-
-
猿人学2025js逆向验证码比赛第一题(补环境)
-
发表于: 2025-6-9 13:54 101
-

一、补基础环境
首先将代码复制到本地运行,第一次尝试运行报错:

那么先尝试修改代码为true,因为再浏览器中window本身就是Window的实例对象,所以肯定是true,再全局搜索一下还有没有window以及Window还有instanceof
发现window一共有9处,大window有两处,instanceof 只有一处



那么肯定先补个window,和大window,同时给他们上代理
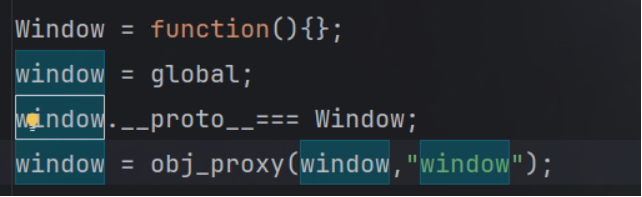
再次运行得到:
ReferenceError: $ is not defined
这里去浏览器中查看是什么,可以发现是jquery里面的内容,那么手动补一下,再次运行得到ajax未定义,
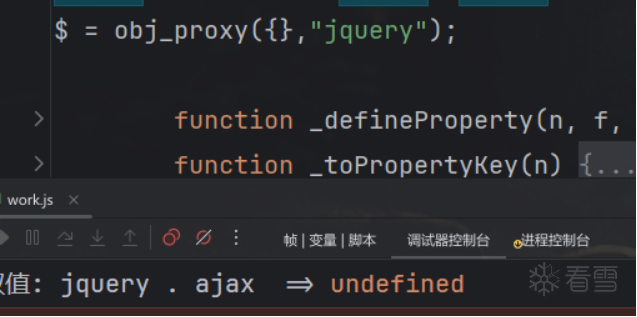
然后再补一下这个函数,发现已经可以生成了:
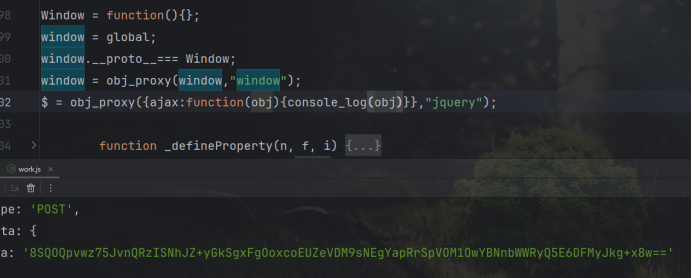
很明显进入蜜罐了,不可能这么简单,那么再搜一下关键词看看有没有线索
这样再所有能搜到的关键词这里进行插入日志,同时遇到可疑的点直接修改如下图:
众所周知window这种再浏览器里面怎么修改都但是再node中咱们是自定义的变量却可以被修改所有这直接改为return {};
同时再搜索关键词的时候还发现了document,navigator,location,同理全部插入日志,再次运行:
现在日志打印如下,那么补上navigator以及cookieEnabled:
21295 navigator i cookieEnabled
ReferenceError: navigator is not defined
同时这里顺带把刚才发现的document,location也补上,再次运行得到下面的日志:

