译者注:由于本片文章涉及较多的操作系统以及编译原理相关知识,译者才疏学浅,难免有翻译的不准确或错误的地方,希望大家多多包涵,欢迎评论区批评指正。同时要感谢校对人员认真的校对。
在前面的章节中,我们介绍了一些关于管理程序的基本概念,并简要介绍了x86虚拟化的不同技术:使用二进制翻译的全虚拟化,超虚拟化和硬件虚拟化。今天,我们回深入研究全虚拟化,特别是早期版本的VMWare Workstation如何成功将虚拟化带回到x86中,不管缺少虚拟化及时支持和架构的深度复杂性。
在我们进一步讨论前,我想强调,本章将讨论的内容是专门设计用于在引入64位扩展或硬件支持虚拟化( VT-x和AMD-v )[2006] 之前的虚拟化x86架构。VMware当前的市面上虚拟机管理程序(VMM)与原始设计明显不同。不过,你将学的知识将扩展您对虚拟化和底层概念的理解。
VMWare从两种管理程序解决方案开始:Workstation 和 ESX 。VMWare Workstation的第一个发布版可追溯到1999年(发布版本历史 )。ESX在2001年出现(发布版本历史 )。Workstation被认为是宿主架构(类型1),然而ESX是运行在裸金属架构(类型2)。在这篇文章中,我们将专注于VMWare Workstation 。
如果你想查看VMM(虚拟机管理程序),从此处 下载安装程序,将其安装到Windows XP VM中,安装后,在ProgramFiles 目录中找到 vmware.exe,使用PE资源编辑器(如CFF Explorer )打开它,并转储二进制文件,VMM是一个ELF 文件。
正如我们在第一篇文章中看到的,宿主架构允许将虚拟化插入到现有的操作系统中。VMWare打包为一个正常的应用程序,其中包含一系列的驱动和可执行/dll文件。作为正常应用程序运行有很多好处。首先,VMWare依靠主机图形用户界面,以至于每个虚拟姐屏幕的内容可以自然的出现在一个特别的窗口中,这将是很好的用户体验。另一方面,每个虚拟机实例以进程(vmware-vmx.exe )的形式运行在主机操作系统,可以独立启动,监控,终止。该进程在本章中会被标记为VMX 。
除此之外,在主机OS上运行有助于 I/O 设备模拟。由于操作系统可以使用自己的设备驱动和 I/O 设备通讯,因此VMWare支持通过标准系统调用到主机操作系统来模拟设备。例如,它会读写宿主机文件系统来模拟虚拟磁盘设备,或者在宿主机的桌面窗口中绘画来模拟显卡。只要宿主机操作系统中有合适的驱动程序,VMWare就可以在其上运行虚拟机。
然而,正常的应用程序没有VMM的必要API或工具来复用CPU和内存资源。因此,VMWare似乎只运行在当前操作系统的顶端,实际上,它的VMM可以在系统级运行,完全控制硬件。事实上,主机操作系统恰当地假设它一直在控制硬件资源。但是,VMM实际上在一段有限的时间内控制硬件,在这段时间内主机操作系统被从虚拟和线性内存中短暂移除。
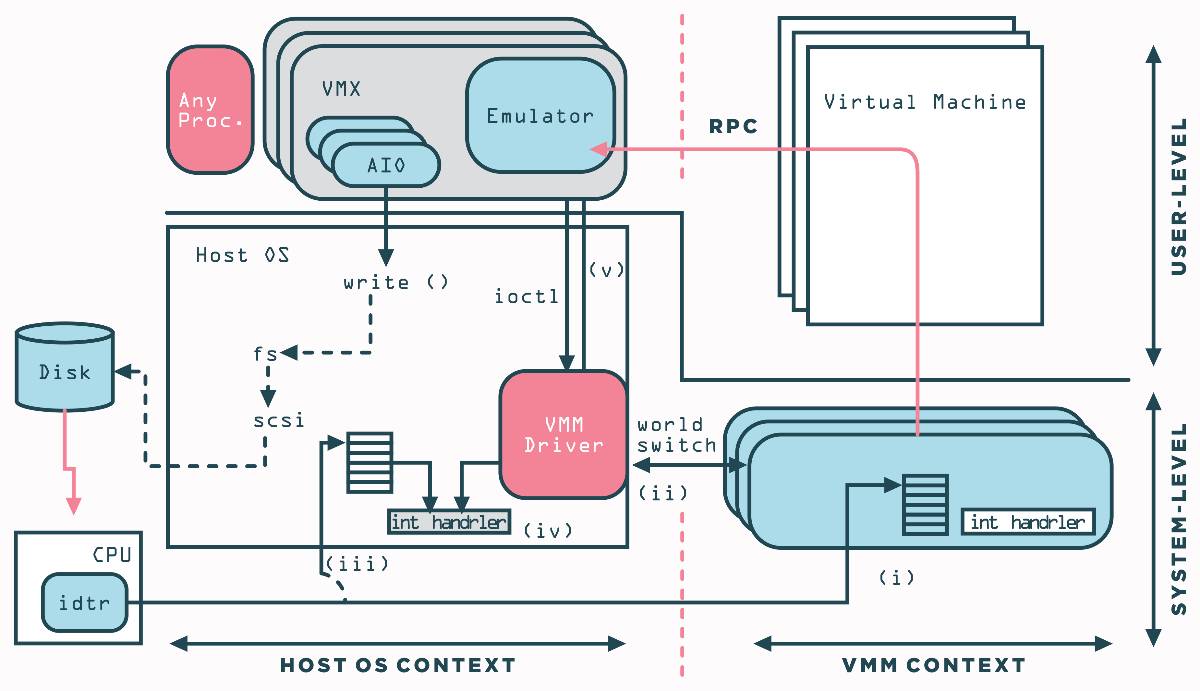
从上图中可以看出,在任何时候,每个CPU可以位于:
VMM和宿主机操作系统的上下文切换又称为世界切换(world switch) 。每个上下文有自己的地址空间,中断描述符表,堆栈,执行上下文。驻留在宿主机的VMM驱动 程序实现了一系列操作,包括锁定物理内存页,转发中断以及调用世界切换原语。就主机操纵系统而言,设备驱动是标准的可加载的内核模块。但不是驱动某些硬件设备,而是驱动VMM并将其从宿主机操作系统完全隐藏。
当一个设备产生中断时,CPU可能在主机上下文和VMM上下文中运行。在第一种情况下,CPU通过中断描述符表 (Interrupt Descriptor Table ,IDT)将控制权交给主机操作系统。在任何VMM上下文中发生中断的第二种情况下,涉及步骤(i)-(v):
处理物理中断的一部分,这个插图展示出VMWare如何依靠VMs发出I/O请求,所有这些虚拟I/O请求都是使用VMM和VMX进程间的RPC调用来执行的,VMX进程随后执行正常对主机操作OS的系统调用。为了允许虚拟机和它自己挂起的I/O请求重叠执行,VMX进程运行不同的线程:
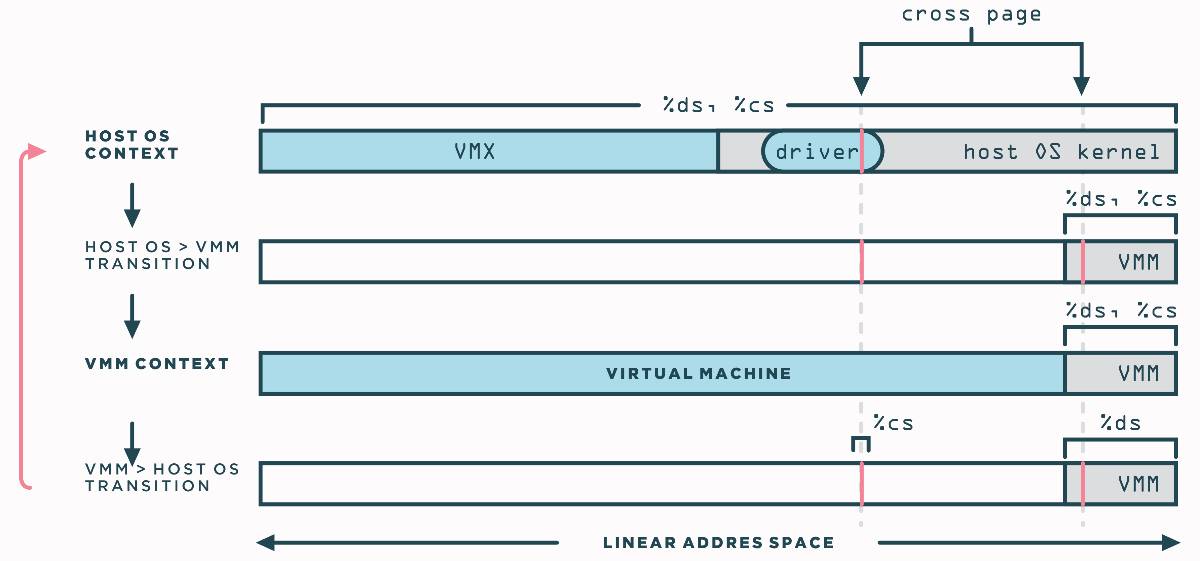
现在返回到世界切换,它与之前可能遇到的传统上下文切换非常相似(如在内核空间和用户空间之间,或者在调试器和调试对象之间),提供了加载并执行虚拟机上下文的低级VMM机制,以及恢复主机操作系统上下文的反向机制。
上图指明了世界切换程序如何将主机切换到VMM上下文,反之亦然。VMM将离开前4MB空间。交叉页面 (cross page)是单页内存,以非常特殊的方式使用,是世界切换的重点。交叉页面由内核驻留驱动分配到主机操作系统的内核地址空间。由于驱动程序使用标准API进行分配,因此主机操作系统决定了交叉页面的地址。
紧接着,在每次世界切换前后,交叉页面也映射到VMM地址空间。交叉页面包含世界切换的代码和数据结构。下面是双向执行的指令反汇编:
VMX 进程表示主机上的虚拟机。它的作用是分配,锁定和最终释放所有内存资源。此外,它以文件映射(映射到自己的地址空间)的方式管理VM的物理内存(Linux使用mmap 或者Windows使用文件映射 (file mapping)API)。虚拟设备DMA 的模拟是通过VMX对映射文件对应部分的简单bcopy ,read 或write 操作实现的。VMX和驻留在内核的驱动程序协同工作来为客户机物理地址 (Guest Physical Address,gPA)锁定的页面提供机器物理地址 (Machine Physical Address,mPA)。
既然我们对VMWare的整体托管架构有了一个概念,现在让我们转到VMM本身以及它的运作方式。我们之前已经看到,VMM的主要功能是虚拟化CPU和内存。我们也讨论了虚拟机通常使用称为陷阱和模拟 (trap-and-emulate)的方法运行。在陷阱和模拟方式的VMM中,客户机代码直接运行在CPU上,但减少了权限 (reduced privilege)。当客户机尝试读或修改特权状态时,处理器会生成一个将控制权交给VMM的陷阱。VMM随后使用解释器模拟指令并在下一条指令恢复客户机代码的直接执行。我们说过x86不能使用陷阱和模拟,因为许多如敏感非特权指令 (sensitive non-privileged instructions)的阻碍。那么如何继续?
