上篇笔记:https://bbs.kanxue.com/thread-281876.htm,整理了单步执行的基本原理,本篇记录调用栈的推导原理。
原理很简单,直接参考:Unwinding a Stack by Hand with Frame Pointers and ORC
关键要清楚一点,栈帧始终存在,只不过记录方式不同。
只要知道每个函数的栈桢大小,就可以根据最后一层函数的栈帧位置,逐层推导调用函数的栈帧,并不是必须,在每个函数入口,将调用函数的实际栈帧地址,保存到栈中。
不使用rbp记录栈帧的优点:
1. 每个函数入口,省掉了执行rbp入栈的指令,同时将rbp寄存器节约出来;
2. 基于rbp推导的调用栈,有些情况会不完整,参考:
消失的调用栈帧-基于fp的栈回溯原理解析
当没有了frame pointer我们该如何栈回溯?
3. 对于32位linux系统,个人认为还有一个原因,就是ebp寄存器,用于系统调用传参。
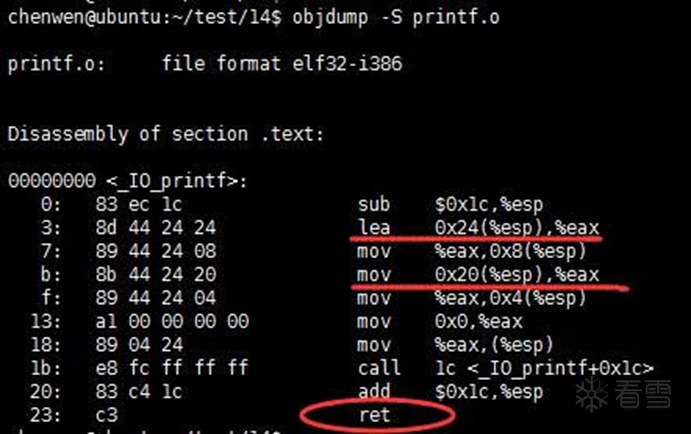
不如看一下32位glibc库函数:
ar -x /usr/lib64/libc.a objdump -S printf.o
可以看出,入口没有enter、返回值也没有leave,参数/局部变量根据esp寄存器的相对位置获取。
学习这些有什么用途?
分析vmcore、core文件时,有些情况crash、gdb解析不了参数或局部变量的值,需要人工去别的栈帧找:72eK9s2c8@1M7q4)9K6b7g2)9J5c8W2)9J5c8X3u0D9L8$3N6Q4x3X3g2U0K9r3W2F1j5i4g2F1K9i4S2Q4x3X3g2F1k6i4c8Q4x3V1k6#2K9h3c8Q4x3X3b7I4y4o6f1J5z5o6R3J5x3#2)9J5k6r3W2V1i4K6u0V1y4o6x3#2z5o6M7^5y4g2)9J5k6h3S2@1L8h3H3`.
[培训]科锐逆向工程师培训第53期2025年7月8日开班!
7f2K9s2c8@1M7s2y4Q4x3@1q4Q4x3V1k6Q4x3V1k6T1L8r3!0Y4i4K6u0W2N6r3q4J5N6r3q4F1L8r3I4S2L8h3q4Q4x3X3g2^5P5i4A6Q4x3V1k6%4M7X3W2@1K9h3&6Y4i4K6u0V1j5g2)9J5k6r3I4A6L8Y4g2^5i4K6u0V1k6r3g2T1N6h3N6Y4k6i4u0Q4x3X3c8K6k6i4c8#2M7q4)9J5c8R3`.`.