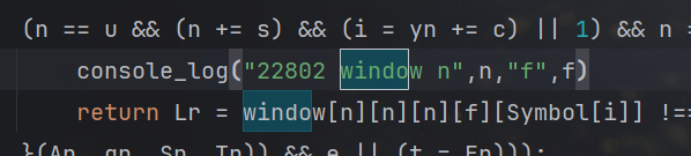
那么先分析一下2333以及22802这两个地方的代码
这里是将window.window 设置为window
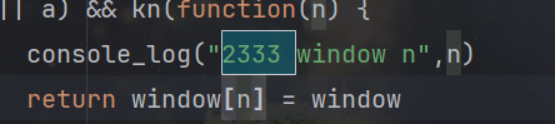
这里是取window.window.window.window等等这样去下去然后再取了__proto__隐式原型的symbol属性,那直接从浏览器里面取一下,这一行的结果,从而修改源代码;
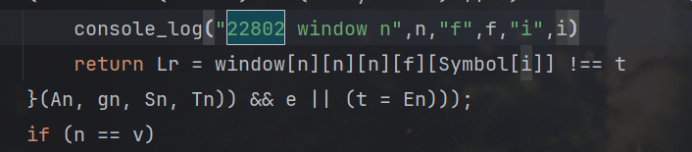
发现实际上是个window的字符串:
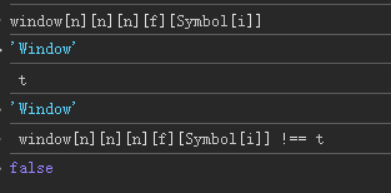
那直接将这行代码改为false,,然后注释掉这个日志点,再次运行发现,没有其他的日志出现了,那么现在先用这个a去访问看一下,发现:<UNK>,得此路行不通,那么换个方式,老实跟栈;
二、浏览器跟分析请求体a
咦,当我下来xhr断点后神奇的发现,断住了一个请求logo的xhr,那么先看一下这个得到的结果是什么:
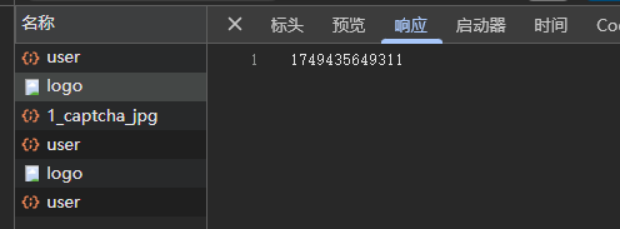
这不是时间戳吗?再看堆栈信息: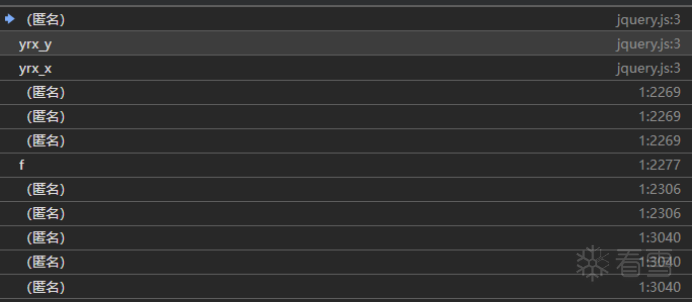
发现是在这里进行的请求:
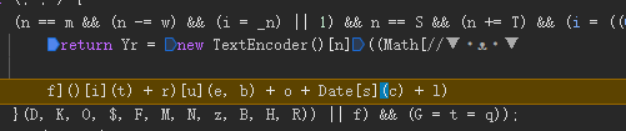
得到这么一个东西。那么断点放开,同时,这里面取开启油猴脚本,hook encode,以及对应的decode(末尾附上脚本源码)

开启hook脚本后发现,这个就是“"l53aztny2oa00000咦~,可带劲~。1749440475049俺不中嘞~"”
然后从搜一下这个Yr的引用看看有几次,再哪里用到的这个;发现只有三次,第一次是定义,第二次再传给了so函数,第三次是这里复制,那么先断到so函数试一下,执行发现,生产出的值和a很想,为了确认这里放开断点,试一下;发现确实就是a,那么这里就能确认了so函数就是加密函数;