一种方法是使用动态二进制翻译来运行完整的系统模拟,如 Qemu 那样做。然而,这回产生显著的性能开销。如果你运行的是Windows,你可以从这里 下载Qemu,并自己动手尝试。在Linux中,你可以检查这个 链接 ,当然,你不应该使用 KVM 来运行它,因为 Qemu 有一个对 KVM 加速虚拟化的模式,我们将会在之后的章节中讨论。
VWWare提供了一个由二进制翻译 (BT)和直接执行 (DE)相结合的方案。DE意味着你可以直接在CPU上执行汇编指令动态 二进制翻译器在运行时通过存储目标序列到称为翻译缓存 的缓冲区中来执行翻译。VMWare使用DE运行客户机用户模式应用以及BT运行客户机系统代码(内核)。将BT和DE结合限制了客户机花费运行内核代码的翻译器时间开销,这通常是总执行时间的一小部分。与仅依赖二进制翻译的系统相比,这样做可以显著提高性能,因为它允许直接使用所有的硬件组件。
VMM必须为自己保留部分客户机虚拟地址(VA)空间。尽管VMM的指令和数据结构可能使用大量的客户机VA空间,但VMM可以完整地在客户机VA空间内运行。或者,VMM可以运行在单独的地址空间中,但这种情况下,VMM也必须使用少量的客户机VA空间用来管理客户机软件和VMM之间转换的控制结构(如IDT和GDT)。无论如何,VMM必须阻止客户机访问VMM正在使用的客户机VA空间的那些部分。否则,如果客户机能够写入那些部分或者客户机可以读取它们(内存泄漏),VMM的完整性会受到影响。
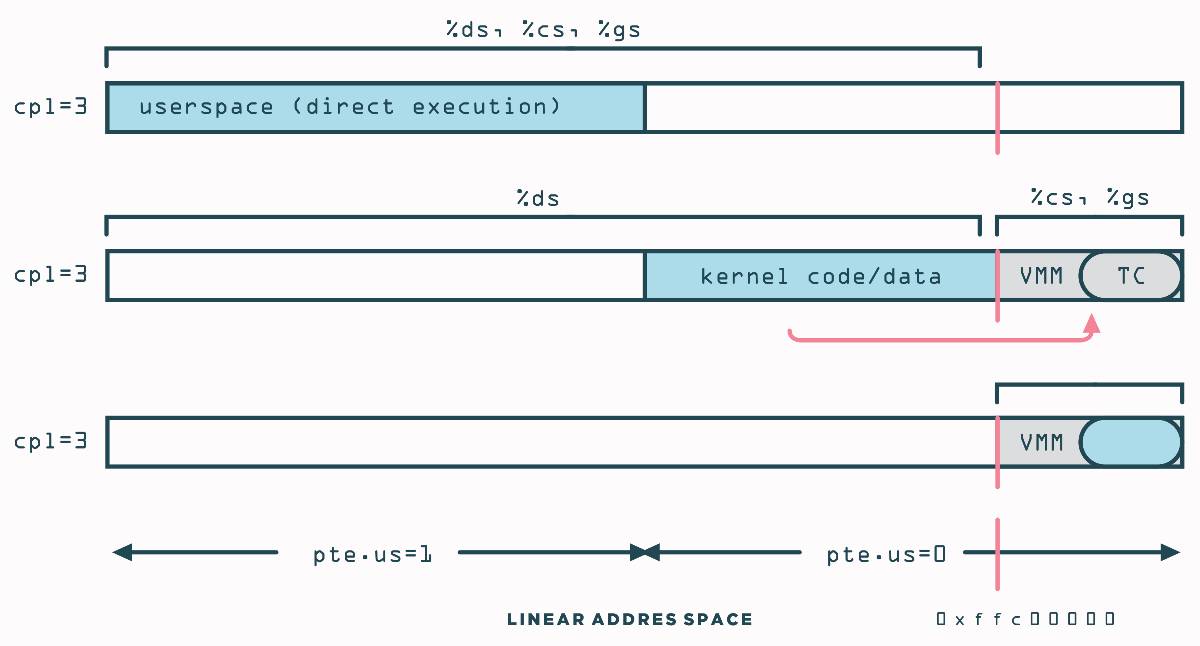
VMWare VMM与VM共享相同的地址空间,我们需要保证该部分内容对用户透明,并用最小的性能开销来完成。x86支持两种保护机制:分页 和分段 。可以使用其中一个或者两者都使用,VMWare使用分段来保护VMM免受来自客户机的影响。
客户机用户模式应用在ring 3正常运行,然而,被用来运行在( ring 0 )的客户机内核代码被降权而在ring 1层或 %cpl = 1 上的二进制翻译下运行。虚拟机段(segments)被VMM截断来确保它们不会与VMM自身重叠。任何尝试从VM访问VMM段的行为会触发会被VMM正确处理的通常保护错误。用户模式的程序运行在截断的段中,并且受到自身操作系统的保护限制访问使用分页 pte.us 的客户机内核区域。在实际页表中 pet.us 标志和原始客户机页表中的相同。客户机应用代码被硬件限制,只能访问 pte.us = 1 的页面。客户机内核代码,在二进制翻译机制下运行在 %cpl = 1 ,没有限制。
