本文演示了how2heap仓库里面各个程序的执行流程。
学习how2heap之前,需要先熟悉ptmalloc逻辑,推荐先看一下《Glibc内存管理--ptmalloc2源代码分析》,另外有部分概念,我在深度理解glibc内存分配这篇文章,更加细节的介绍过。
演示程序仅仅用于描述攻击的基本步骤,其中执行的每一步操作,在实际攻击中,都要通过漏洞程序的交互(本地/远程)逻辑触发:
(1) 交互可以访问并显示的范围通常有限,甚至依赖信息泄漏漏洞;
(2) 交互可以向程序写入的范围通常有限,甚至依赖写溢出漏洞;
(3) 交互通常不能轻易控制分配、释放的时机,以及分配内存的大小。
不过,只有透彻理解最基本的原型,才能将极其复杂的真实场景,转换成它们。
就跟下棋一样,不懂招数,看到的整盘棋都是零散的,反之每个阶段围绕一个战略目标,就可以分而治之,只需要应付每个较小范围里的变化。

过程说明:
将chunk(p)释放到unsorted_bin,然后利用漏洞 (比如UAF漏洞,因为chunk(p)当前为释放状态),修改chunk(p)->bk,使其指向fake_chunk,就将fake_chunk也链入unsorted bin了。
细节:
chunk(p)被malloc(0x410)分配到了:
(1) chunk(p)没有移入其它bin,所以chunk(p)->fd保持不变;
(2) 停止遍历unsorted_bin,从而fake_chunk仍然链在unsorted_bin,并且fake_chunk->fd,指向了unsorted_bin,unsorted_bin->fd,仍然指向chunk(p)。


过程说明:
相比unsorted_bin_attack.c,在执行34行之前,将chunk(victim)->size改掉了,使其不满足malloc(0x100)的要求,使其移入smallbin[0],从而继续往后遍历,最终分配到fake_chunk。
作用:
(1) 使目标位置可以被malloc()分配到;
(2) 可以在目标位置,写入unsorted_bin地址。

过程说明:
将victim_chunk释放到smallbin,然后修改victim_chunk->bk,使其指向fake_chunkA,就将fake_chunkA->fake_chunkB->...->fake_chunk6,链入smallbin了。
细节:
glibc-2.26开始,新增了tcache功能,相比unsorted_bin_attack,第120行执行malloc(0x100),分配到所需chunk后,会继续遍历smallbin,将后续chunk移入tcache,直到tcache填满为止,第123行malloc(0x100),优先从tcache分配到fake_chunk4。

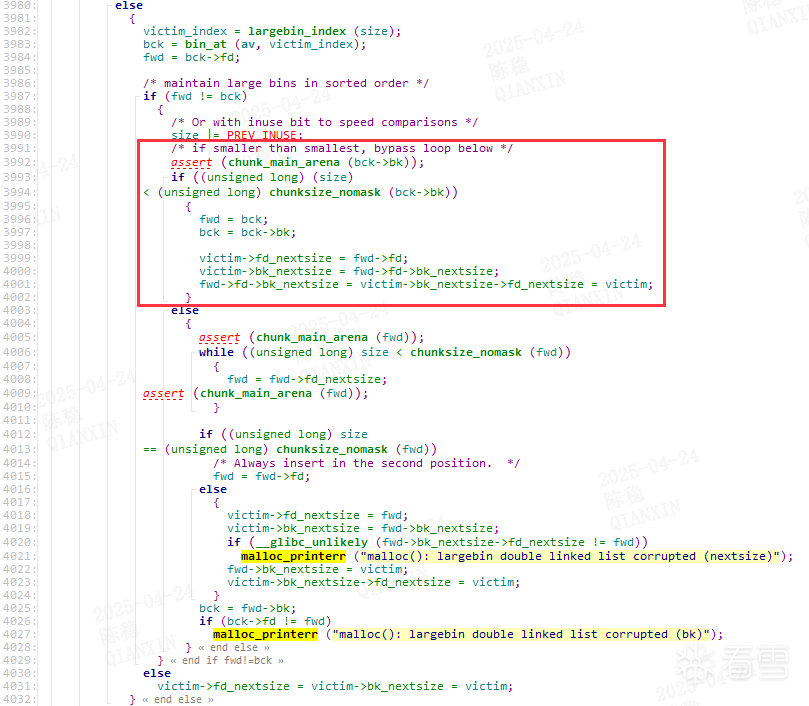
过程说明:
将chunk(p1)释放到largebin,然后修改chunk(p1)->bk,使其指向fake_chunk(&target-4),就将fake_chunk,链入largebin了。再触发chunk(p2)移入largebin,添加到它们之间时(largebin中的chunk会按大小排序),fake_chunk->fd_nextsize,就会被写为chunk(p2)。
glibc相关代码:

过程说明:
将chunk(b)释放到tcache,然后修改chunk(b)->fd,使其指向fake_chunk,就将fake_chunk,链入tcache了。
细节:
(1) tcache中链接的是tcache_entry对象,根据&chunk->fd位置强转得到,所以entry->next与chunk->fd位置对应。

(2) glibc-2.32开始,新增了加密指针功能,tcache以及fastbin链表中,chunk->fd不再直接指向下一个节点的地址,而是chunk->fd>>12 ^ 下个节点地址。

过程说明:
将chunk(a)释放到fastbin,然后修改chunk(a)->fd,使其指向fake_chunk,就将fake_chunk,链入fastbin了。
细节:
演示程序为了更接近真实的攻击过程,事先模拟了double free场景。
向fastbin添加chunk之前,只会检查链表头是否为要添加的chunk,不会检查整个链表(否则会影响free()的效率),所以在两次free(a)之间,执行一次free(b),就可以绕过glibc检测。


先看138行之后的执行过程:
(1) 142~154: 填满tcache[21] (个人认为这一步没什么必要,因为后面没有需要避免chunk释放进tcache[21]的地方);
(2) 159~169: 将large_chunk,释放到largebin[2],将unsorted_chunk,释放到unsorted_bin;
(3) 204: 修改unsorted_chunk->bk,将fake_chunk链入unsorted_bin,其实就是利用unsorted_bin_attack,用于最后执行calloc()时,可以分配到fake_chunk;
(4) 207, 245: 修改large_chunk->bk、large_chunk->bk_nextsize,其实就是利用large_bin_attack,使得unsorted_chunk移入large_bin[2]时,添加到large_chunk和fake_chunk之间,使得unsorted_chunk->bk_nextsize->fd_nextsize,指向unsorted_chunk;
(5) 278: 执行calloc(alloc_size),从unsorted_bin分配fake_chunk。
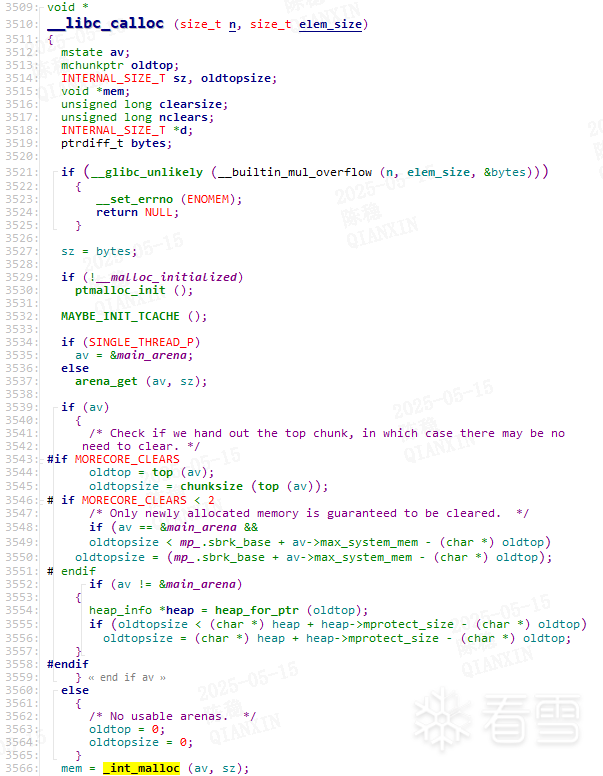
malloc()优先从tcache分配,但calloc()不会:

回头再头138行之前的执行过程:
73~138: 为large_chunk->bk_nextsize指向,计算微调偏移,使得0x173,正好写入&fake_chunk->size处,保证fake_chunk->size满足calloc(alloc_size)的分配大小。
glibc-2.32开始,tcache以及fastbin链表中,chunk->fd不再直接指向下一个节点的地址,而是chunk->fd>>12 ^ 下个节点地址,而如果node和nextnode在同一个4K page,仅通过加密指针本身,就可以还原出nextnode地址。