这里回到本地环境,将so函数导出到全局中,看一下生产出的值是否和浏览器保持一致;
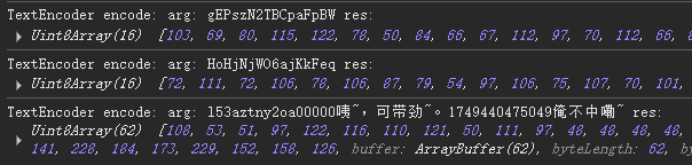
通过decode方式导出变量,
new TextDecoder().decode(Yr)
'gmbli2480bu00000咦~,可带劲~。1749440910580俺不中嘞~'
new TextDecoder().decode(Vr)
'gEPszN2TBCpaFpBW'
new TextDecoder().decode(Xr)
'HoHjNjWO6ajKkFeq'
再通过encode的方式导出这三个参数
Yr = new TextEncoder().encode('gmbli2480bu00000咦~,可带劲~。1749440910580俺不中嘞~');
Vr = new TextEncoder().encode('gEPszN2TBCpaFpBW');
Xr = new TextEncoder().encode('HoHjNjWO6ajKkFeq');
res = window.soso(Yr,Vr,Xr);
console_log(res);
console_log(res =='Lu26zEWUx3Xm3IeD8uzVv7VPA6ooBvnFp9ETgLoRHVp2bPGr7wsmqk6qz9pX5j9XLOn0u1ORVFWFrYRTt/UKBw==');发现是一致的那么原因就很可能是刚才的那个logo请求得到的时间了;,所以,这里封装一个函数出来,给python调用再试一下;发现没问题了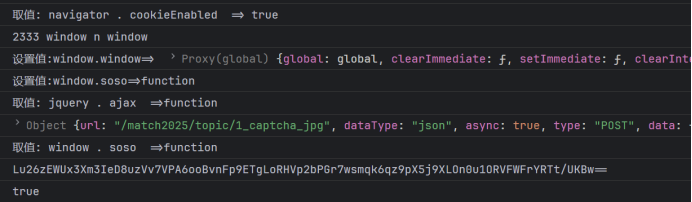

三、分析响应体
会到浏览器中,查看日志,发现还有解码的部分,同理看一下解码出来的是什么;
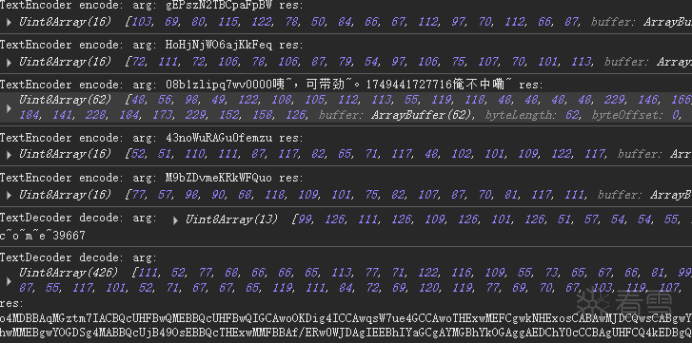
这里再decode函数中下个断点,然后回溯到页面的js中;可以看到这里是调用了wo函数然后传递了响应体里面的“来啦老弟?”字段
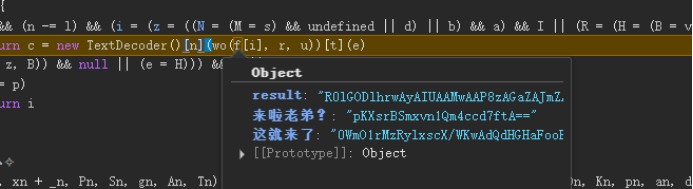
经过他这一行最终得到的结果是['c', 'o', 'm', 'e', '42247']
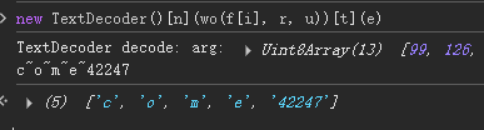
然后放开断点继续
再次再decode函数断到了,再次回溯到页面的js中;发现是获取的响应体中的"这就来了"字段然后传给了wo函数得到最后得到了一大长串的字符串
这里可以再页面验证码的节点中下一个属性修改的断点。因为你验证码最后肯定是会在页面中展示的;所有可以这样下个断点试试,发现真断住了,并且有意外之喜,这里发现验证码并非直接就是result字段;

这里手段还原一下这一行代码:f就是响应体的json格式,控制台输出一下pf以及l
$("#captchaImg")["attr"]("src",''["concat"](f['result']["slice"](0,10689)+Pf+f['result']["slice"](10689)))