二进制翻译引入了新的特别的挑战,是被翻译的代码包含混合了需要访问VMM区域(访问用来支持VMM的数据结构s)的指令和原始指令.解决方案是预留一个段寄存器,%gs ,用来始终指向VMM区域。二进制翻译器保证(在翻译时)没有虚拟机指令会直接使用 gs 前缀(gs prefix)。相反,翻译后的代码将 fs 寄存器用于最初具有 fs 或 gs 前缀的VM指令。
VMM截断段的方式是通过不改变基址减少段描述符 (segment descriptor)的范围,这会导致VMM必须在地址空间的最顶端区域。在他们的实现中,VMWare设置VMM的大小为 4MB 。该大小对于具有翻译缓存的VMM是足够的,并且其他数据结构足够大以适应VMM的工作集。
所有现代操作系统都使用虚拟内存 (virtual memory),它是抽象内存的一种机制。虚拟内存的好处包括能够使用超过实际内存大小的物理内存,并由于内存隔离而提高安全性。
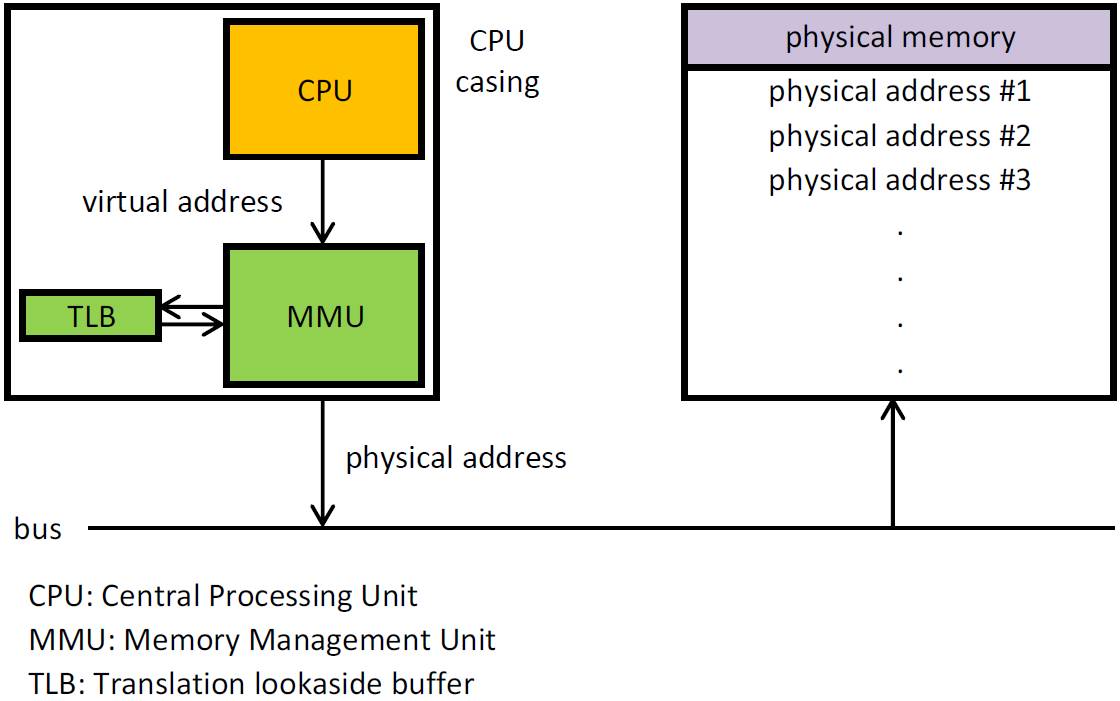
虚拟内存到物理内存的转换由名为页表 (Page Table)的查找表完成,这要归功于MMU (内存管理单元)。当我们尝试访问某些虚拟内存时,硬件页面遍历器遍历那些页表来将VA翻译为PA(physical address)物理地址。一旦计算出该转换结果,它就会缓存在成为TLB 的CPU缓存(CPU-cache)中。
如我们之前所看到的,我们不能让客户机弄坏硬件页表,所以,需要虚拟化对物理内存的访问。因此,地址转换变得有些不同,不再是从VA到PA,我们首先需要从 gVA 翻译成 gPA,之后从 gPA 翻译成机器物理地址(MPA),所以,(过程是) gVA ->gPA ->mPA。
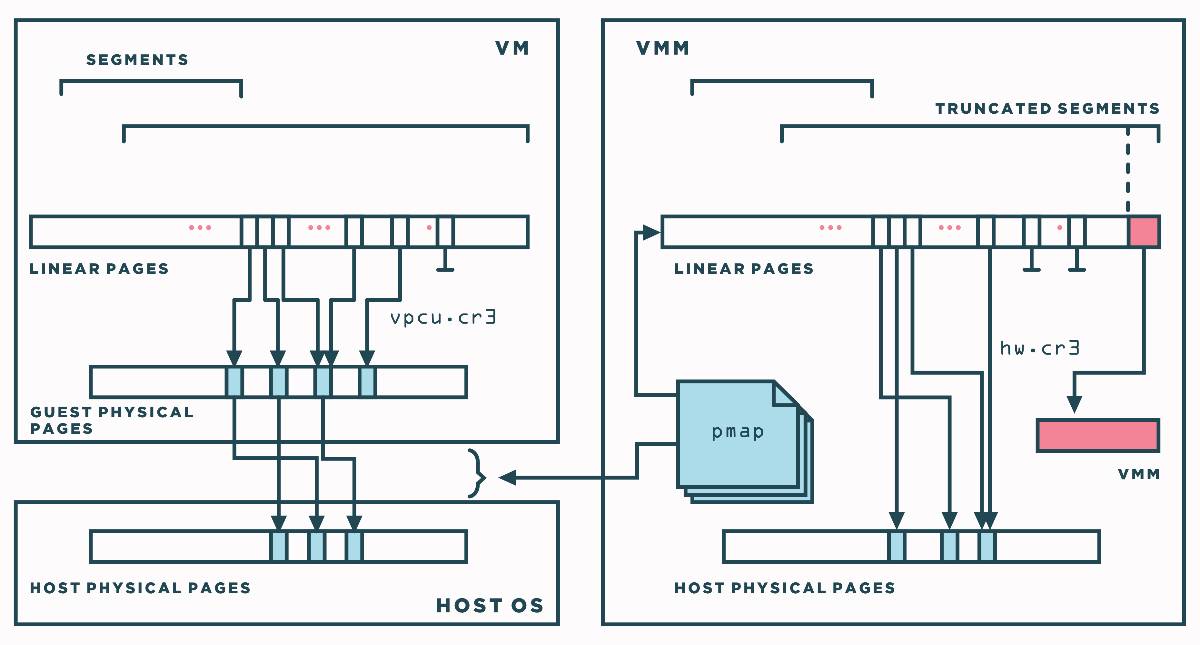
在虚拟机中,客户机操作系统自身像往常一样通过分段(受VMM的截断)和分页(通过以VM的%cr3 寄存器为根的页表结构)控制从客户机虚拟内存到客户机物理内存的映射。VMM通过名为影子页表 (shadow page tables)的技术,管理从客户机物理内存到机器物理内存的映射。
由于性能原因,更重要的是注意从gVA到mPA的组合映射基本上必须驻留在硬件TLB中。因为你不能是VMM干预每次内存访问,那样做会非常慢。该解决方案是通过将硬件页面遍历器(%cr3 )指向影子页表,影子页表是直接从 gVA 转换到 mPA 的数据结构。它的名字是因为它保持跟踪 (shadowing)就页表上客户机做的事情以及VMM从 gPA 到 mPA 翻译的内容。该数据结构必须由VMM主动维护和重新填充。