证明:
node: A15,A14,A13,A12,A11,A10,A9,A8,A7,A6,A5,A4,A3,A2,A1,A0
nextnode: B15,B14,B13,B12,B11,B10,B9,B8,B7,B6,B5,B4,B3,B2,B1,B0
加密指针:C15,C14,C13,C12,C11,C10,C9,C8,C7,C6,C5,C4,C3,C2,C1,C0
由于node和nextnode只有低12位不相等,所以node也可以表示为:
node: B15,B14,B13,B12,B11,B10,B9,B8,B7,B6,B5,B4,B3,A2,A1,A0
由于,加密指针 = node>>12 ^ nextnode
=> (1) B15,B14,B13 = C15,C14,C13
=> (2) C12,C11,C10 = B15,B14,B13 ^ B12,B11,B10 => B12,B11,B10 = B15,B14,B13 ^ C12,C11,C10,同理可求:B9,B8,B7、B6,B5,B4、B3,B2,B1、B0。
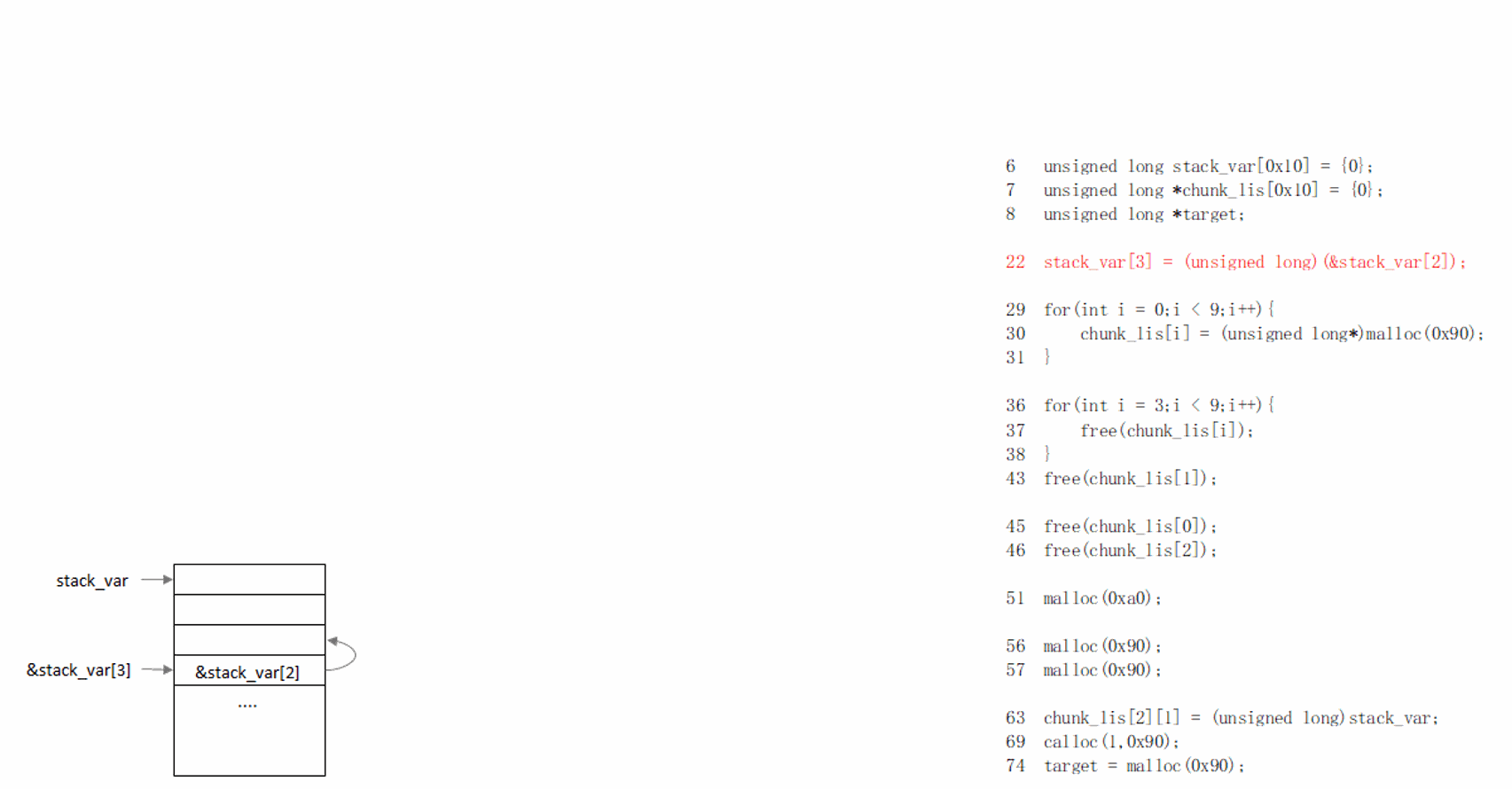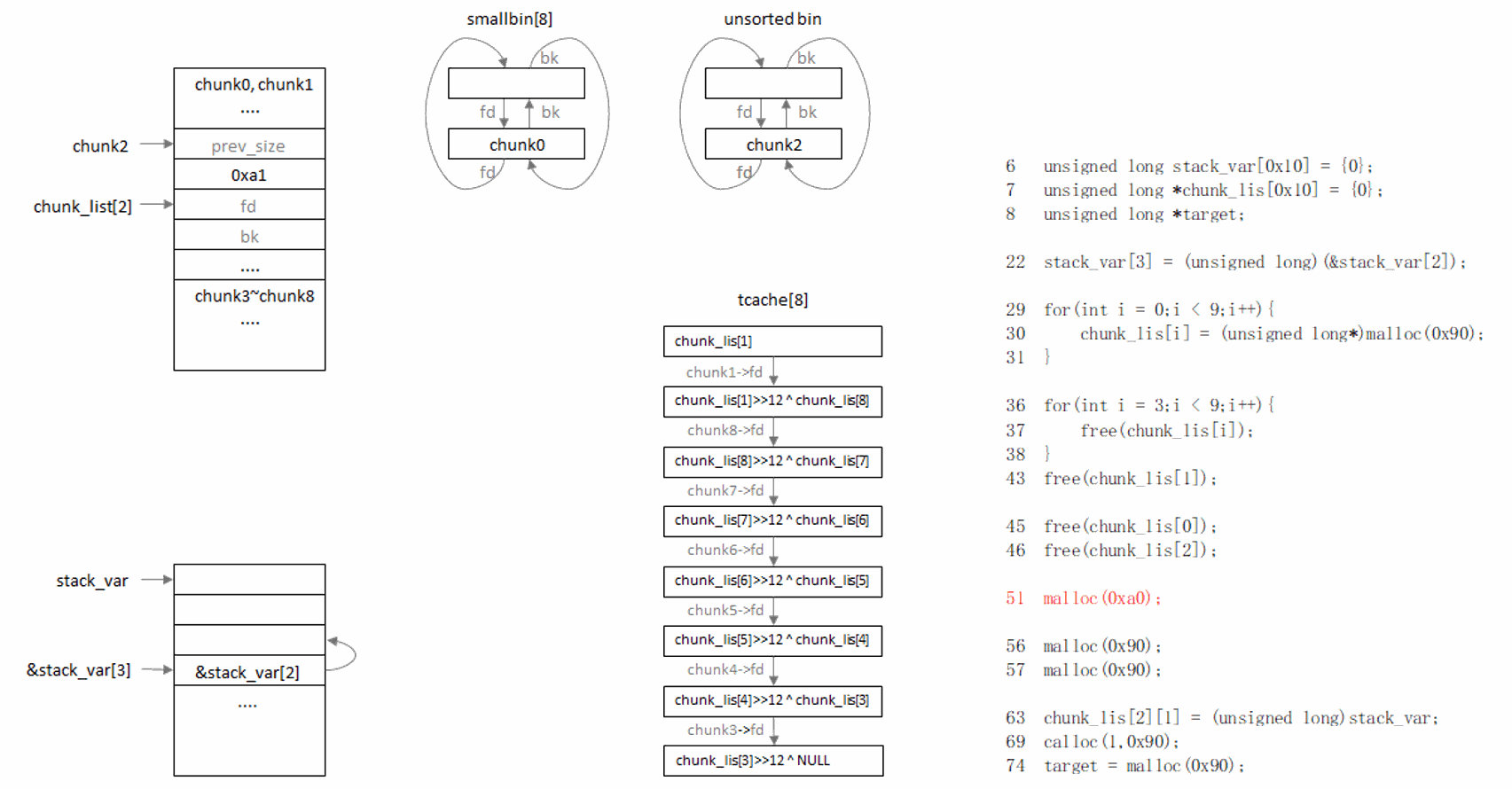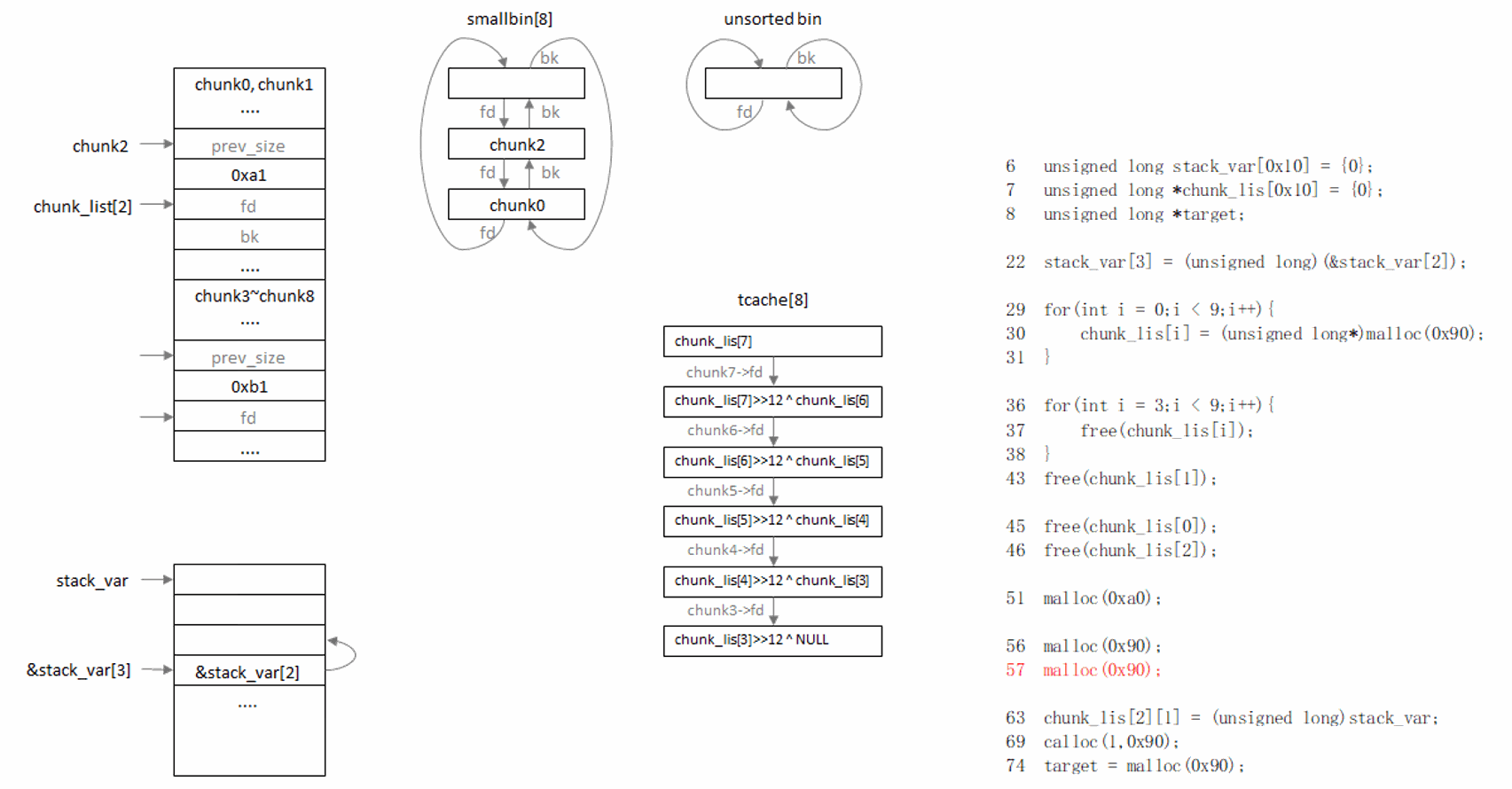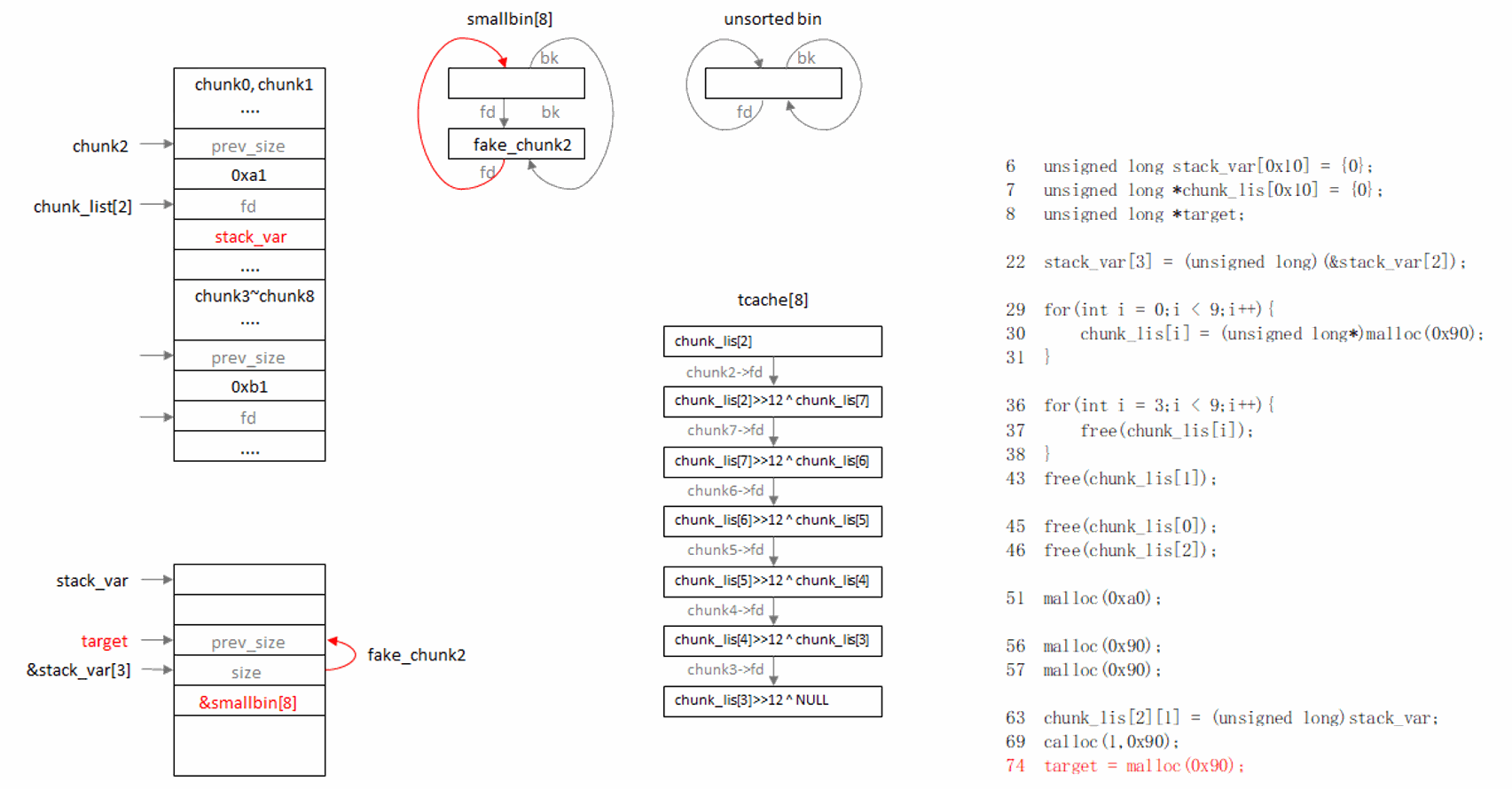
过程说明:
先触发chunk从smallbin移入tcache,再从tcache分配这个chunk,就可以绕过chunk->bk->fd == chunk检查。
原因:
(1) 从tcache分配chunk,不检查chunk->bk->fd == chunk;
(2) 从smallbin分配chunk,会取出首个chunk,并检查chunk->bk->fd == chunk,而如果tcache未满,会将剩余chunk移入tcache,并且不做检查。


fastbin FILO,tcache FILO,fastbin中的chunks移入tcache后,顺序会颠倒:
最先从fastbin移出的chunk,也会最先移入tcache,那么在tcache中,就会最后才能被移出。

fastbin_dup用于绕过double free检测,fastbin_dup_into_stack,就已经展示过。

也是用于绕过double free检测,原理都是先将相同的chunk,挤出fastbin链表头,只不过这里是挤到unsorted_bin。

作用:
真实攻击场景,如果目标位置不能直接控制写入,但其周围内容可控,并且周围地址的释放、分配也可控,就可以尝试将目标位置分配给程序后,再通过交互控制它的内容。
细节:
释放fake_chunk前,先要设置地址相邻的next_chunk->size,保证它属于(2*SIZE_SZ, av->system_mem)区间,绕过free()内部的检查。
[培训]内核驱动高级班,冲击BAT一流互联网大厂工作,每周日13:00-18:00直播授课