发现这不就是刚才分析的decode的那两个字段嘛
那这里就可以放开了,回到本地环境中,先导出wo函数,再封装成函数,附上代码:
function decode_come(text){
r = new TextEncoder().encode('43noWuRAGu0femzu');;
u = new TextEncoder().encode('M9bZDvmeKRkWFQuo');;
let res = new TextDecoder().decode(window.wowo(text,r,u)).split("~").slice(-1)[0];
return res;
}
function decode_sp(text){
r = new TextEncoder().encode('43noWuRAGu0femzu');;
u = new TextEncoder().encode('M9bZDvmeKRkWFQuo');;
let res = new TextDecoder().decode(window.wowo(text,u,r));
return res;
}这里有个坑,就是u,r的位置不是一样的,他们两个交换了;这里本地测试一下
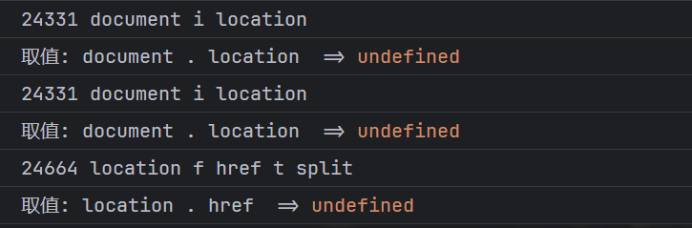
发现之前插入的日志有输出,并且有报错,这里补上环境

再次运行发现没问题了,然后就是python部分做拼接的代码我就不展示了,上面原理已经有了,再拼接保存成文件相信你们可以的;gif图像识别部分,思路是获取总共有多少帧,然后再遍历每一帧,获取对应的帧显示时间取最大值,最后ddddocr识别这一帧的图像即可;这部分代码纯ai帮我实现的,所以再尾部贴出来;
四、分析请求体text
回到浏览器环境中;手动提交发现有一行日志,,那么刷新页面断到这里;


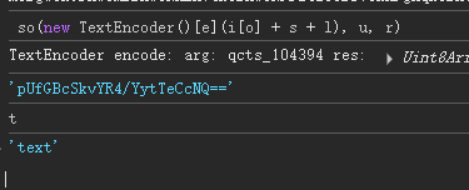
那很明这里就是加密位置了;
一样的逻辑回到本地js导出这个so函数,然后发现,这就是刚才的那个so函数,那么直接服用刚才的那个so函数封装一下;
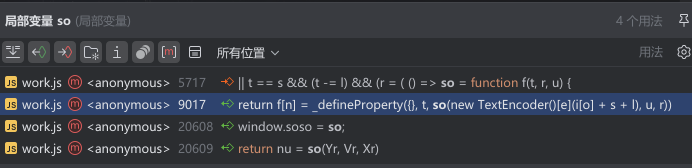
至于参数的话,很明显就是就是验证码加下划线加刚才的那个come的数字

所以封装的js函数如下:
function get_text(text,come){
let random_text = text + "_" + come
window._Yr = new TextEncoder().encode(random_text);
window._Vr = new TextEncoder().encode('M9bZDvmeKRkWFQuo');;
window._Xr = new TextEncoder().encode('43noWuRAGu0femzu');;
let res = window.soso(window._Yr,window._Vr,window._Xr)
return res;
}然后回到python里面测试一下,发现没有问题了