所以,当客户机尝试访问虚拟地址时,首先检查 TLB 是否已经有该VA的翻译,如果是,我们立刻返回其机器物理地址。然而,如果没有找到,硬件页面遍历器(指向影子页表)执行查找来获得 gPA 对应的 mPA,如果它得到对应的映射,它会填充 TLB,以便下一次访问。如果它没有在影子页表中找到底层映射,它会产生页面异常,VMM随后会通过软件 (in software)遍历客户机的页表以去顶 gPA 并返回 gPA。接下来,VMM使用 pmap (physical map,物理映射)结构确定 gPA 对应的 mPA 。通常,这一步很快,但首次触及它要求主机操作系统分配支持页面(backing page)。最后,VMM分配影子页表用来映射,并连接它到影子页表树。页错误和后续的影子页表更新类似于正常的 TLB 填充,因为他们对客户机不可见,所以它们被称为隐藏页面错误 (hidden page faults)。
隐藏(页面)错误的成本可能比TLB填充高1000倍,但往往但发生频率极低,因为更高的虚拟TLB容量(例如,更高的影子页表容量)。一旦客户机在影子页表中建立了工作集,内存访问就会以本地速度运行直到客户机切换到不同地址空间。x86 上的 TLB 语义要求上下文切换刷新 (flush) TLB(某些特权指令如 invlpg 或 mov %cr3 ),所以MMU必须抛掉影子页表并重新开始。我们说这样的MMU是非缓存的 (noncaching)。不幸的是,这会产生许多页面错误,这比 TLB 没命中(的代价)要昂贵的多。
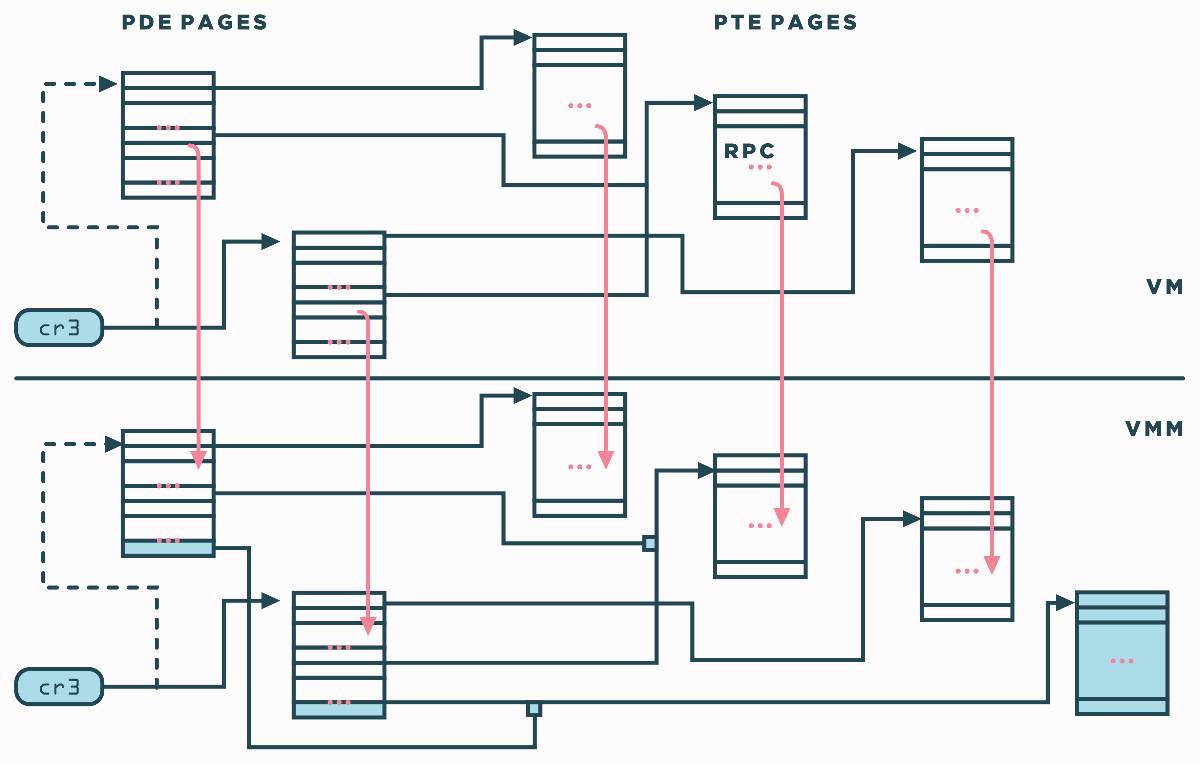
取而代之的是,VMM维护大的客户机操作系统的 pde/pte 页面的影子备份,如下图所示。通过在相应原始页面(客户机物理内存中)放置内存跟踪 (memory trace),VMM可以确保大量客户机 pde/pte 页面和VMM中它们的副本的一致性。这种影子页表的使用显著增加了虚拟机可用的有效页表映射的数量,即使在上下文切换后也是如此。
通过内存跟踪 (memory trace),我们指的是VMM在VM的任何给定物理页上设置读 或写 或读写跟踪和以透明的方式被通知所有对页面读和/或写的访问的能力。这不仅包括以二进制翻译或直接执行模式运行的VMM产生的访问,还包括VMM自身产生的访问。内存追踪对VM的执行是透明的,也就是说,虚拟机无法检测到追踪的存在。在构成pte时,VMM遵循如下的追踪设置:
由于可以在任何时候请求跟踪,所以当一个新的跟踪被放置后,系统使用后向机制(backmap mechanism)来降级 (downgrade)现有映射。由于权限降级,随后任何指令产生的对跟踪页面的访问会触发页面错误。VMM模拟该指令并告知请求模块关于访问的具体细节,如页内偏移的旧值和新值。
