_addr)
real_node.append(prologue_node)
real_node.append(ret_node)
print("所有块:", real_node_addr)
real_node_new = []
for node in real_node:
real_node_new.append([node.addr - base_addr, node.size])
print("所有块:", real_node_new)
real_node_addr.append(prologue_node.addr - base_addr)
real_node_addr.append(ret_node.addr - base_addr)
real_node.append(prologue_node)
real_node.append(ret_node)
print("所有块:", real_node_addr)
real_node_new = []
for node in real_node:
real_node_new.append([node.addr - base_addr, node.size])
print("所有块:", real_node_new)
BASE = 0x400000
SIZE = 0x100000000
PATH = "文件路径"
STACK_BASE = 0
STACK_SIZE = 0x1000
def read(name):
with open(name, 'rb') as f:
return f.read()
def main():
mu = Uc(UC_ARCH_ARM64, UC_MODE_LITTLE_ENDIAN)
mu.mem_map(BASE, SIZE)
mu.mem_write(BASE, read(PATH))
mu.mem_map(STACK_BASE, STACK_SIZE)
mu.reg_write(UC_ARM64_REG_SP, STACK_BASE + STACK_SIZE - 4)
BASE = 0x400000
SIZE = 0x100000000
PATH = "文件路径"
[培训]科锐逆向工程师培训第53期2025年7月8日开班!


 。谢谢大佬
。谢谢大佬

