阿特伍德定律指出,“任何可以用JavaScript来写的应用,最终都将用JavaScript来写”,5G的到来将导致大量的应用将不再native化,而从云端直接下载,JS作为与用户交互的入口大有一统所有编程语言的势头,很多大公司如华为正在为5G时代的大前端甚至物联网迫切需要的更高效的JS编译器进行超前的研发
248K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6%4N6%4N6Q4x3X3g2*7K9r3W2H3K9h3&6Q4x3X3g2U0L8$3#2Q4x3V1k6B7L8$3u0Q4y4h3k6V1k6i4c8S2K9h3I4Q4x3V1k6S2y4e0N6X3z5h3x3@1k6U0l9^5k6e0R3%4y4K6f1K6x3g2S2v1P5U0t1&6i4K6u0V1z5p5N6r3d9g2)9%4c8g2)9J5k6h3S2@1L8h3H3`.
。但JS表现出强大的统治力的同时,也面临着十分严峻的安全问题:代码直接暴露在浏览器中,因此对JS代码实施保护迫在眉睫。本文将从JS代码的混淆和反混淆两个方面,探讨JS代码的保护机制。
(一)JS代码保护若干技术难点
1.前端环境的复杂。以安卓端为例,不同版本的安卓系统,对webview的对JS代码调用逻辑也不同,给加密功能的开发带来很大挑战。
2.JS的标准在不停迭代。类似于python2,3的区别,JS也分成不同版本,保护方案如何能兼容不同的标准?
3.单线程与异步机制。尽管可以勉强实现前端的多线程,但是绝大部分情况下,浏览器内核单线程执行JS代码,异步编程给安全开发人员提出了新的难题
(二)调研和评估几种技术路线
我曾调研评估过以下几种可能的选择
1对安卓系统源码中对关键函数进行Hook,在JS文件加载前将其解密。虽然需要适配不同版本,但是有hook技术和源码研究的技术储备。
2类似之前分层加密引擎的加密方案
3走编译器路线,缺点是没有编译器经验,风险大
4找一个基于LLVM的JS的编译器parser,先将JS转成IR;接着用ollvm混淆后,再转回JS代码。但事实是,但调研后发现能把IR转JS,
JS貌似没法转IR。也找到一个,但是好像没有经过时间检验,不敢用。
5直接再开源项目JavascriptObfuscator基础上做二次开发。但是该工程入口代码被混淆,逻辑框架大量使用很吃经验的写法,还是typrscript。在当时没有足够JS代码经验的情况下,暂时降低该方案的优先级。
(三)如何确定方案
之前我曾和老领导一起实现过一个循环递归加密引擎,本质上是自己实现一个简化的编译器前端。后来老领导跳槽出去赚大钱了,我只能独自维护这个项目,越往后越发觉这个引擎适用的范围比较小。如果继续下去,必须写更详细的词法分析,这一之前被简化的部分现在是不得不正面硬刚。
新方案调研过程中,我自己看UglifyJS的AST遍历框架源码。当我看到当前字母是p时接下来要判断29种不同情况时,我突然意识这条路大反向可能是错的。如果仅仅是词法生成器阶段就有这么多种case要处理,后面如果再遇到更特殊的语法组织形式呢?和未知的问题呢?
我是第一次学JS,我的视野一定是不全面的,一定会遇到很多未知的问题。一旦出现问题我的方案有后路吗?大方向上能继续兼容其他方案吗?这个技术路线能覆盖多大的攻击面?我深感这方案没有任何退路可走。向前几乎无路可走,向后无路可退,总之在没深入了解掌握JS这门语言前,不能低估JS语法的复杂性和特殊性,想搞JS保护,首先要会写JS,不能用C来搞。
无论是继续之前的方案,还是未将来新方案做打算,我都需要引入成熟的编译器,这是目前我能选择的既能打好基础,又能兼顾未来新方案的选择。要扎实的稳健的推进,厚积薄发
为了解决这些问题,一方面,由于从未学过编译原理,我得在网上学习《编译原理》相关课程,但是学术界的课程真的适合实际工程吗?为了快速做出判断,我以快进方式学习2倍速快放,经过三天学习网课《编译原理》后,我得出了然并卵的结论。继续学下去只能纠结在无关的细节上。
另一方面,我开始自学JS,推荐学习网易云课堂《JavaScript前端开发》
同时我开始开始尽可能收集网上的UglifyJS的例子,看别人的代码能否有帮助。但是把全网找遍了发现居然没有多少能利用的样本。