正如您可以概括的,该机制被VMM子系统使用来虚拟化MMU和段描述符表(接下来会看到的),以保证翻译缓存的一致性(更久一点后会看到),来保护虚拟机的BIOS ROM。
VMM不可以直接使用虚拟机的GDT和LDT,因为这会允许虚拟机控制底层机器。内存分段需要被虚拟化。和影子页表相似,称为影子描述符表 (shadow descriptor tables)的技术被用来虚拟化x86的分段体系结构。
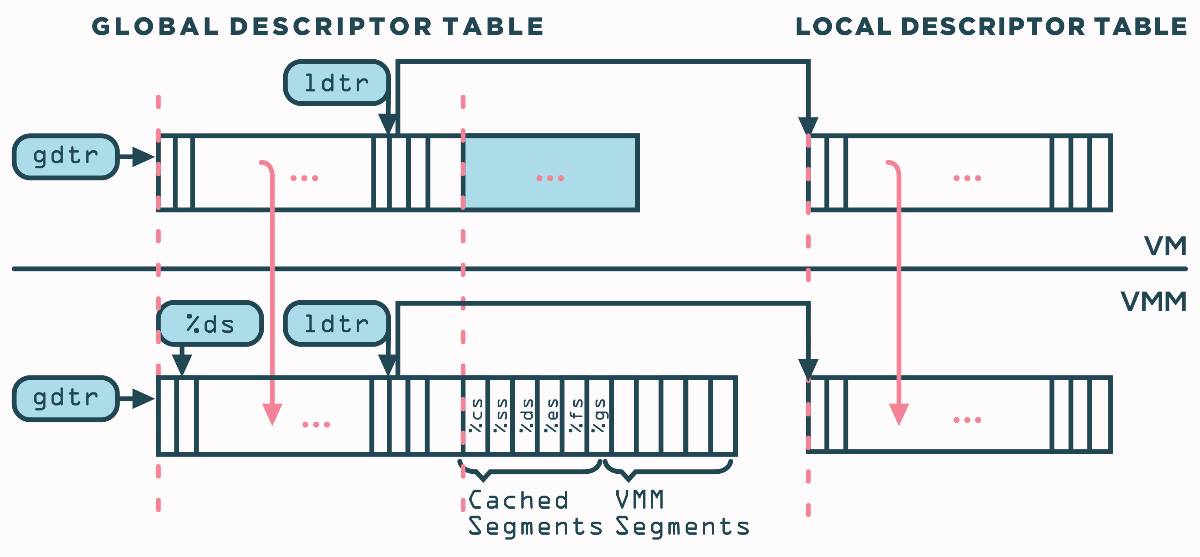
为了使VMM虚拟化现有系统,VMM设置硬件处理器的GDTR 的值为指向VMM的GDT。VMM的GDT被静态分区为三组条目:
VMM自身使用的vmm描述符 。
影子描述符 形成了VMM的GDT的下半部分和整个LDT。他们影(shadow)/复制并跟踪更改,VM中的GDT和LDT中的项具有以下条件:
六个缓存描述符 对应于vCPU中的段寄存器并被用来在软件中模拟vCPU隐藏部分的内容。类似于影子描述符,缓存描述符也被阶段并进行权限调整。而且,VMM需要在GDT中为自己保留一定数量的条目,这就是VMM描述符 (VMM descriptors)。
只要分段是可逆的 (reversible),影子描述符就被使用。这是直接执行的先决条件。如果处理器当前处于与段被加载时不同的模式,或者在保护模式下隐藏部分的段不同于当前对应描述符的内存区域的值时,该段被定义为不可逆的 (nonreversible)。当段变得不可逆,缓存描述符对应被使用的特定的段。缓存描述符也在保护模式中被使用,当特定描述符没有影子时。
另一个需要考虑的重点是,需要确保虚拟机不会(甚至是恶意的)加载VMM的段以供自己使用。这不是直接执行中要考虑的,因为所有的VMM段是 dpl ≤ 1 ,直接执行仅限于 %cpl = 3 。然而,在二进制翻译中,硬件保护不能用于 dpl = 1 的段描述符。因此,二进制翻译在所有段分配指令之前插入检查来确保只有影子项会被加载到CPU中。
与影子页表一样,内存跟踪机制包括一个段跟踪模块,该模块会将影子描述符和他们对应的VM段描述符比较,并指出影子描述符表和他们对应VM描述符表间的任何对应缺失,并更新影子描述符使他们对应他们各自对应的VM段描述符。
正如之前所提到的,VMM由直接执行子系统,动态二进制翻译器和决定适合使用DE或BT的决策系统组成。决策子系统进行了如下检查:
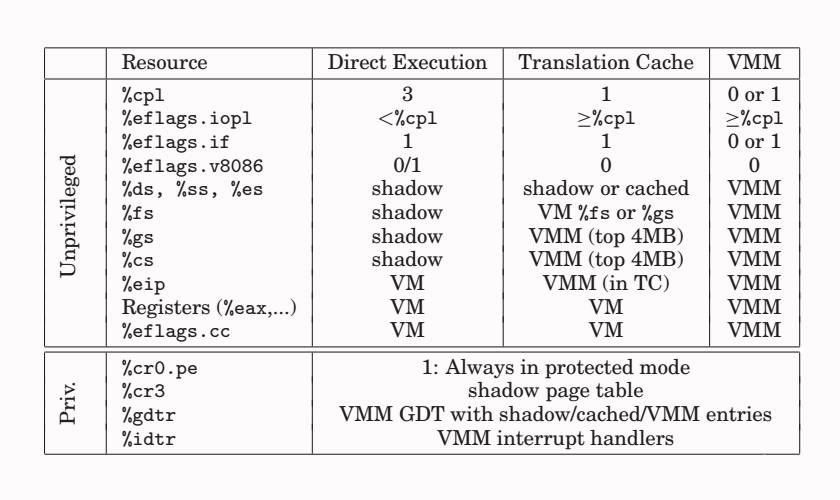
下表提供了当系统执行VM的指令、经过二进制翻译的指令或VMM自身时,硬件CPU怎样被配置的摘要视图。