五、结语
其实题目挺简单的,但是有很多的点不注意就会进入蜜罐,进去了就半天出不来,看着文章写的挺顺利实际上我第一次做的时候遇到一个蜜罐就进去一次,甚至图像处理哪里,我还以为有什么压缩炸弹实际上并不是的,只是少了一部分需要拼接上而已,逆向还是要心细致一些。
六、附件
油猴脚本如下:
// ==UserScript==
// @name hook Text encode and decode
// @namespace e97K9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8Y4c8S2L8i4m8W2M7X3#2G2L8X3E0W2P5g2)9J5k6h3&6W2N6q4)9J5c8R3`.`.
// @version 2025-06-09
// @description try to take over the world!
// @author beimu
// @match 06bK9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6E0j5i4c8U0K9o6t1H3x3U0g2Q4x3X3g2&6N6h3q4F1M7X3g2F1P5s2g2W2i4K6u0W2j5$3&6Q4x3V1k6E0j5i4c8U0K9o6t1H3x3U0g2Q4x3V1k6@1L8%4m8A6j5#2)9J5c8U0p5`.
// @grant none
// @run-at document-start
// ==/UserScript==
(function() {
'use strict';
let text_encode = TextEncoder.prototype.encode;
let console_log = console.log;
TextEncoder.prototype.encode = function(val){
let res = text_encode.call(this,val);
console_log("TextEncoder encode: arg:",val,"res:",res);
return res;
}
let text_decode = TextDecoder.prototype.decode;
TextDecoder.prototype.decode = function(val){
let res = text_decode.call(this,val);
console_log("TextDecoder decode: arg:",val,"res:",res);
return res;
}
})();python 图像识别部分如下:
import io
import re
import time
from io import BytesIO
from PIL import Image,ImageSequence,ImageFile
import numpy as np
import cv2
import base64
from ddddocr import DdddOcr
def extract_gif_frames(gif_bytes):
frames = []
actual_frame_count = 0
frame_index = 0
img = Image.open(io.BytesIO(gif_bytes))
# 获取图像总帧数(避免无限循环)
total_frames = img.n_frames if hasattr(img, 'n_frames') else 0
while frame_index < (total_frames if total_frames > 0 else 10000): # 安全上限
try:
# 使用更安全的方式检查帧大小
if img.size[0] * img.size[1] > 10_000_000: # 提前检查尺寸(1000万像素)
print(f"警告: 跳过超大帧 {frame_index + 1} ({img.size[0]}x{img.size[1]})")
frame_index += 1
continue
img.seek(frame_index)
frame = img.copy()
if frame.mode in ['RGBA', 'LA', 'P']:
background = Image.new('RGB', frame.size, (255, 255, 255))
if frame.mode == 'P':
frame = frame.convert('RGBA')
background.paste(frame, mask=frame.split()[-1] if frame.mode == 'RGBA' else None)
frame_rgb = background
else:
frame_rgb = frame.convert('RGB')
frame_cv = cv2.cvtColor(np.array(frame_rgb), cv2.COLOR_RGB2BGR)
duration = frame.info.get('duration', 100)
frames.append({"duration": duration, "frame": frame_cv})
actual_frame_count += 1
print(f"成功处理第 {frame_index + 1} 帧")
except EOFError:
break
except Exception as e:
error_msg = str(e)
if "DecompressionBombError" in error_msg or "exceeds limit" in error_msg:
# print(f"警告: 跳过第 {frame_index + 1} 帧 (解压缩炸弹错误): {error_msg}")
pass
elif "MemoryError" in error_msg or "out of memory" in error_msg:
print(f"严重: 内存不足,无法处理第 {frame_index + 1} 帧")
break # 内存不足时停止处理
else:
print(f"警告: 处理第 {frame_index + 1} 帧时出错: {error_msg}")
finally:
frame_index += 1
print(f"总共处理了 {actual_frame_count}/{frame_index} 帧")
return frames
def format_img(img_text):
try:
img_content = base64.b64decode(img_text, validate=True)
return img_content
except Exception as e:
print(e)
def cv2_to_bytes(image, format='.png', quality=95):
encode_params = [int(cv2.IMWRITE_PNG_COMPRESSION), 9 - round(quality / 10)]
success, encoded_image = cv2.imencode(format, image, encode_params)
if not success:
raise ValueError("图像编码失败")
return encoded_image.tobytes()
def get_max_time_img(gif_bytes,det):
frames = extract_gif_frames(gif_bytes)
max_dict = max(frames, key=lambda x: x["duration"])
image = cv2_to_bytes(max_dict["frame"])
bboxes = det.classification(image)
print("停留时间最长的英文字母",bboxes)
return bboxes
def main():
det = DdddOcr(show_ad=False)
# spider = Spider(debug=True)
# for i in range(5):
# t = spider.get_logo()
# img_text = spider.get_img(t)
# img_content = format_img(img_text)
# if img_content is None:
# continue
# with open(f'img_{i}.gif','wb')as f:
# f.write(img_content)
# code = get_max_time_img(img_content,det)
# spider.check_img(code)
if __name__ == "__main__":
main() 赞赏
|
|
|---|---|
|
|
|