半个月过去,3条路有2条是废了,除了继续学习JS外我无从做起,研发一筹莫展。这时,我的老领导突然发来一个链接,说她最近在做JS反混淆,这个链接也是关于反混淆的,也许对我有帮助。老领导出去赚大钱也不忘小弟我呀!我点进去一看,立即心花怒放,这是一篇从反混淆的角度运用编译器的案例,里面包含了一些语法树操作。即便不多,但我就像抓住救命稻草一样扑了上去,如饥似渴的吸收着。
老领导真是我的福星。看完这篇文章,深感编译器存在目的在于,将所有JS代码按照统一的形式:抽象语法树AST进行组织和操作。此时我无需纠结编译器如何将其组织起来,因为词法分析器已经写好,我现在要尽可能的归纳和总结,编译器的组织规则,试图“看到”内在的规则。前方的路仿佛种豁然开朗,必须马不停蹄的向前推进。
经过不断努力,我总算搞清楚了语法树的组织规则,总结就是,“自上而下,层层包裹”
什么意思?请看一个具体例子console.log(“hello world”);
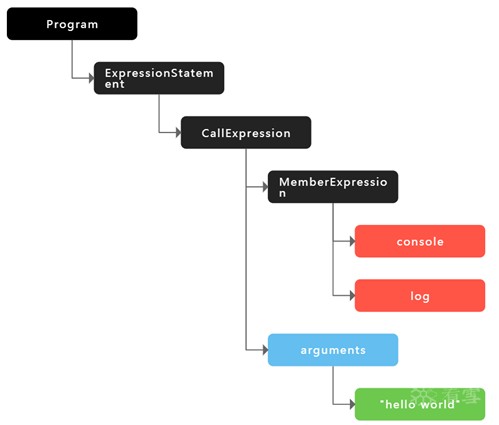
上图是这行代码的AST。我们看到,Program,ExpressionStatment,CallExpression是对这单行代码更上层的封装,而这句话这句话本身是一个CallExpression,他里面包含了MemberExpression以及arguments,分别对应了console.log和(“hello world”)
我们把所有的节点都详细打印出来,这里我使用的编译框架是esprima,大家可以选择uglifyjs等其他遍历工具。
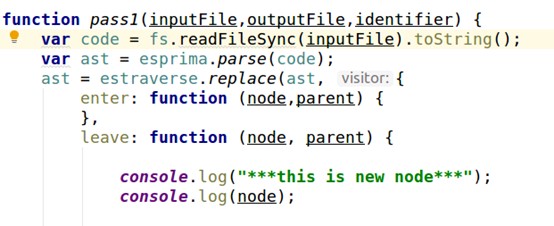
再看一下输出结果
打印出几个关键的节点
初看一定是懵逼的。如何研究呢?我们要仔细观察和总结不同类型节点,体会它表征特定的信息,以及遍历顺序,直到能“看到”数据流动的规律为止。这个过程中我们需要熟悉每一类节点定义,这需要我们去下载官方的文档,需要良好的英文阅读能力。还需要熟悉遍历顺序背后的逻辑,这需要我们精心构造各种样本,输入语法树遍历函数,自己归纳总结,找出背后的规律。
初步熟悉了AST后接下来我将选择3个混淆功能,从混淆以及反混淆两个方面,揭示JS代码保护以及破解的秘密。
(五)功能1:转义
转义是将对象的方法名转义。将形如console.log => console[log]。如何实现这一功能呢?
再把demo改成console[log],看看他的语法树长啥样,,依然是上面的代码
唯一的差别,就是”computed:true”和”computed:false”
安卓系统里,java层的每一个方法都对应着native层的一个结构体,一个著名的结构体,叫ArtMethod。熟悉hook框架的人一定不陌生。这个结构体是安卓6以上进行hook的关键,怎么hook呢?有将hook整体替换的,有把结构体里entryaddress里换掉自己定义的函数的,还有结构体什么都不改,直接把entryaddress指向的代码直接换掉的。总之就是一个字:换。
这里和hook框架的思路是一样的,也是换。我们要换掉的,是一个节点。怎么换?和hook框架一样,有部分换,有整体换。这里就是关键点了,和上图可视化的比较可知,我们的console.log是一个MemberExpression型结点。只要在遍历函数里找到这个类型的节点再进行等价替换就好了。
既然节点前后的差别只有”computed:true”和”computed:false”,那么是不是把这个属性的值换成true就可以呢?
但是怎么换呢?直接修改字段值可以吗?网上没有任何AST修剪案例,但是为什么不能多尝试几次呢?从对象里的几个属性开始,一个个尝试,观察结果,在不断失败中总能找到规律的!
经过尝试,基本找出了规律,以下是esprima框架下的核心代码:
结果是:
OK,这个功能基本开发完成。还剩屏蔽一些特殊情况了,想做成成熟的商业产品,你需要构造各种特殊的测视例子,去测试你的语法树变换后的代码能不能正常运行。测试例构造的越好,走的弯路就越少。
console[log]还可以等价变换为console[‘\x6c\x6f\x67’]
请注意,MemberExpression节点是如何定义的
[培训]内核驱动高级班,冲击BAT一流互联网大厂工作,每周日13:00-18:00直播授课




 如果你静心看完编译原理,后面你不用看那篇文章,自然就会想到用语法树了
如果你静心看完编译原理,后面你不用看那篇文章,自然就会想到用语法树了