当可以直接执行时,处理器的非特权态和虚拟状态相同 。这包括所有段寄存器(包括 %cpl ),所有的 %eflags 条件代码,和所有 %eflags 控制代码(%eflags.iopl ,%eflags.v8086 ,%eflags.if )。直接执行子系统的实现相对简单直接,VMM在内存中保留了一个数据结构,即vcpu,在操作系统中扮演着传统进程表入口的角色。该结构包含vCPU的状态,即非特权状态(通用寄存器,段描述符,条件标志,指令指针,段寄存器)和特权状态(控制寄存器,%idtr,%gdtr,%ldtr,中断控制标志等)。当恢复直接执行时,非特权状态被加载到真实CPU上。当触发陷阱时,VMM 在加载自身前首先保存非特权虚拟CPU状态。
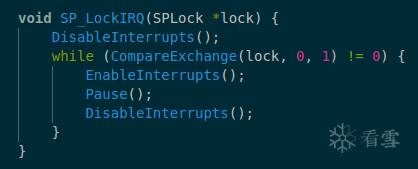
我们不会深入了解动态二进制翻译代码的细节,(尽管该部分)机制包含大约VMM所有代码的45%。我们只对得到大体的架构感兴趣。被称为二进制翻译 (Binary Translation),是因为输入x86 二进制 (binary)代码而不是简单的源代码,是动态的 (dynamic),是因为翻译发生在运行时。理解它的最好的方法是举个实例:
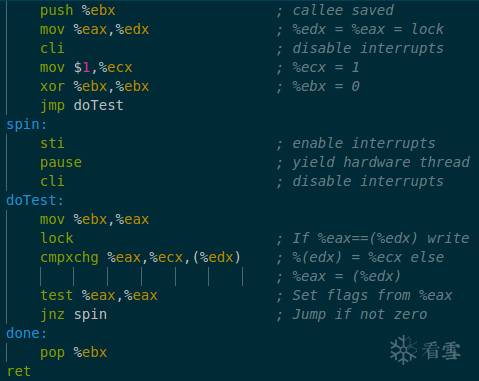
如果我们编译它,并反汇编代码,你会得到类似如下的东西:
一旦翻译器被调用,汇编代码的二进制表示作为输入进入它:53 89 c2 fa b9 01 00 00 00 31 db .... 。翻译器随后从每条指令中建立中间表示 (Intermediate Representation,IR)对象。翻译器将IR对象积累到翻译单元 (translation unit,TU)中,在满12条指令或终止指令处停止:通常像 jmp 或 call 的控制流指令,然后检查基本块 (Basic Block)。
当CPU处于二进制翻译模式时,他将vCPU的状态的一个子集加载到硬件CPU。这包括三个段寄存器(%ds,%es,%ss),所有通用寄存器,和标志寄存器(除了控制代码)。尽管段寄存器可以指向一个影子(shadow)或一个缓存项(cache entry),但底层描述符总是会指向预期的客户机定义的虚拟地址空间(尽管可能被截断)。其含义是只有在这三个段中的任何指令,通用寄存器,或任何条件代码才能硬件上以相同 (identically)的方式执行,而没有任何开销。这个含义实际上是VMWare二进制翻译器的一个中心点。
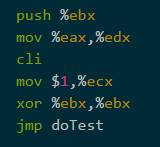
我们例子中的第一个TU是:
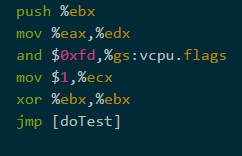
大多数代码何以被IDENT (identically,相同的)的翻译。push ,movs 和 xor 都属于这类。由于cli 是一个特权指令,它将中断标志设置为 0,所以它必须由VMM专门处理。你可以相同的方式翻译cli,这会导致VMM产生陷阱,之后VMM会模拟它。然而,不同的方式来翻译它来避免陷阱会有更好的性能。and $0xfd,%gs:vcpu.flags 。
由于翻译不会保留代码布局,因此最后的 jmp 必须是非 INDENT (non-IDENT)。相反,我们将它转换为两个翻译器调用的延续,一个是每个后继者(掉头和采取分支,fall-through和taken-branch),产生该翻译(方括号表示延续):
之后,VMM将执行以调用翻译器结束的代码区来产生 doTest 的翻译。其他的TU将会类似翻译。注意,VMWare二进制翻译器执行一些优化(不是在二进制级),如链接优化 (chaining optimization)和适应二进制翻译 (adaptive binary translation)的优化,其目的是减少陷阱的数量。我不会再深入,重点只是BT,我会留下足够的资源,如果你想更深的了解。
在本章中,你已经看到VMWare如何利用分段来保护VMM地址空间,如何影射(shadow)页表来虚拟化MMU的角色,以及段描述符是怎样用影子描述符表进行虚拟化。你也看到客户机用户模式应用时直接执行,没有虚拟化开销,以及客户机内核代码以在 ring 1 的二进制翻译代码运行。我希望你已经从中学到了一些东西。最后我要感谢引用中的白皮书的作者所做的出色工作。
原文链接:015K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6K6j5h3k6W2M7Y4N6S2L8r3I4Q4x3X3g2U0L8$3#2Q4x3V1k6T1L8r3!0Y4i4K6u0r3N6X3W2J5N6s2g2S2L8r3W2*7j5i4c8A6L8$3&6Q4x3X3c8A6L8Y4c8W2M7X3&6S2L8s2y4Q4x3X3c8H3j5i4u0@1i4K6u0V1x3W2)9J5k6s2k6E0N6$3q4J5k6g2)9J5k6r3q4F1k6q4)9J5k6s2k6A6M7Y4c8#2j5h3I4A6P5X3q4@1K9h3!0F1i4K6u0V1N6i4y4A6L8X3N6Q4x3X3c8T1K9h3&6S2M7Y4W2Q4x3X3c8@1M7X3q4F1M7$3I4S2N6r3W2G2L8R3`.`. sudozhange StrokMitream
[培训]科锐逆向工程师培训第53期2025年7月8日开班!
最后于 2018-7-5 19:39
被sudozhange编辑
,原因: 修正图片